- The paper introduces UBench as a novel benchmark that systematically evaluates LLM uncertainty using 3,978 multiple-choice questions across four domains.
- The methodology categorizes questions into Knowledge, Language, Understanding, and Reasoning while employing calibration metrics such as ECE, ACE, MCE, and TACE.
- The findings highlight significant gaps in LLM reliability and suggest that optimizing prompt engineering and parameter settings can improve confidence calibration.
UBench: Benchmarking Uncertainty in LLMs with Multiple Choice Questions
The paper "UBench: Benchmarking Uncertainty in LLMs with Multiple Choice Questions" presents a systematic approach to evaluating the uncertainty in LLMs using a novel benchmark, UBench, composed of multiple-choice questions. The document provides a detailed discussion on the development and application of UBench as a state-of-the-art solution for assessing LLM reliability, focusing on the calibration of their response confidence.
Introduction to UBench
The development of LLMs has improved tremendously, with models like GPT-4, Llama, and ChatGLM demonstrating strong capabilities in tasks such as conversation and code generation. Despite their functional strengths, LLMs often lack interpretability and can produce unreliable outputs, such as hallucinations and biased responses, without indicating confidence levels. This paper addresses the need for reliable benchmarks that extend beyond mere accuracy to consider uncertainty in LLMs' responses.
UBench, a comprehensive benchmarking tool, aims to fill this gap by offering a resource-efficient, thorough method to evaluate uncertainty. It consists of 3,978 questions divided into four categories—Knowledge, Language, Understanding, and Reasoning—designed to test LLMs under diverse scenarios (Figure 1). Utilizing a single-sampling method, UBench provides streamlined evaluations while maintaining computational efficiency.

Figure 2: In the context of different candidate answers to the same question, LLMs display different levels of confidence (in other words, uncertainty). Note that LLMs may exhibit consistent levels of confidence for either the wrong answer or the right answer, which we do not want.
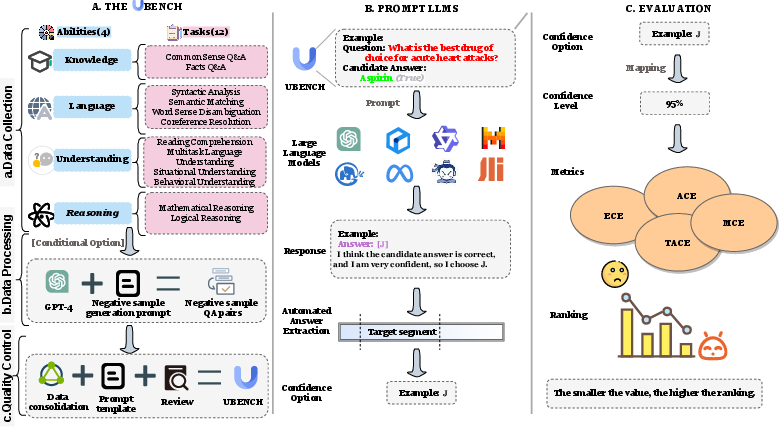
Figure 1: Construction process of UBench and systematic, automated LLM uncertainty evaluation framework. The data sources of UBench are from multiple types of public datasets, processed into the uncertainty evaluation format and carefully controlled for quality. Then UBench is leveraged to compare the reliability of typical open-source and closed-source LLMs with 4 evaluation metrics.
Data Construction and Prompt Design
The data for UBench was meticulously curated from 20 publicly available datasets, each providing 100 data samples, ensuring diversity and comprehensive coverage across various competencies. To assess LLMs' reliability, questions were categorized into four domains: Knowledge, Language, Understanding, and Reasoning. Each domain targets a unique aspect of language processing, from factual knowledge to syntactic analysis and logical reasoning (Figure 3).
A key innovative aspect of UBench is its approach to uncertainty through multiple-choice questions. The responses are reformulated into a ten-choice format allowing LLMs to express confidence within specified intervals—each corresponding to a percentage confidence range. High reliability is indicated by high confidence in correct responses and low confidence in incorrect ones.
