Alita-G: Self-Evolving Generative Agent for Agent Generation
Abstract: LLMs have been shown to perform better when scaffolded into agents with memory, tools, and feedback. Beyond this, self-evolving agents have emerged, but current work largely limits adaptation to prompt rewriting or failure retries. Therefore, we present ALITA-G, a self-evolution framework that transforms a general-purpose agent into a domain expert by systematically generating, abstracting, and curating Model Context Protocol (MCP) tools. In this framework, a generalist agent executes a curated suite of target-domain tasks and synthesizes candidate MCPs from successful trajectories. These are then abstracted to parameterized primitives and consolidated into an MCP Box. At inference time, ALITA-G performs retrieval-augmented MCP selection with the help of each tool's descriptions and use cases, before executing an agent equipped with the MCP Executor. Across several benchmarks GAIA, PathVQA, and Humanity's Last Exam, ALITA-G attains strong gains while reducing computation costs. On GAIA validation, it achieves 83.03% pass@1 and 89.09% pass@3, establishing a new state-of-the-art result while reducing mean tokens per example by approximately 15% relative to a strong baseline agent. ALITA-G thus provides a principled pathway from generalist capability to reusable, domain-specific competence, improving both accuracy and efficiency on complex reasoning tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
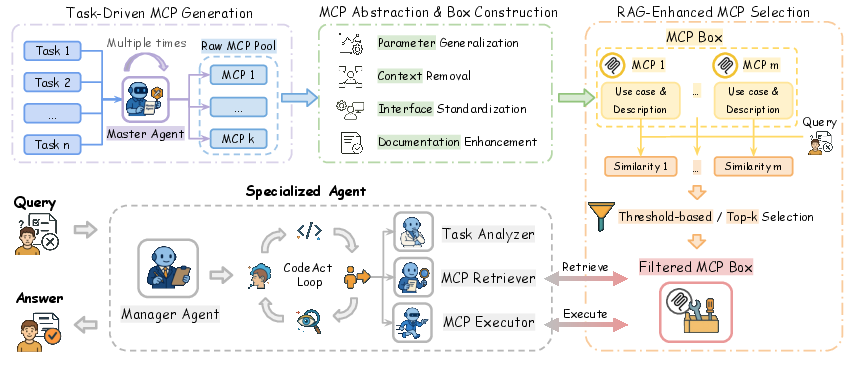
This paper introduces Alita-G, a smart system that helps AI “agents” learn and improve themselves. Instead of just rewriting prompts or trying again when they fail, Alita-G teaches a general AI how to become a domain expert (like a specialist in medical questions or science tasks) by creating and organizing reusable tools. These tools are called MCP tools and they live in a shared “MCP Box” the agent can search and use when solving new problems.
What is the paper trying to do?
The main goals are:
- Turn a general AI agent into a specialist for a specific area (like medical images or science research).
- Do this by letting the agent build its own set of helpful tools from tasks it already solved.
- Make the agent faster and more accurate by choosing the right tools at the right time.
In simple terms: Alita-G helps an AI create a toolbox from past successes, organize that toolbox, and then pick the best tools for new challenges.
How does it work? (Methods and key ideas)
Here are the main steps, explained in everyday language:
- An AI agent tries lots of tasks in a target area (for example, answering science questions).
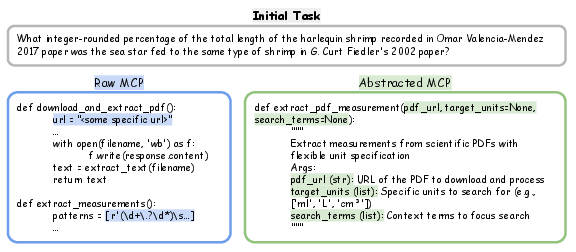
- When the agent figures something out, it doesn’t just give the answer — it also creates a small reusable “tool” that captures the trick it used. These tools follow a standard format called MCP (Model Context Protocol). Think of MCP tools like mini apps with a clear description, inputs, and outputs.
- The system then “cleans up” those tools:
- It replaces hard-coded values with adjustable inputs (so the tool works in more situations).
