VISTA: A Test-Time Self-Improving Video Generation Agent
Abstract: Despite rapid advances in text-to-video synthesis, generated video quality remains critically dependent on precise user prompts. Existing test-time optimization methods, successful in other domains, struggle with the multi-faceted nature of video. In this work, we introduce VISTA (Video Iterative Self-improvemenT Agent), a novel multi-agent system that autonomously improves video generation through refining prompts in an iterative loop. VISTA first decomposes a user idea into a structured temporal plan. After generation, the best video is identified through a robust pairwise tournament. This winning video is then critiqued by a trio of specialized agents focusing on visual, audio, and contextual fidelity. Finally, a reasoning agent synthesizes this feedback to introspectively rewrite and enhance the prompt for the next generation cycle. Experiments on single- and multi-scene video generation scenarios show that while prior methods yield inconsistent gains, VISTA consistently improves video quality and alignment with user intent, achieving up to 60% pairwise win rate against state-of-the-art baselines. Human evaluators concur, preferring VISTA outputs in 66.4% of comparisons.
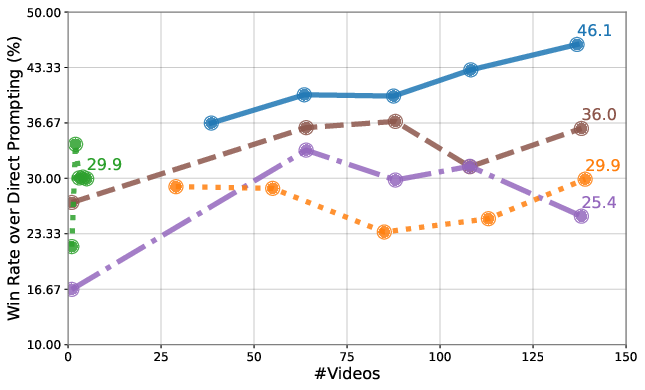
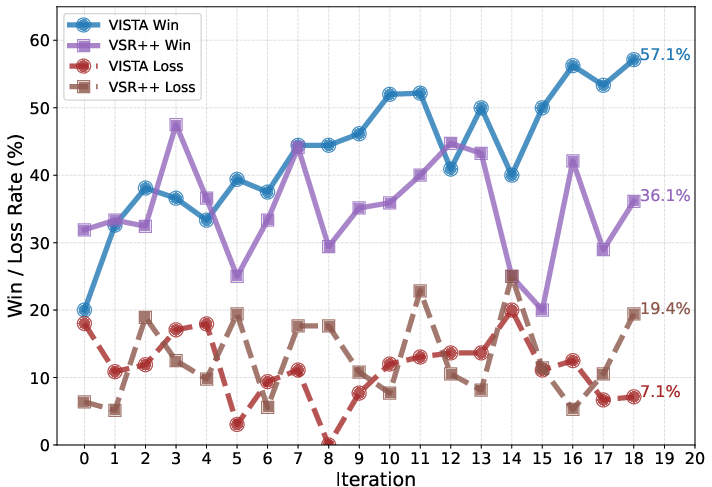
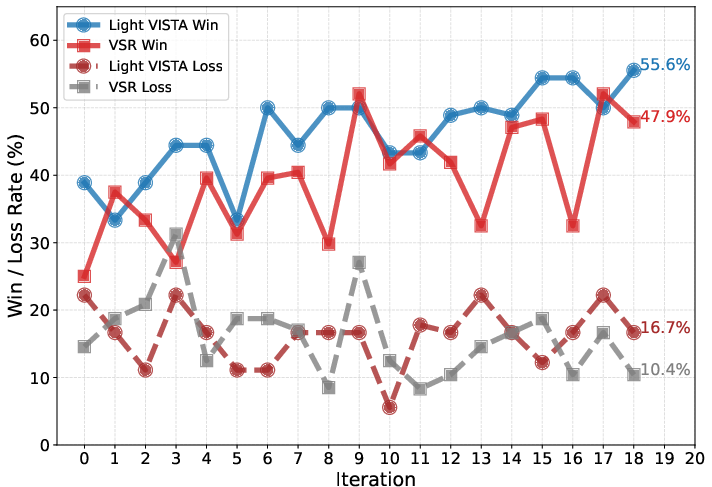






























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
Imagine you tell an AI, “Make a short movie of a dog chasing a ball on a beach at sunset.” Sometimes the result looks great; other times the camera drifts, the motion is weird, or the sound doesn’t match. This paper introduces VISTA, a “self-improving” helper that sits on top of a video generator. VISTA watches the videos it makes, critiques them like a team of judges, rewrites the instructions (the “prompt”), and tries again—improving the video step by step without you having to manually tweak things.
