- The paper introduces TaskSense, a novel framework that quantifies GUI task difficulty using cognitive chain modeling and cognitive-psychological principles.
- It employs an LLM-driven extraction pipeline to segment cognitive steps—such as Orient, Find, and Decide—into quantifiable difficulty indices, validated through human performance studies.
- Empirical results demonstrate superior predictive power over motor-centric benchmarks, with implications for improved agent benchmarking and adaptive human-agent delegation.
Cognitive Chain Modeling and Difficulty Estimation for GUI Tasks: An Expert Synopsis of TaskSense
Introduction and Motivation
The "TaskSense" framework presents a comprehensive and theoretically grounded method to estimate the cognitive difficulty of GUI tasks by modeling the underlying cognitive processes that precede motor actions. Prior art in HCI primarily quantifies task difficulty via motor-centric metrics—such as step counts, execution times, or mechanical effort—while neglecting the diverse and context-dependent cognitive demands inherent in real-world GUI tasks. The TaskSense approach addresses this shortcoming by formalizing the notion of a cognitive chain: a linear or hierarchical sequence of cognitive steps performed prior to each GUI operation. These steps are taxonomized, parameterized, and quantitatively evaluated via information-theoretic and cognitive-psychological principles. The system is operationalized via an LLM-driven extraction pipeline capable of automatically parsing user interaction traces and generating cognitive chain representations and difficulty indices.
The motivation is to transcend basic step-count benchmarks in agent evaluation and user modeling, enabling nuanced analyses of agent limitations, human-agent consistency, and informing training, benchmarking, and collaborative delegation strategies.
TaskSense decomposes preceding cognition into eight atomic types: Orient, Find, Extract, Recall, Decide, Compute, Create, and Verify. Each cognitive type is assigned a specific difficulty function parameterized by domain-relevant factors, such as the candidate set size (for Find), information chunk ratio (for Extract), step distance (for Recall, via exponential decay), explicit/implicit choice space cardinality (for Decide), and chunk count (for Create/Verify). These difficulty indices are grounded in canonical laws (Hick’s, Fitts’, Shannon entropy) and contemporary cognitive models.
For a sequence of GUI motor actions, the cognitive chains are extracted, and task difficulty is defined as:
DTask=∑i=1nDStepi
where each step difficulty is:
DStepi=DCogChaini+DMotori=j=1∑miDi,jCogStep+DMotori
Each cognitive step is further weighted by empirically fitted base difficulty scalars KType, yielding a linear additive model for cognitive time estimation.
An example task, such as parsing interview invitations from emails to calendar events, illustrates the sequential cognitive processes of extraction, recall, element finding, and motor execution.
Figure 1: Cognitive chains extracted for a user creating calendar events from email invitations, illustrating sequential Extract, Recall, Find, and Motor steps.
The extraction system is built atop large multimodal LLMs (GPT-4o, Gemini-2.5-pro), leveraging both GUI event logs and accompanying screenshots. The pipeline includes:
- Semantic Analysis: Parsing each event-image pair to yield an enriched description of motor operations.
- Cognitive Chain Extraction: Batch-wise LLM inference, combining semantic outputs and historical summaries to segment cognitive steps and assign type-appropriate difficulty parameters.
The method is tightly constrained by an algorithmic framework and taxonomy (enforced in prompts) to ensure consistency and recover context-dependent cognitive state transitions (e.g., triggering Verify upon subtask switches and Orient upon new goals).

Figure 2: TaskSense cognitive chain extraction method workflow: event log ingestion, batchwise semantic and cognitive extraction, and difficulty parameterization.
A multistage study was conducted employing 18 representative GUI tasks with dense cognitive variation, sampled from both natural logs and established agent benchmarks (OSWorld, Mind2Web). User traces were systematically collected in laboratory settings, using screen/app event recording plus think-aloud protocols. Step-level completion times were annotated, and cognitive chains were extracted both automatically and via expert review for accuracy assessment.
Regression analyses (with LOSO cross-validation) demonstrate substantial explanatory power; cognitive chain-derived difficulties correlated with actual human step durations at R2=0.46 (annotated, step-level) and $0.69$ (task-level), outperforming step-count and uniform chain baselines. Prediction RMSE was 37.4% of average task duration, indicating strong utility for behavioral time modeling.