- It removes details that only applied to one task.
- It standardizes the interface so any agent can use the tool.
- It writes simple documentation so future users know what the tool does.
- All these polished tools are saved into an organized “MCP Box” — basically a toolbox of ready-to-use skills.
- When facing a new task, the agent doesn’t blindly try everything. It uses a retrieval method (similar to searching a library) called RAG to pick the most relevant tools based on the task description and tool descriptions/use cases. It can select:
- Tools above a similarity threshold (only pick tools that seem relevant enough), or
- The top-k most similar tools (always pick the top few).
- The agent then runs with these selected tools and solves the task more efficiently.
Simple analogy: Imagine you’re learning math. Every time you solve a problem, you write a short “recipe” for how you did it. Later, you collect those recipes into a notebook (your MCP Box). When you get a new problem, you search your notebook for the most similar recipe and follow it. Over time, your notebook grows, and you solve problems faster and better.
Explaining a few technical terms
- Agent: An AI system that plans steps, uses tools, and reasons to solve tasks.
- MCP tool: A small, well-defined function or skill the agent can call (like “extract measurements from a PDF”).
- MCP Box: The collection of all the useful MCP tools the agent has built.
- RAG (Retrieval-Augmented Generation): A method where the agent searches for relevant info/tools before generating an answer.
- Embedding and similarity: Ways to turn text into numbers so the system can compare how alike a task and a tool description are.
- pass@1 / pass@3: Accuracy measured by whether the agent gets the correct answer in 1 try or in up to 3 tries.
- Tokens: Roughly the chunks of text the AI reads/writes; fewer tokens usually means lower cost and faster responses.
What did they find? (Main results)
The authors tested Alita-G on three benchmarks:
- GAIA: Real-world assistant tasks that often need web browsing and multi-step reasoning.
- PathVQA: Medical questions about pathology images.
- Humanity’s Last Exam (HLE): Hard reasoning questions.
Key findings:
- Alita-G set a new state-of-the-art on GAIA validation: about 83% correct on the first try (pass@1) and about 89% correct with up to 3 tries (pass@3).
- It reduced the amount of text the system had to process (tokens) by around 15% compared to a strong baseline. This means it’s more efficient and cheaper to run.
- Running more “generations” (letting the agent create tools over multiple passes) made the MCP Box richer and improved accuracy — especially going from 1 to 3 rounds. After that, returns started to level off.
- Using both tool descriptions and their use cases together for RAG selection works best. It helps the agent pick the most relevant tools for each task.
- Better embedding models (for comparing task and tool text) led to better performance. In short, good search → better tools picked → better answers.
Why is this important? (Implications and impact)
Alita-G shows a practical way for AI agents to “evolve” on their own:
- Instead of only learning from mistakes or changing prompts, the agent builds real, reusable capabilities.
- It becomes a domain specialist by collecting and organizing the right tools — just like a student making a great set of study guides.
- This improves accuracy and speed on complex, real-world tasks.
- The approach could help AI systems become more reliable in fields like healthcare, research, education, and technical support, because they can reuse proven tools and avoid wasting effort.
- It also points to a future where AI agents can build and share toolboxes, making it easier to create specialized AI without heavy manual setup.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- MCP validation and correctness: The framework lacks an automated test harness (unit tests, type checks, static analysis, runtime guards) to verify that LLM-abstracted MCPs are functionally correct and safe before inclusion in the MCP Box.
- MCP harvesting criteria: MCPs are collected only from “successful” runs (final answer equals ground truth), potentially discarding useful sub-tools from near-miss trajectories; alternative harvesting criteria and value attribution for partial successes remain unexplored.
- Redundancy management: The MCP Box accumulates substantial redundancy with growth (similarity and cluster trends), but no principled deduplication, merging, or canonicalization strategy is provided to maintain coverage while reducing overlap.
- Learned retrieval vs. cosine similarity: MCP selection uses fixed embeddings and cosine similarity over description/use-case text; end-to-end learned retrieval (task-conditioned or RL-trained selectors) and hybrid symbolic/semantic selectors are not investigated.