The main goal and questions
The researchers wanted to know:
- Can an AI automatically improve the quality of generated videos just by refining the prompt at test time (right when you’re creating the video), instead of retraining the model?
- Can it do this across three big areas people care about: how the video looks (visual), how it sounds (audio), and whether the story and details make sense (context)?
- Will this beat common methods like “just rewrite the prompt once” or “ask the AI to self-refine” that work for text/images but often fail for complex videos?
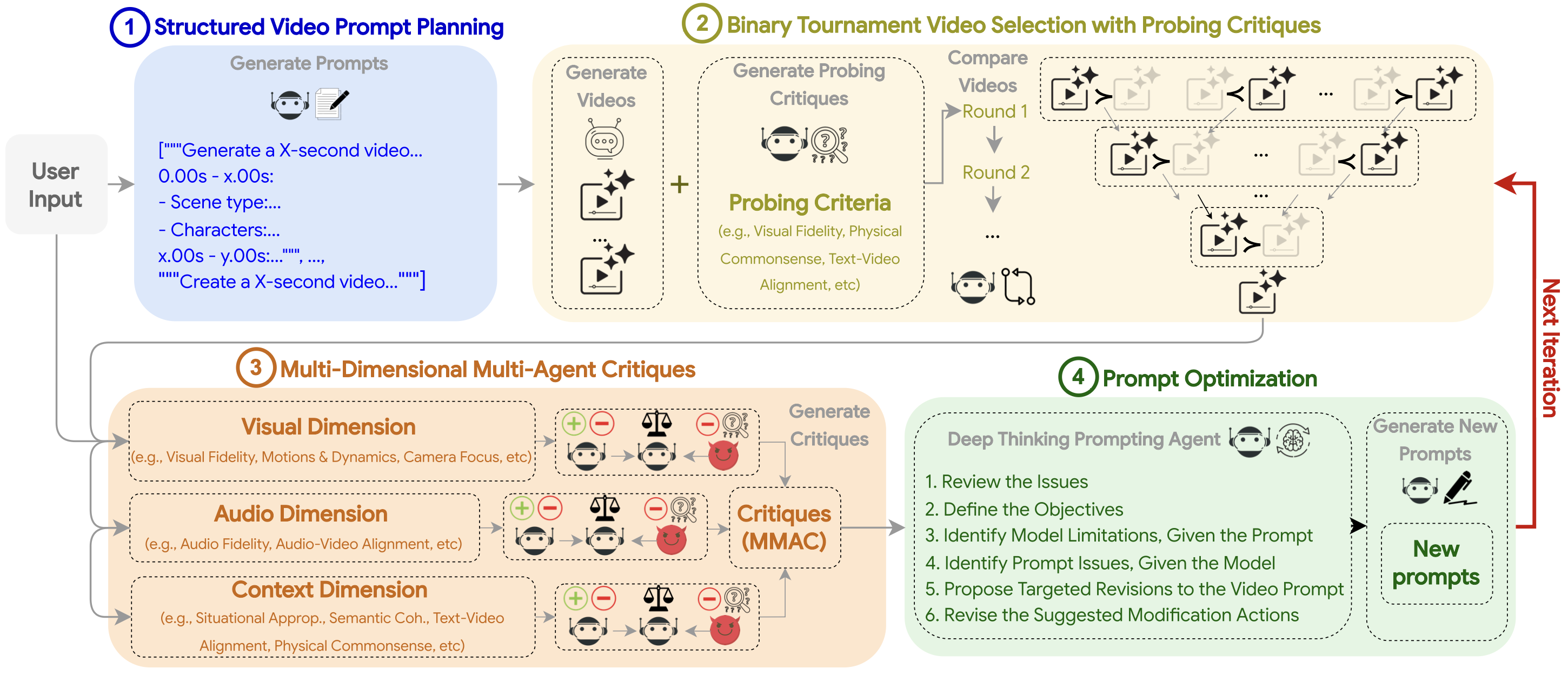
How VISTA works (in simple terms)
Think of VISTA like a small movie crew plus a competition bracket:
- Plan your idea into scenes Before making any video, VISTA breaks the user’s idea into a simple movie plan with scenes. Each scene includes things like:
- Duration (how long the scene is)
- Characters (who’s in it)
- Actions (what they do)
- Visual environment (where it is)
- Camera (how it’s filmed: close-up, panning, etc.)
- Sounds (music, voices, ambient noises)
- Mood (the feeling)
- Plus dialogue and scene type, if relevant
This turns a vague prompt into a clear, step-by-step plan the video model can follow.
- Make several versions and run a tournament VISTA generates multiple videos from slightly different prompt versions. It then compares them in pairs—like a sports bracket—picking the winner from each match until one champion remains. To compare fairly, it:
