- The paper systematically evaluates four uncertainty estimation methods—VCE, MSP, Sample Consistency, and CoCoA—for large language models.
- Results indicate that the CoCoA approach achieves better calibration and discrimination, while MSP reliably ranks generated answers.
- The study offers practical guidelines for selecting uncertainty metrics based on task complexity and computational efficiency.
Systematic Evaluation of Uncertainty Estimation Methods in LLMs
Introduction
The paper "Systematic Evaluation of Uncertainty Estimation Methods in LLMs" (2510.20460) addresses the unreliability often exhibited by LLMs when producing outputs with varying levels of uncertainty and correctness, which poses significant risks in critical applications. To address this issue, the authors systematically evaluate four distinct approaches for uncertainty estimation in LLM outputs: Verbalized Confidence Elicitation (VCE), Maximum Sequence Probability (MSP), Sample Consistency, and Confidence-Consistency Aggregation (CoCoA).
These methods are tested across several question-answering tasks using a contemporary open-source LLM, highlighting how each captures different facets of model confidence. Notably, the hybrid CoCoA approach demonstrates enhanced reliability by improving calibration and discrimination of accurate answers. The paper provides valuable insights into the trade-offs associated with each method and offers guidelines for selecting appropriate uncertainty metrics in practical LLM applications.
Uncertainty Estimation Methods
Verbalized Confidence Elicitation (VCE)
VCE leverages LLMs' ability to express self-assessed confidence levels, inviting the models to provide both an answer and a confidence score. Although this approach is simple and model-agnostic, it tends to result in overestimated confidence scores, particularly with models fine-tuned for instructiveness.
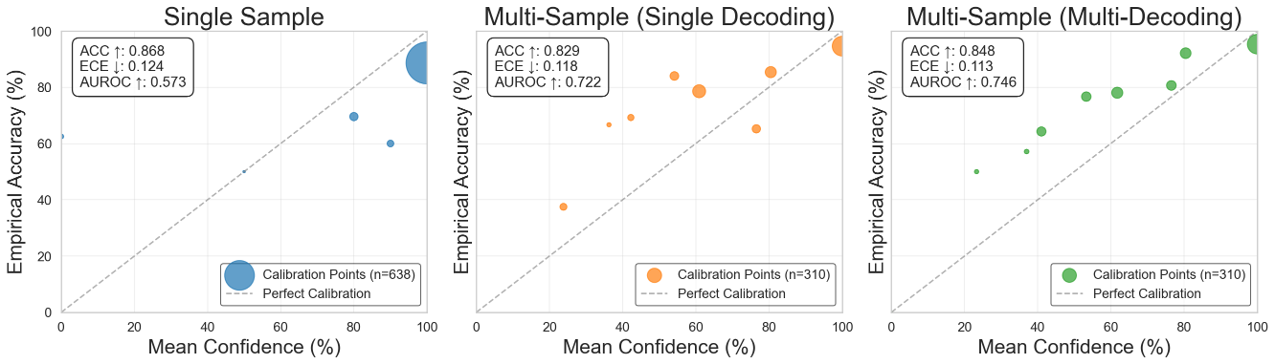
Figure 1: VCE calibration on SQuAD\,2.0 across decoding methods. Reliability plots for single-sample, multi-sample with single decoding, and multi-sample with multi-decoding.
To mitigate overconfidence, the authors employ multiple sampling, wherein independent answers are aggregated to compute a weighted confidence score favoring majority-agreement answers.
Maximum Sequence Probability (MSP)
MSP determines confidence through the internal probability assigned by the LLM to produced sequences. The authors apply normalization techniques to transform these probabilities into bounded confidence scores for better comparability across different tasks.