- Dynamic selection policies: Threshold τ=0.7 and top-k policies are hand-tuned on a small subset; adaptive, query-dependent policies (e.g., cost-aware selection, uncertainty-aware dynamic k/τ, curriculum-based selection) are not explored.
- Tool orchestration strategy: When multiple MCPs are selected, the paper does not specify contention resolution, ordering, and composition policies; learning to schedule/compose tools optimally (and detect conflicting tools) is an open problem.
- Abstraction reliability: LLM-driven “parameter generalization” and “context removal” may introduce silent bugs; formal specifications, contracts, and post-abstraction equivalence checks are not provided.
- Versioning and lifecycle: Procedures for MCP versioning, deprecation, update propagation, and rollback are undefined; governance of the MCP Box (provenance, change logs, compliance) remains an open question.
- Failure handling and fallback: The agent’s behavior when retrieval selects no relevant MCPs or selected MCPs fail at runtime (timeouts, exceptions, missing dependencies) is not defined; robust fallback strategies are needed.
- Scalability limits: The paper does not quantify memory footprint, index size, and retrieval latency as MCP Box scales beyond ~128 MCPs, nor propose compression, clustering, or tiered indexing to control inference-time overhead.
- Compute and cost reporting: Efficiency is measured only via token counts; wall-clock latency, GPU hours, monetary costs, and energy consumption—especially for K multi-executions and abstraction runs—are not reported.
- Statistical rigor: No confidence intervals, variance across seeds, significance tests, or repeated runs are provided; robustness of improvements and sensitivity to randomness remain unclear.
- Domain coverage metrics: There is no measurement of tool-level coverage across a domain taxonomy (e.g., GAIA skill categories); methods to detect coverage gaps and prioritize generation are not addressed.
- Cross-domain transfer and interference: Whether a specialized agent retains generalist performance outside its domain, or suffers negative transfer/interference, is not evaluated.
- Generalization to new tasks within domain: The framework does not test zero-shot generalization to unseen but related tasks in the same domain, especially tasks requiring novel tool compositions.
- Multi-modal pipeline clarity: PathVQA and HLE require vision/multi-modal capabilities, but the paper does not detail image handling, OCR, vision models/tools, or the role of MCPs in multi-modal reasoning; ablations on visual components are missing.
- Dataset scale and sampling: PathVQA and HLE evaluations use 100 sampled examples without stratified sampling details or full-dataset results; representativeness, sampling bias, and robustness across the full distributions remain unresolved.
- GAIA evaluation scope: Claims are on GAIA validation only; test-set results and leaderboard-compliant protocols (timestamped browsing, anti-leak setups) are absent, leaving external validity uncertain.
- Data contamination checks: Procedures to prevent training or tool contamination (e.g., MCPs embedding answers, cached web content leakage) are not detailed; rigorous anti-leak audits are needed.
- Security and safety: No red-team testing for tool misuse, prompt injection, model hijacking via MCP metadata, or unsafe external calls; security hardening and sandboxing policies for MCP execution are not evaluated.
- Privacy implications: The paper does not address privacy risks of MCPs that access external data sources; auditing, PII handling, and compliance frameworks are missing.
- Base-model dependence: Results rely on proprietary LLMs (Claude-Sonnet-4, GPT-4.1) and OpenAI embeddings; reproducibility with open-weight models, smaller models, and mixed stacks is not explored.
- Memory integration: The agent’s long-term memory and its interaction with MCP retrieval (e.g., caching past MCP successes, episodic memory for tool usefulness) are not specified or ablated.
- Stopping criteria for K: Beyond empirical diminishing returns, there is no principled stopping rule for the number of generation iterations (K), nor metrics to detect when further runs add mostly duplicates.
- Learning the evolution process: There is no algorithmic or theoretical framework guiding convergence of self-evolution (e.g., sample efficiency bounds, conditions for monotonic improvement, or guarantees against regressions).
- Tool composition learning: Methods to learn reusable higher-order macros or workflows (composed MCP sequences) are not investigated, despite multi-step tasks benefiting from learned compositions.
- MCP metadata quality: The quality and consistency of descriptions/use-cases (used for retrieval) are not audited; automated metadata normalization and enrichment pipelines remain unaddressed.