UBench employs various evaluation metrics to ascertain the reliability of LLMs: Expected Calibration Error (ECE), Average Calibration Error (ACE), Maximum Calibration Error (MCE), and Thresholded Average Calibration Error (TACE) with a threshold set at 0.5. These metrics quantify the discrepancy between confidence levels and accuracy, with lower scores indicating better calibration and reliability.
In the evaluation of 15 prominent LLMs, GLM4 demonstrated the highest reliability, followed by GPT-4, showcasing a non-binary scenario where open-source models such as Llama3 and InternLM2 showed promising results, narrowing the performance gap with closed-source models (Table \ref{overall_performance}).
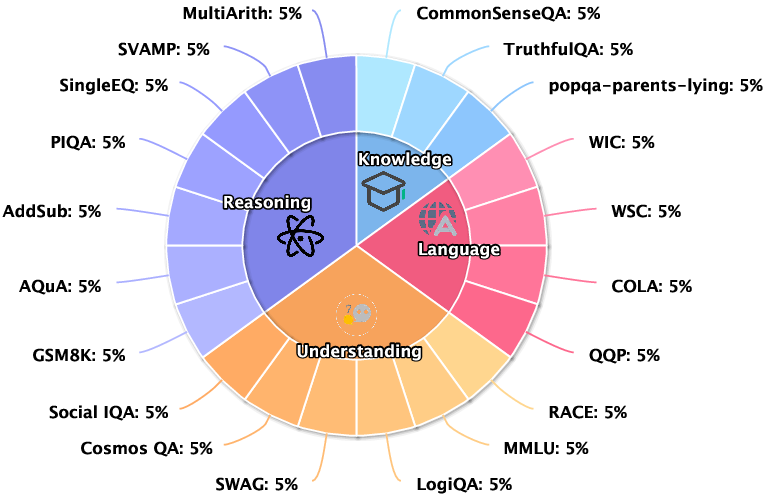
Figure 3: UBench covers 4 categories: Knowledge, Language, Understanding, and Reasoning, with a total of 3,978 ten-item multiple-choice questions.
Impact of Prompt Engineering and Temperature
The evaluation explored how prompt engineering techniques—that is, Chain-of-Thought (CoT) and role-playing prompts—affect LLM reliability. CoT prompts generally improved ECE but increased MCE, highlighting a trade-off between expected reliability and extreme unpredictable cases. Tests revealed that GLM4 and GPT-4 showed varying susceptibility to these prompts (Figures 4 and 12).
Furthermore, experiments (Figure 4 and Table \ref{auto-random-subset}) indicated that the sequence order of confidence interval options impacts LLM performance, with models like GPT-4 displaying positional biases. In terms of the temperature setting (Figure 5 and Table \ref{auto-temperature-subset}), ChatGLM2 and GLM4 showed increased reliability with higher temperatures, contrasting with GPT-4's decline, stressing the need for adaptive temperature settings depending on the LLM in use.
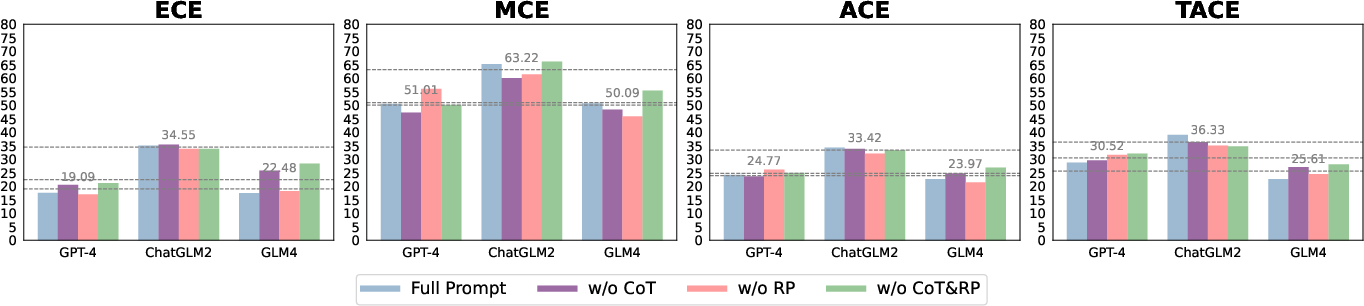
Figure 6: Results of the ablation experiment involving GPT-4, ChatGLM2, and GLM4, studying the effects of CoT and role-playing prompts on LLM reliability. "w/o" means removing the prompt, "CoT" indicates the Chain-of-Thought prompt, and "RP" represents the role-playing prompt (same as below).