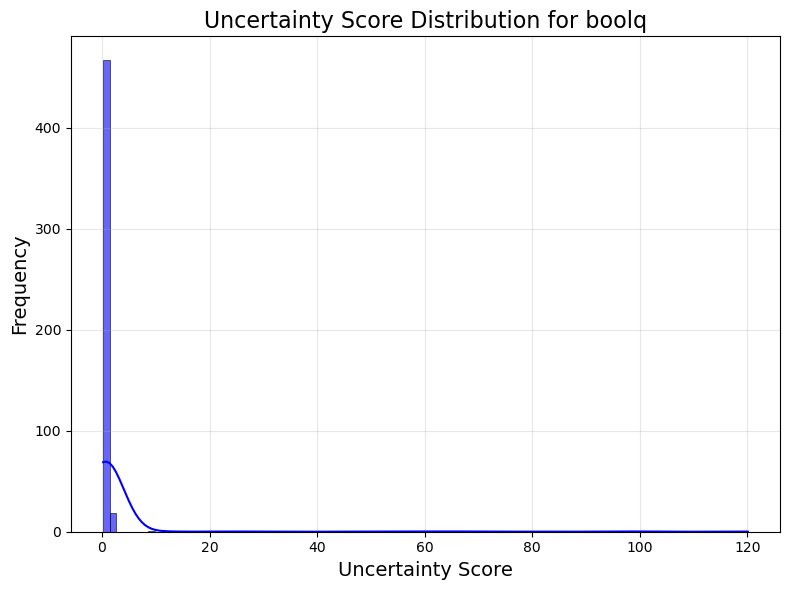
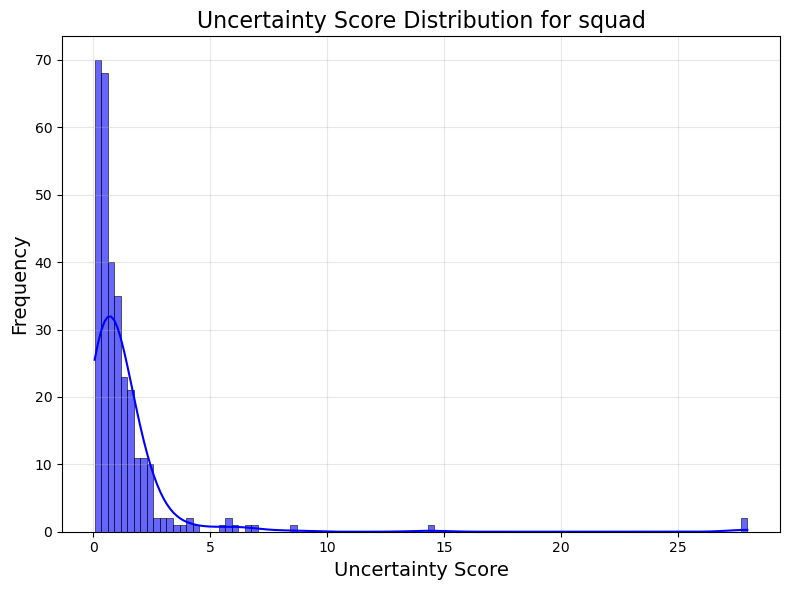
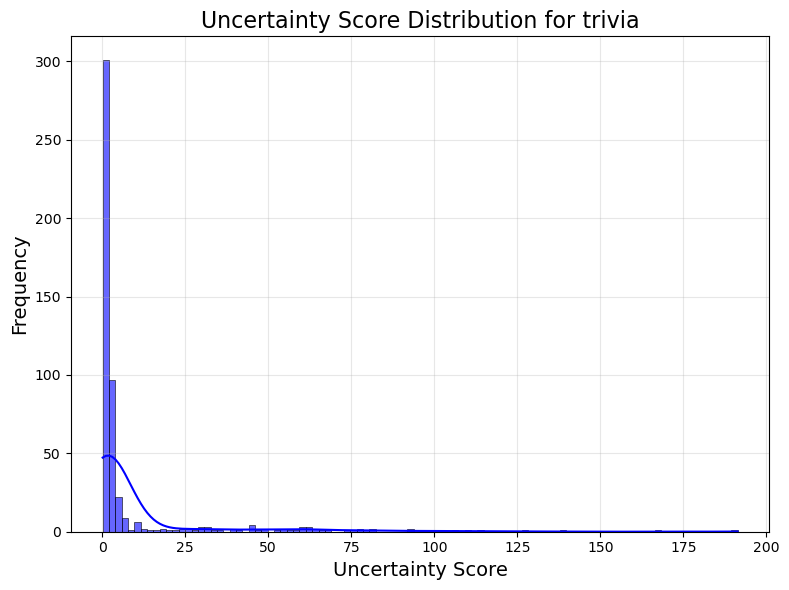
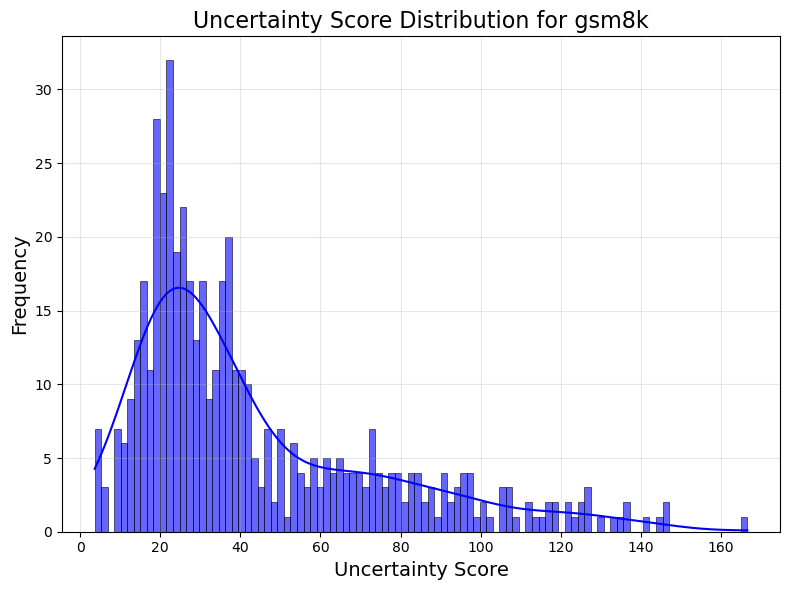
Figure 2: Distribution of raw MSP uncertainty scores.
Though MSP achieves superior discrimination in some tasks, calibration often remains weaker compared to hybrid methods like CoCoA due to inherent biases towards assigning high probabilities to incorrect answers.
Sample Consistency
Sample Consistency evaluates the stability of LLM outputs across multiple sampled answers for the same query. This method effectively captures epistemic uncertainty through semantic agreement measures, proving particularly beneficial in tasks requiring robust reasoning.
