- The paper introduces UGCS, a method leveraging per-sample uncertainty to select high-performing RL finetuning checkpoints.
- It utilizes average negative log-likelihood on challenging samples to gauge checkpoint quality without extensive validation.
- Experimental results demonstrate up to 7.5% accuracy gains on AMC 2023, underlining UGCS's potential to enhance LLM generalization.
Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of LLMs
Introduction
The research article "Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of LLMs" (2511.09864) tackles the challenge of checkpoint selection in reinforcement learning (RL) finetuning of LLMs. RL finetuning aims to refine LLMs by aligning them with human feedback, enhancing their reasoning capabilities through verifiable reward signals. However, RL finetuning is inherently unstable, leading to checkpoints with varying generalization performance. Existing strategies for checkpoint selection, like validation performance evaluation, are costly and impractical under certain constraints, such as the unavailability of suitable validation sets. This paper introduces Uncertainty-Guided Checkpoint Selection (UGCS), a novel method leveraging the uncertainty of model predictions to identify checkpoints that are likely to generalize well. Distinctly, UGCS circumvents the computational expenses associated with exhaustive validation, offering an efficient mechanism based on metrics derived directly from training data.
Methodology
UGCS focuses on per-sample uncertainty as an indicator of checkpoint quality during RL training. The core premise is that model uncertainty, captured as average negative log-likelihood (ANLL) of outputs, provides a more robust measure of sample difficulty than conventional accuracy or reward metrics. The method involves selecting checkpoints based on their performance on the most challenging samples identified within a short window of recent training steps. This window aggregates rewards on the top-p% most uncertain samples, thus emphasizing samples that require complex reasoning.
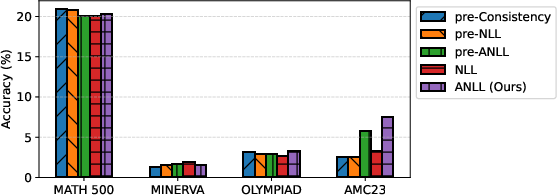
Figure 1: Mean Accuracy across datasets for different difficulty metrics on Qwen2.5-0.5B and GSM8K training.
Experimental Results
The paper evaluates UGCS using several LLMs—Qwen2.5-0.5B-Instruct, Falcon3-1B-Instruct, and Qwen3-0.6B—across diverse mathematical reasoning datasets including GSM8K, DeepScaleR, and GSM-symbolic. The models were assessed on benchmarks like MATH-500, Minerva Math, OlympiadBench, and AMC 2023. UGCS consistently identified checkpoints that outperformed other selection methods, notably achieving gains in accuracy of up to 7.5% on AMC 2023 dataset evaluations, especially for models demonstrating high variance. UGCS's simplicity and efficiency make it particularly advantageous compared to validation-based selection methods which rely on costly inference on held-out data.
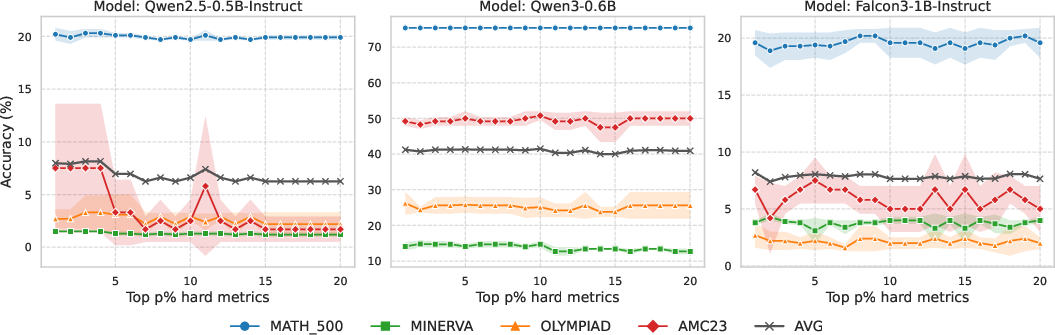
Figure 2: Results on GSM8K training when adjusting p for various models and datasets. For each model, AVG denotes the average accuracy over four datasets, while the others (with shaded ranges) represent individual datasets with their standard deviations.
Implications and Future Work
The introduction of UGCS offers a significant advancement in RL finetuning practices for LLMs, providing a practical framework that is efficient without sacrificing model performance. The research underscores the importance of adaptive uncertainty measures in enhancing model generalization, paving the way for further exploration of uncertainty-based metrics in diverse learning scenarios. Future work could extend UGCS to other domains where sample complexity is pivotal or integrate dynamic difficulty adaptation mechanisms more thoroughly with RL training protocols. This could potentially include hybrid approaches that combine uncertainty-guided measures with task-specific evaluations to refine checkpoint selection further.
Conclusion
UGCS emerges as a robust and efficient method for selecting high-performing checkpoints during RL finetuning of LLMs, effectively unifying computational efficiency with strong generalization. By capitalizing on per-sample uncertainty and focusing on challenging evaluation cases, UGCS not only simplifies checkpoint selection but also aligns closely with the overarching goals of robust and scalable LLM training protocols. Its validation-free design renders it remarkably efficient, representing a promising direction for future research in model training stabilization and generalization enhancement.