- Judges across several criteria (for example: visual quality, physical realism, matching the prompt, audio quality, and how engaging it is).
- Swaps the order of videos in comparisons to reduce bias, then decides which one truly did better.
- Critique with three specialized “judges” After choosing the best video so far, VISTA asks three expert “judges” to critique it:
- Visual judge: checks image quality, camera focus, smooth motion, and safety.
- Audio judge: checks sound quality, matching sound to the action, and safety.
- Context judge: checks if the story makes sense, follows physical common sense, aligns with the prompt, flows well between scenes, and keeps viewers engaged.
Each judge works like a mini courtroom:
- A normal judge explains strengths and weaknesses.
- An adversarial judge tries to poke holes and find problems.
- A meta judge combines both and produces the final, balanced critique.
- “Deep-thinking” prompt rewrite VISTA then does a careful, structured rethink of the prompt. It:
- Identifies what went wrong (for example: “camera keeps drifting” or “waves are too loud”).
- Decides if the problem is missing info, unclear wording, or a model limitation.
- Suggests specific fixes (for example: “Use a locked, stable camera in scene 2” or “Reduce ambient wave volume so dialogue is clear”).
- Produces improved prompts and tries again.
- Iterate until good enough VISTA repeats the tournament + critique + prompt rewrite loop for a few rounds, each time aiming for a better video.