Sample Consistency, with separated decoding, offers enhanced calibration capabilities, highlighting its advantage for scenarios demanding high-quality confidence scores. However, its computational intensity is notable compared to simpler metrics.
Confidence-Consistency Aggregation (CoCoA)
CoCoA amalgamates internal confidence signals and semantic consistency among outputs using a Bayes risk framework. This approach effectively balances internal model uncertainty with output consistency, yielding well-calibrated confidence scores suitable for high-stakes applications.
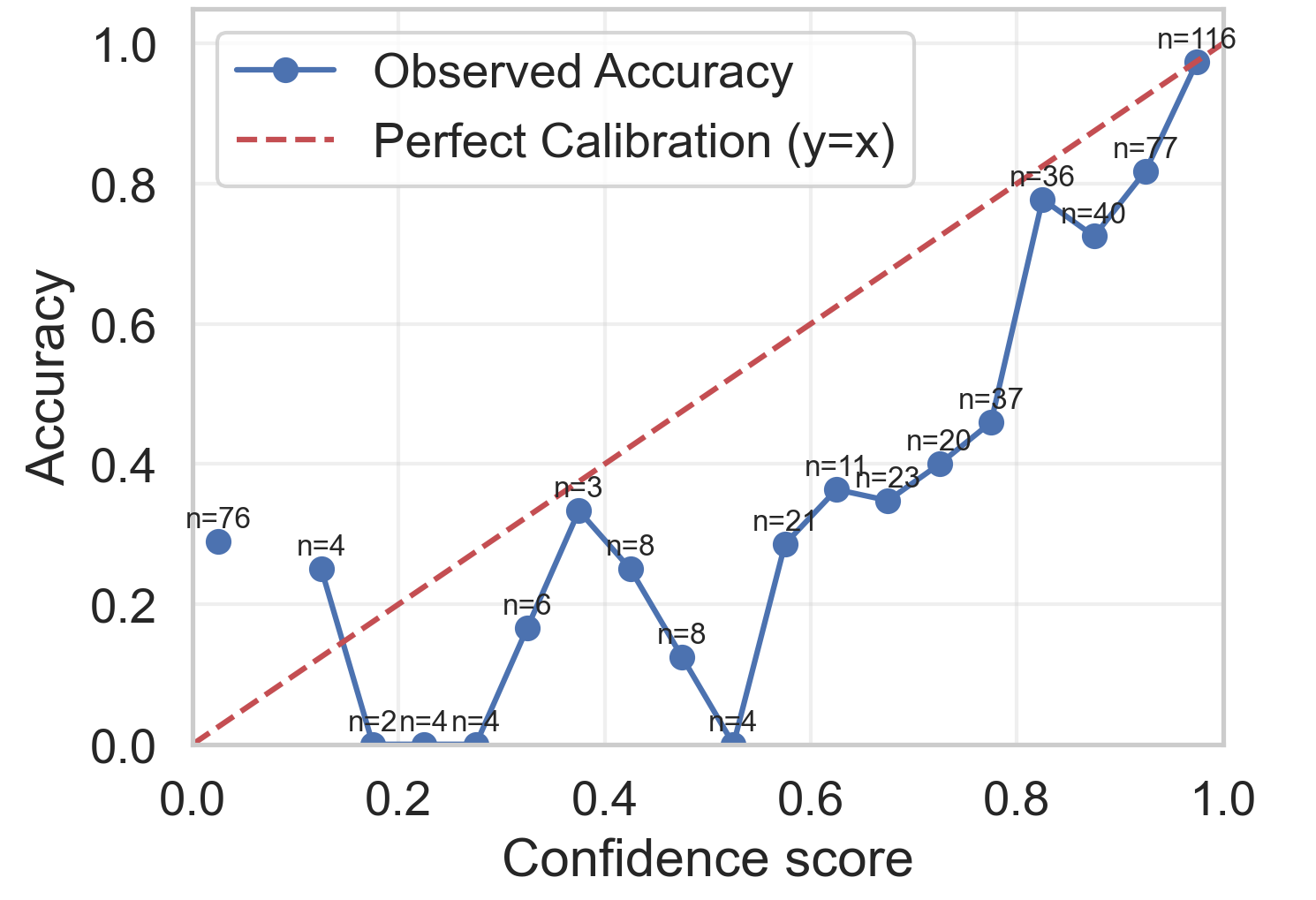
Figure 3: Calibration of CoCoA on TriviaQA.
CoCoA represents a promising methodology for achieving reliable confidence scores with minimal computational drawbacks, offering improved performance across a range of tasks.
Results and Analysis
Across various datasets, each uncertainty estimation method exhibits distinctive performance characteristics contingent upon task complexity and type. The CoCoA methodology emerges as highly calibrated with strong ranking capabilities in difficult tasks involving complex reasoning. Conversely, MSP provides dependable ranking across knowledge-intensive tasks, although calibration is more variable.