- Adaptive thresholds across domains: The optimal τ varies by domain and task difficulty; a principled method to tune and transfer thresholds across domains (or self-tune online) is missing.
- Explainability: The paper does not analyze how selected MCPs drive improvements (e.g., attribution, tool-level Shapley values, interpretable selection rationales), limiting actionable understanding of what works.
- Release and reproducibility: Code, MCP Box artifacts, and evaluation harnesses (including browser settings, tool configs) are not described as publicly available; exact replication instructions are absent.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, mapped to sectors and paired with potential tools/products/workflows and key assumptions or dependencies.
- Software and developer productivity: turn ad‑hoc agent trajectories and internal scripts into reusable, parameterized FastMCP tools via an “MCP Box Builder” workflow (multi‑execution harvest → abstraction → RAG selection); potential product: MCP Box Studio integrated with CI/CD; dependencies: reliable master agent, FastMCP runtime, secure code execution sandbox, high‑quality metadata for descriptions/use cases, robust embedding model.
- Research and academia: automated literature‑to‑tool pipelines for extracting measurements, tables, and facts from PDFs (as in the paper’s case study), enabling repeatable meta‑analyses and data synthesis; potential workflow: “Literature MCPs” curated per field (biology, materials science); dependencies: access to PDFs, PDF parsers, domain prompts, human validation for accuracy.
- Healthcare (clinical ops and informatics): pathology visual QA assistants specialized on PathVQA‑like tasks for triage, QA, and education; potential tools: image captioning/QA MCPs, guideline retrieval MCPs; dependencies: HIPAA/PII compliance, de‑identification, integration with PACS/EHR, clinically validated models, human‑in‑the‑loop sign‑off.
- Customer support and knowledge operations: domain‑specific helpdesk agents with curated MCPs for ticket triage, log parsing, product diagnostics, and knowledge base retrieval; potential product: “Support MCP Box” with threshold‑based selection to cut latency and token spend; dependencies: KB connectors, observability/telemetry, access controls, tool security scanning.
- Finance (operations and compliance): regulatory filing and KYC/AML extraction agents that transform successful trajectories into document structuring MCPs; potential workflow: “Filings MCP Box” for SEC/EDGAR, bank statements, KYC forms; dependencies: compliance and auditability, data privacy, robust document OCR, high‑precision retrieval.
- Education (tutoring and assessment): course‑specific tutoring agents that generate MCPs for common problem archetypes (math proofs, physics derivations, code exercises), aligned with HLE‑style reasoning; potential product: “Course MCP Kits” per syllabus; dependencies: up‑to‑date materials, academic integrity guardrails, teacher oversight, content licensing.
- Energy and industrial operations: maintenance documentation assistants that curate MCPs for BOM queries, metric extraction, SCADA log parsing; potential product: “Ops MCP Box” with on‑prem FastMCP executors; dependencies: ICS/OT security, network segmentation, vendor API connectors, offline/edge runtime.
- Data analytics and BI: auto‑ETL MCP Boxes for schema‑aware SQL generation, report building, and KPI checks; potential workflow: “Analytics MCP RAG” integrated with warehouse metadata; dependencies: database access, schema catalogs, change management, lineage tracking.
- Web research and competitive intelligence: enterprise research agents with curated browsing/parsing MCPs to standardize web data collection while cutting tokens ≈15%; potential product: “Research Agent Factory” with RAG tuners; dependencies: API quotas, robots.txt/TOS compliance, content licensing, anti‑scraping defenses.
- MLOps/AgentOps: self‑evolution orchestrator that continuously runs multi‑execution harvests, abstracts MCPs, and A/B tests threshold vs. top‑k selection; potential product: “Agent Specialization Factory” with dashboards for pass@1/pass@3, token costs, wrong→right flips; dependencies: compute budget, evaluation sets, telemetry, embedding model selection.
- Marketplace/platform (internal): an MCP registry for reusable, versioned tools across teams, with metadata search and security scans; potential product: “MCP Registry & Governance”; dependencies: IP policy, supply‑chain security (SBOM), versioning, ownership and review workflows.