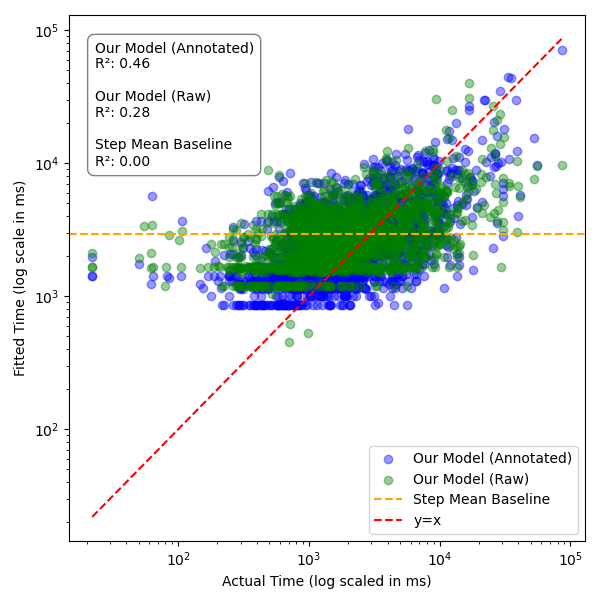
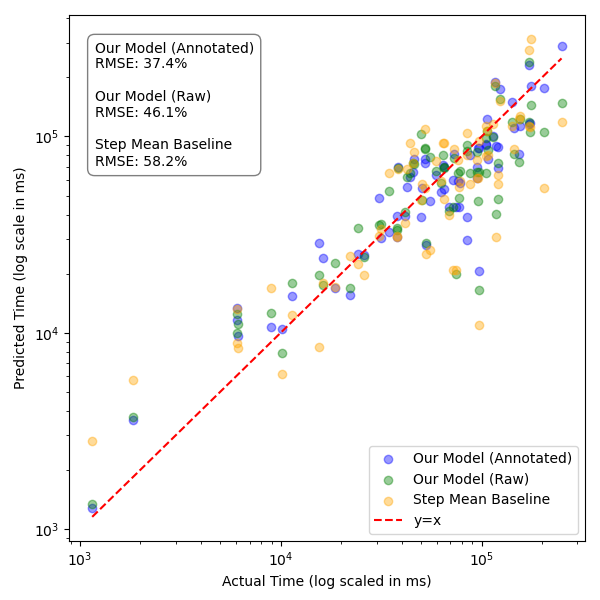
Figure 3: Scatter plots of actual vs. fitted step times, showing improved fit with the cognitive difficulty model compared to baselines.
The base difficulties reveal a stratification of cognitive cost: Compute, Create, and implicit Decide impose the highest time costs, with Orient and Recall being significantly cheaper. Error analysis indicates extraction bottlenecks due to limited attention cues and multimodal context (e.g., missing eye-gaze data), and unobservable cognitive factors (user fatigue, transient confusion).
Four state-of-the-art GUI agents (Claude-4 variants, UI-TARS, Fellou) were evaluated on the same benchmark tasks. Cognitive path alignment criteria were applied to standardize agent action sequences to minimal required chains for success. Manual annotation of step success/failure, with error source attribution at the cognitive step level, enables fine-grained capability analysis.
The results reveal that agent success rates degrade with increasing cognitive difficulty, especially for Verify, Orient, Create, and Decide types. Failures are observed in feedback interpretation, context tracking, and lack of access to user-specific preferences or context—agent limitations not surmountable purely by scaling model size or training data, but requiring advances in cognitive state modeling or explicit user-context grounding.