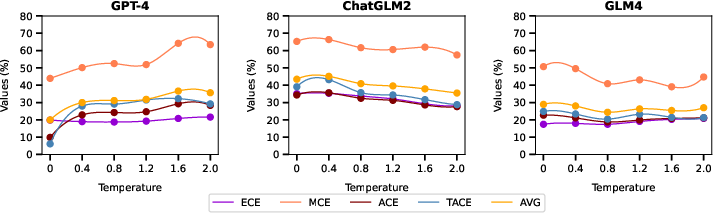
Figure 5: Results of experiments with GPT-4, ChatGLM2, and GLM4, studying the effects of temperature on LLM reliability.
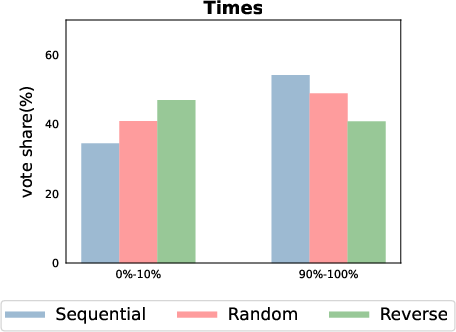
Figure 7: Under different confidence interval option settings, GPT-4 shows variations in the proportions selected for the 0-10\% and 90-100\% ranges. This indicates how the ordering of confidence interval options affects the model's choices.
Conclusion
UBench represents a significant advancement in the field of LLM evaluation, meticulously addressing the more nuanced aspect of uncertainty in model predictions. The benchmark underscores that existing LLMs, while powerful, can make decisions with levels of overconfidence that may lead to erroneous outputs. The study's findings also suggest directions for improving LLM reliability, such as optimizing model prompts and reconsidering the implications of parameters like temperature and option order. Exploring these variables may pave the way for enhancing LLM performance, closing the reliability gap between open-source and closed-source models, and facilitating their broader application in various domains. Pioneering a thorough uncertainty evaluation framework without introducing additional computational complexity sets a viable precedent for future efforts in creating scalable, resource-efficient benchmarks. A more comprehensive investigation into how different settings influence LLM reliability will benefit the future landscape of LLM capabilities, particularly in the assessment of these models in diverse environments. The study points to the necessity of further research in understanding the dependency between model reliability and its influencing factors, which should remain a focal point for ongoing and future research in LLM reliability.
Figure 1: Construction process of UBench and systematic, automated LLM uncertainty evaluation framework. The data sources of UBench are from multiple types of public datasets, processed into the uncertainty evaluation format and carefully controlled quality. Then UBench is leveraged to compare the reliability of typical open-source and closed-source LLMs with 4 evaluation metrics.
Conclusion
UBench represents a purposeful endeavor to effectively assess and benchmark the reliability of LLMs with respect to their uncertainty measurements. Unlike conventional benchmarks, UBench emphasizes the importance of calibrating LLM outputs' confidences, fostering a more robust understanding and application of these models in high-stakes environments. The study's findings highlight the significant advancements among open-source LLMs in reliability, standing competitively with their closed-source counterparts. These insights should guide future developments and research towards bridging the reliability gap in LLM outputs, focusing on refining prompt techniques, option order, confidence interval structuring, and adjusting model hyperparameters to improve model predictability in uncertain or high-risk scenarios. Such advancements promise to enhance the safe and effective deployment of LLMs across diverse applications.