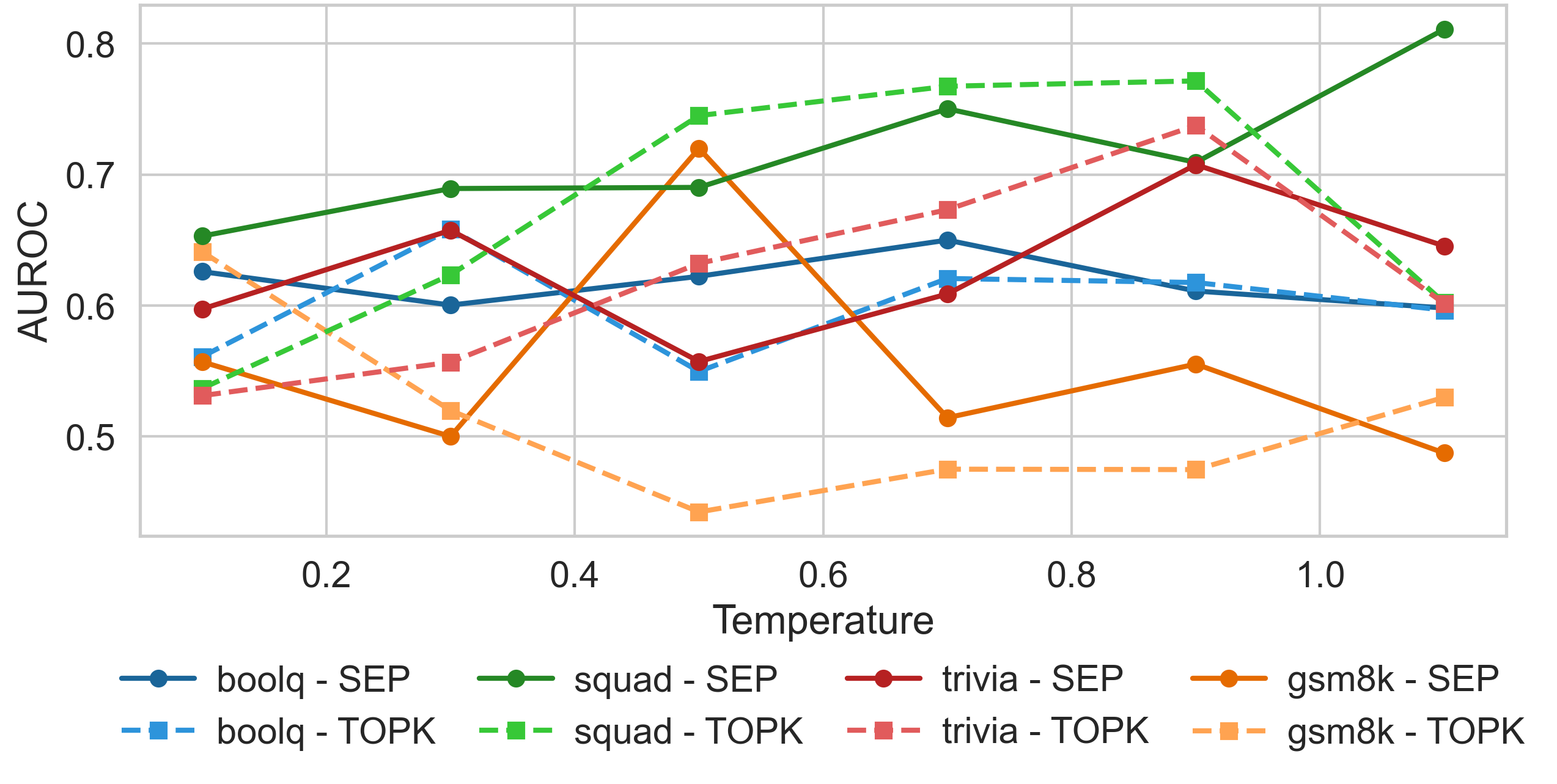
Figure 4: Temperature effects on ranking quality.
The paper further investigates decoding temperatures and sample strategies, concluding that optimal settings are task-specific and recommending practical application methods wherein MSP serves as a reliable ranking tool, while VCE and CoCoA bridge calibration needs.
Conclusion
The systematic evaluation offers valuable insights into the practical integration of uncertainty estimation methods within LLM-driven applications. The research evaluates varied estimation techniques, illustrating their benefits and limitations across diverse question-answering tasks. Hybrid methodologies such as CoCoA demonstrate promise in bridging confidence and consistency, providing calibrated scores essential for dependable AI deployments.
Methodological improvements, sample aggregation strategies, and task-specific calibration align to enhance practical reliability measures, equipping downstream systems with informed, confidence-level insights. While computational costs present considerations in multi-sample methods, the authors propose viable trade-offs to achieve desired reliability outcomes effectively.
Future Directions
This comprehensive analysis lays the groundwork for further exploration into uncertainty estimation across broader NLP tasks, prompting investigations into longer-form outputs and dialog-driven model interactions. Advancements in optimizing computational overhead and extending model compatibility are subsequent steps towards refining confidence management systems in AI applications. Through continued research and method refinement, LLMs can operate with increased trustworthiness in critical scenarios, addressing the core unreliability challenges highlighted in this paper.