What they found (results)
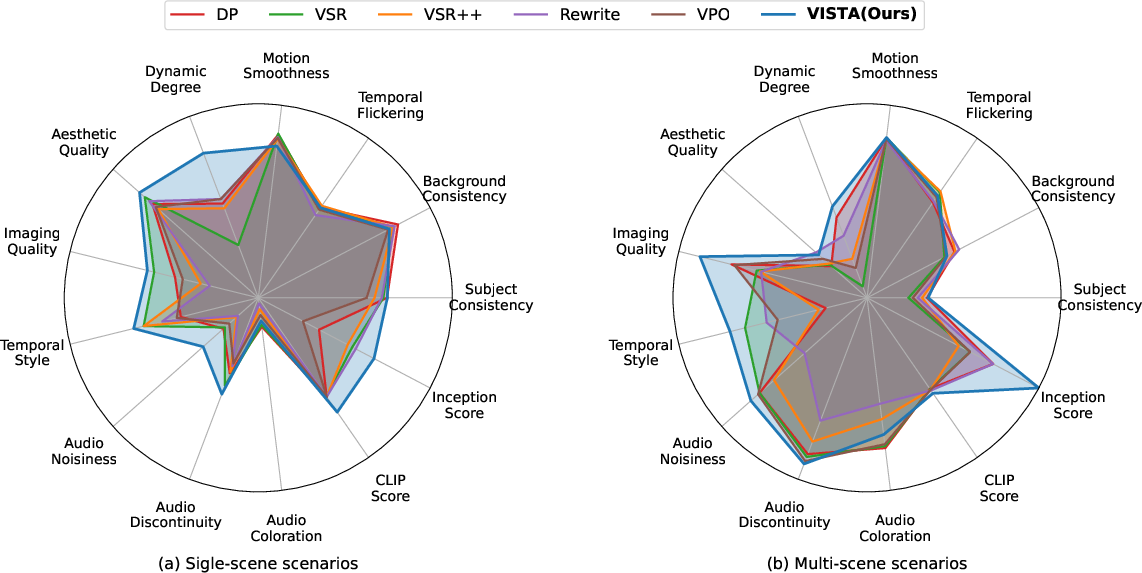
Across two kinds of tests—single-scene prompts and multi-scene story-like prompts—VISTA consistently beat other methods:
- It won up to about 60% of head-to-head comparisons against strong baselines.
- Human reviewers preferred VISTA’s videos 66.4% of the time.
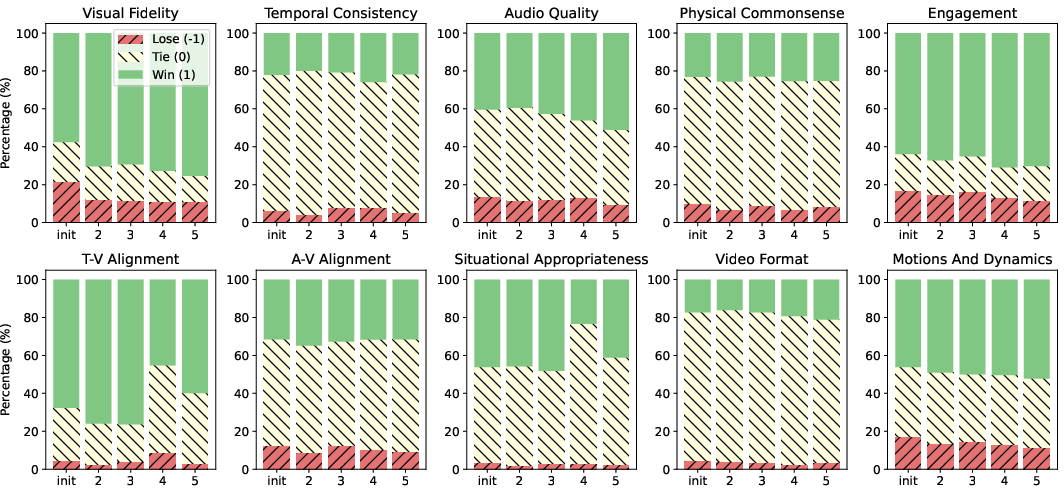
- Improvements showed up in important areas:
- Visual quality (clearer, better-looking shots)
- Motion and dynamics (movement felt more natural)
- Text-video alignment (the video actually matched the prompt)
- Audio quality and audio-video sync (sounds fit what you see)
- Engagement (more interesting and watchable)
- On things the base video model already did well (like smooth scene transitions), gains were smaller, which makes sense.
In short: instead of randomly guessing better prompts, VISTA turns improvement into a structured process—and it works reliably.
Why this matters (impact)
- Less trial-and-error for creators: You spend less time tweaking prompts and more time getting good results.