- Daily life (personal productivity): specialized agents for travel planning and shopping using curated MCPs for fare scraping, availability checks, and budget analysis; potential product: “Personal MCP Box” with threshold‑based selection; dependencies: provider TOS, account/API access, privacy controls, ongoing maintenance of MCPs as sites change.
Long-Term Applications
The following applications require further research, scaling, validation, or integration in regulated/high‑stakes environments.
- Autonomous enterprise specialization‑as‑a‑service: end‑to‑end platform that evolves department‑specific agents (finance, legal, ops) from generalists; potential products: Agent Specialization Factory + MCP Governance; dependencies: organizational change management, RBAC/Policy, SOC2/ISO compliance, continuous evaluation.
- Regulated healthcare (clinical decision support): MCP‑curated agents assisting diagnosis and treatment planning (radiology, pathology, cardiology) beyond QA; potential product: “Clinical MCP Suite” with audit trails; dependencies: clinical trials, regulatory approval (FDA/CE), bias/safety validation, strict data governance, human oversight.
- Robotics and embodied AI: turn MCP abstractions into robot “skills” (tool use → action primitives) selected via RAG for task‑conditioned execution; potential product: “Skill MCP Box” bridging perception, planning, and control; dependencies: reliable perception pipelines, sim‑to‑real transfer, safety certification, low‑latency on‑device executors.
- Government and policy analysis: evolving legislative/research assistants that continuously curate MCPs for statutory extraction, impact modeling, and stakeholder mapping; potential product: “Policy MCP Lab”; dependencies: public data access, provenance tracking, transparency/interpretability, oversight and accountability frameworks.
- Financial risk management and audit automation: MCP Boxes for internal controls testing, audit trail generation, scenario analysis; potential product: “Risk MCP Governance”; dependencies: model risk management, explainability, regulatory alignment (Basel/SEC), formal validation of tool behavior.
- Scientific discovery pipelines: lab agents that harvest MCPs from experimental logs (instrument control, data cleaning, curve fitting), enabling reproducible, shareable toolchains; potential product: “Lab MCP Studio” integrated with ELNs/LIMS; dependencies: instrument APIs, standardization of metadata, reproducibility audits.
- Cross‑org MCP marketplace: ecosystems for sharing vetted MCPs across companies and academia with licensing, verification, and reputation; potential product: “MCP Exchange”; dependencies: standardization (FastMCP or successor), IP/licensing frameworks, supply‑chain security, curation quality.
- Tool safety and formal assurance: static/dynamic analysis, sandboxing, and formal verification for MCP code to prevent misuse and vulnerabilities; potential product: “MCP Guardian” (as hinted by related work); dependencies: language/tooling support for verification, sandbox performance, red‑team testing, incident response.
- Multi‑modal expansions: broader incorporation of vision, audio, and structured sensor streams (beyond PathVQA) with MCPs that unify inputs and actions; potential product: “Multimodal MCP Executor”; dependencies: high‑quality multimodal encoders, latency/throughput constraints, dataset coverage.
- Edge/on‑prem execution: hardened FastMCP executors running in air‑gapped environments for industrial and government use; dependencies: deployment tooling, hardware constraints, offline RAG indexes, security accreditation.
- Education at scale: institution‑level agents that auto‑generate course‑specific MCP Boxes, align to learning outcomes, and provide formative feedback; dependencies: fairness/bias audits, privacy protections for students, alignment with accreditation standards, robust content governance.
- Energy and sustainability: grid and plant optimization agents that curate MCPs for forecasting, dispatch planning, and maintenance scheduling; potential product: “Grid MCP Ops”; dependencies: integration with SCADA/EMS, regulator buy‑in, safety constraints, rigorous backtesting.