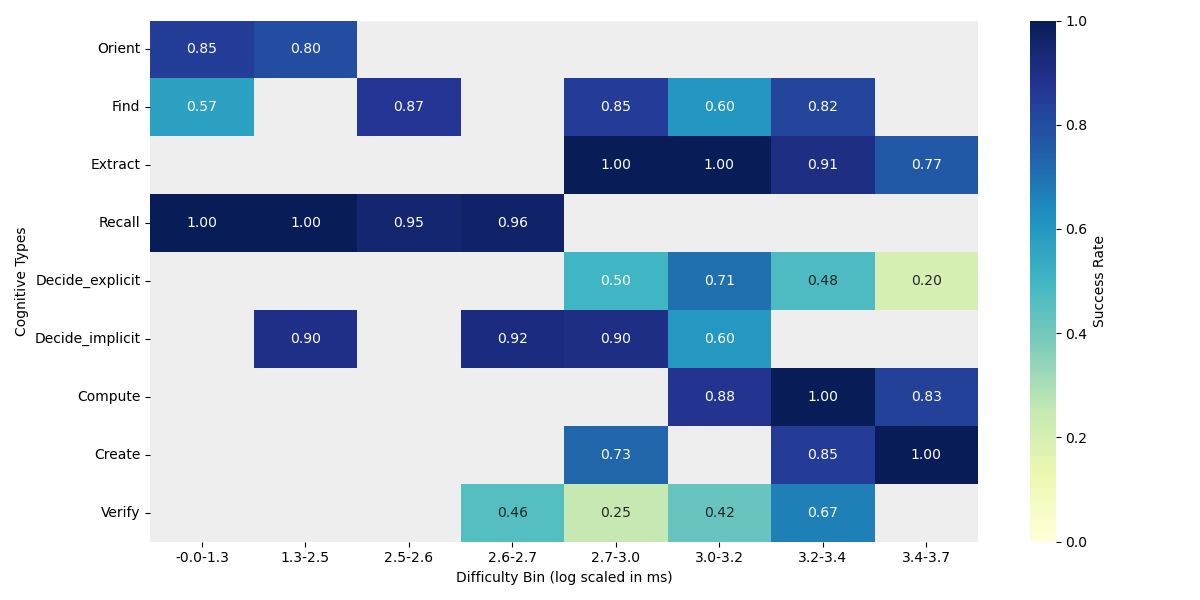
Figure 4: Success rates of four GUI agents across cognitive types and binned difficulty index, exposing capability gaps particularly in Verify, Create, and high-difficulty Extract/Decide steps.
Alignment between human and agent difficulty patterns is type-dependent: strong negative difficulty-success correlation for Orient, Decide, Extract; weaker or reverse trends for Compute and Find. These observations support the claim that human-centered cognitive difficulty estimation is a robust proxy for performance prediction, but also highlights fundamental execution and perception differences.
Implications and Future Directions
The TaskSense paradigm introduces a multidimensional framework for GUI task difficulty estimation, bridging symbolic cognitive science and scalable LLM-driven modeling. Practical consequences include:
- Agent Benchmarking: Difficulty-aware evaluation exposes nuanced capability gaps, informing targeted data curation, multi-agent designs, or curriculum learning strategies.
- Training Data and Knowledge Integration: Extracted cognitive chains serve as chain-of-thought exemplars for agent training, with parallels to ReAct and CodeI/O. The cognitive chain corpus can also be utilized as external task knowledge for enhancing search, recovery, and generative strategies in agents.
- Human-Agent Delegation: Dynamic, difficulty-aware task allocation becomes feasible, supporting cooperation modes where high-cognitive steps (user-dependent or requiring creative input) are flexibly delegated to humans, with low-difficulty automation by agents. Real-time modeling, enabled by the extraction pipeline, can facilitate proactive assistance and adaptive UI design.
Limitations persist: present modeling assumes linear independence between steps and relies on event logs/screen capture, which may omit critical multimodal cues (e.g., gaze, mouse trajectory), and struggles with error detection and intention inference. Further research is needed on integrating richer behavioral telemetry, nonlinear cognitive-motor interaction models, and context-grounded agent reasoning.
Conclusion
TaskSense demonstrates that modeling GUI task complexity from the perspective of cognitive chains—explicitly parameterized and extractable—significantly advances the fidelity of user behavior analyses and agent capability prediction. The framework is built on a rigorous integration of cognitive modeling, empirical fitting, and LLM-based automation, providing actionable insights and metrics for both HCI and AI agent communities. Future research should explore cross-domain generalization, richer multimodal integration, and real-time delegation optimization for hybrid human-agent systems.