- Better storytelling: Videos follow your idea more closely and feel more “put together,” with matching sound and visuals.
- Works with different models: VISTA is designed to sit on top of a video model and help it do better without retraining.
- Useful for education, advertising, social media, and filmmaking drafts: Anywhere you need quick, coherent video generation.
A few caveats:
- It costs more compute/time than just generating one video, because it makes several candidates and runs comparisons.
- It still depends on the underlying video model’s abilities—VISTA can guide, but it can’t do magic if the model can’t render a thing at all.
Overall, VISTA shows that an AI can act like a smart director’s assistant: plan the film, judge the results, give precise feedback, rewrite instructions, and keep iterating—so the final video better matches what you imagined.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is framed to be actionable for future researchers.
- Reproducibility and generalization: The framework relies on proprietary models (Gemini 2.5 Flash, Veo 3 preview); results with open-source or alternative commercial MLLMs/T2V models are not assessed.
- Dataset transparency: The internal multi-scene dataset (161 prompts) is not described or released; its domain coverage, duration distribution, and complexity are unknown.
- Human evaluation scale and diversity: Human studies are limited (50 prompts, 5 annotators); there is no analysis of cultural, linguistic, or domain diversity, nor inter-annotator reliability beyond summary.
- Judge bias and calibration: The MLLM-as-a-judge is not calibrated against human preferences at scale; correlation, agreement metrics, and sensitivity to judge choice (Gemini vs. other MLLMs) are missing.
- Conflict resolution in pairwise judging: When forward vs. swapped comparisons disagree, winners are selected randomly; more principled arbitration (third judge, ensemble voting, consistency checks) is not explored.
- Component ablations: The paper lacks ablations to isolate contributions of prompt planning, pairwise tournament, multi-agent critiques (normal/adversarial/meta), and DTPA; interactions and relative importance remain unclear.
- Hyperparameter sensitivity: Effects of penalty λ, metric weights, number of prompts/variants/videos per iteration, and tournament structure on outcomes are not quantified.
- Convergence and stopping: There is no analysis of convergence behavior, oscillation risk, or adaptive early-stopping criteria beyond “no change after m iterations.”
- Cost-effectiveness: Token and video generation costs are reported but not tied to wall-clock time, monetary cost, or cost-performance trade-offs; budget-aware optimization is unaddressed.
- Reward hacking risk: Potential over-optimization to the judge’s preferences rather than human users is not measured; detection and mitigation strategies (adversarial evaluation, cross-judge audits) are absent.
- Diversity preservation: The effect of iterative prompt refinement on creative diversity and output variety is not evaluated; mode collapse risks are unaddressed.
- Scalability to long-form videos: Judging strategy (frame sampling, chunking for long videos) and performance on longer durations or higher resolutions are unspecified.
- Audio evaluation adequacy: NISQA is speech-focused and may not capture music/sound effects quality; domain-appropriate audio metrics (music aesthetics, SFX realism, continuity) and objective AV sync metrics are missing.
- Lip-sync and dialogue alignment: There is no quantitative evaluation of lip-sync accuracy or dialogue-text alignment (e.g., ASR-based measures).
- Narrative coherence across scenes: Beyond transitions, story arc consistency, character continuity, and plot causality are not measured with dedicated metrics or tasks.
- Safety definitions and validation: Operationalization of “Visual Safety” and “Audio Safety” is unclear; false positive/negative rates, red-teaming, and cross-cultural safety norms are not examined.
- Physical commonsense benchmarking: Evaluation relies on judge-based criteria; standardized physical reasoning benchmarks (e.g., VideoPhy tasks) are not used to quantify gains.
- Handling non-realistic domains: The framework’s behavior under fantasy/animated physics and stylized content is not systematically studied; realism constraints’ impact is not quantified in such settings.
- Multilingual generalization: The approach is not tested with non-English prompts or multilingual audio; cross-language reliability is unknown.