Glossary
- Ablation: An experimental method that removes or varies components to assess their impact on performance. "Detailed ablations and analyses confirmed the necessity of each component"
- Agentic system: A system design where an LLM is embedded within an agent that plans, uses tools, and iterates via feedback. "recent work has constructed agentic systems around LLMs that decompose tasks, orchestrate tools, and iterate via feedback"
- CodeAct loop: An iterative cycle where an agent reasons, selects tools, executes them, and updates context to solve tasks. "runs a CodeAct loop to retrieve and invoke the selected MCPs"
- Connected components: Disjoint subsets of nodes in a graph where each node is reachable from any other within the same subset. "the number of connected components when linking MCP pairs with similarity "
- Cosine similarity: A similarity metric measuring the cosine of the angle between two vectors, often used for comparing embeddings. "computed using cosine similarity:"
- Embedding encoder: A model that converts text into vector representations (embeddings) for similarity and retrieval. "We evaluate the impact of different embedding encoders on the RAG-based MCP selection mechanism."
- FastMCP: A high-performance implementation of the Model Context Protocol providing optimized runtime for tool integration. "Ensure compatibility with FastMCP~\citep{fastmcp2024} protocol specifications"
- GAIA (benchmark): A real-world, multi-level benchmark for agents involving web browsing, tool use, and reasoning. "On the challenging GAIA benchmark, our method achieves pass@1"
- Humanity's Last Exam (HLE): A challenging academic benchmark emphasizing complex, often multi-modal reasoning. "The Humanity's Last Exam (HLE) is a challenging academic benchmark"
- L2 normalization (ℓ2-normalization): Scaling a vector so its Euclidean (ℓ2) norm equals one. "and -normalizing the embedding."
- LLM: A neural LLM with billions of parameters capable of general-purpose text understanding and generation. "LLMs have demonstrated strong performance across a wide range of tasks"
- MCP (Model Context Protocol): A standardized interface for connecting agents to external tools and data sources. "Model Context Protocol (MCP) has emerged as a standardized framework for enabling seamless integration between AI systems and external tools or data sources."
- MCP Box: A curated repository of reusable MCP tools distilled and abstracted from successful task executions. "build domain-specific MCP repositories, referred to as MCP Box."
- MCP Executor: The runtime component that invokes MCP tools with standardized interfaces during inference. "equipped with the MCP Executor."
- MCP Retriever: The module that selects relevant MCPs for a task via retrieval mechanisms. "a Manager Agent with a Task Analyzer, MCP Retriever, and MCP Executor"
- Non-parametric component optimization: Improvements that change system behavior without altering model parameters (e.g., tool or component updates). "ranging from parametric updates to non-parametric component optimization."
- Parametric knowledge: Information encoded directly in a model’s parameters, as opposed to external tools or memory. "mitigates the limitations of its parametric knowledge"
- pass@1: A metric indicating the accuracy under a single attempt; commonly used with pass@k for k attempts. "it achieves pass@1 and pass@3"
- Reasoning trajectory: The sequence of intermediate thoughts, actions, and observations produced during task solving. "produces a reasoning trajectory:"
- Retrieval-augmented generation (RAG): A paradigm where a model retrieves relevant information (or tools) before or during generation to improve accuracy. "We are the first to couple MCP abstraction with MCP-level retrieval-augmented generation (RAG) in a single framework."
- Sample efficiency: The ability to achieve strong performance using fewer examples or computational resources. "improves transfer and sample efficiency within that domain"
- Self-evolution: An agent’s capability to autonomously improve by leveraging past executions, feedback, and self-generated artifacts. "we define a new paradigm of self-evolution"
- Semantic embeddings: Vector representations capturing the meaning of text for similarity and retrieval tasks. "we compute semantic embeddings for both the query and all MCP contexts"
- State-of-the-art (SOTA): The best known performance on a benchmark at the time of reporting. "establishing a new state-of-the-art performance."
- Threshold-based selection: A retrieval method that includes items whose similarity scores exceed a specified threshold. "Threshold-based Selection: We select MCPs whose relevance scores exceed a predefined threshold :"
- Top-k selection: A retrieval method that returns the k highest-scoring items regardless of absolute score. "Top-k Selection: Alternatively, we select the MCPs with the highest relevance scores:"
- Undirected similarity graph: A graph where nodes are items (e.g., MCPs) and edges connect sufficiently similar pairs, without edge direction. "we build an undirected similarity graph whose vertices are MCPs"
Collections
Sign up for free to add this paper to one or more collections.