- User configurability and UX: Effects of different metric configurations and user-set priorities on outcomes are not studied; user-in-the-loop vs. fully autonomous workflows are not compared.
- Robustness to model drift: Stability under updates to the judge/T2V models (version changes, training updates) and cross-time robustness are untested.
- Cross-model generalization: Beyond Veo 3 (and briefly Veo 2), the method is not evaluated on other T2V systems (including open-source models); portability is uncertain.
- Tournament scalability: Computational complexity and sample efficiency of the binary tournament are not analyzed; more efficient selection strategies (bandits, preference learning) are unexplored.
- Judge input protocol: Details on video preprocessing (frame rate, sampling strategy, segment selection) for the judge are missing; their impact on evaluation fidelity is unknown.
- Audio control mechanisms: The system optimizes audio indirectly via prompts; targeted audio editing/control agents, post-processing, or generation constraints are not investigated.
- Open releases: Code, prompt templates, metric definitions, and datasets are not indicated for release, limiting replication.
- Statistical significance: Win/Tie/Loss rates lack confidence intervals and hypothesis tests; statistical significance across iterations and datasets is not reported.
- Fairness and bias: Demographic fairness, representation, and potential bias amplification through prompt optimization are not evaluated.
- Failure taxonomy coverage: Important failure modes (e.g., compression artifacts, flicker, banding, color shifts) may be underrepresented in the metric suite; coverage and detection thresholds are unspecified.
- Prompt length and readability: DTPA may increase prompt complexity; readability, maintainability, and user burden are not measured.
- Integration of human feedback: The framework does not explore fusing human critiques with agent feedback to compare performance vs. fully automatic critiques.
- Domain transfer: Applicability to specialized domains (education, scientific visualization, medical simulations) and domain-specific metrics is untested.
- Audio hallucination detection: Methods to detect and penalize sounds not present or contradicting visuals (e.g., mismatched effects) are not specified.
- Judge ensemble strategies: Using multiple diverse judges (ensembles, cross-model triangulation) to reduce single-model bias is not explored.
- Explainability and user-facing reports: How critiques are communicated to users, and whether they are actionable and interpretable, is not evaluated.
- Adaptive termination: The “m” parameter for early stop is not tuned or justified; adaptive thresholds based on meta scores or improvement slopes could be investigated.
Practical Applications
Immediate Applications
Below are actionable, deployable use cases that can be implemented now using the paper’s methods (Structured Video Prompt Planning, Pairwise Tournament Selection, Multi-Dimensional Multi-Agent Critiques, and Deep Thinking Prompt Optimization).
- Media and Entertainment — Prompt Auto-Refiner for T2V editors
- Product: “Improve Prompt” plugin for video-generation tools (e.g., Veo, Sora), automatically decomposing a concept into multi-scene plans and iteratively refining prompts to fix camera focus, transitions, and visual/audio fidelity.
- Workflow: User concept → VISTA planner → generate candidates → binary tournament selection → MMAC critiques → DTPA rewrite → export best video.
- Dependencies: Access to a capable T2V model with audio generation and an MLLM judge; compute budget for multiple generations per iteration; content policy alignment.
- Marketing and Advertising — Creative A/B Generator and Selector
- Product: SaaS that produces multiple ad variants and uses pairwise, criteria-based tournaments to select the best performer before human review.
- Sector fit: Performance marketing teams, agencies; integrates brand safety constraints via configurable penalties (e.g., Visual/Audio Safety).
- Dependencies: Reliable evaluator prompts tuned to brand guidelines; guardrails for misleading or unsafe claims; human approval in regulated campaigns.
- Social Media and Creator Economy — One-Click TikTok/Shorts Video Improver
- Product: Mobile app feature that runs a small number of refinement iterations to fix shaky motion, poor audio-video alignment, and weak story beats.
- Dependencies: Latency constraints; cost controls (cap #videos, shorter durations); platform content policies.
- Education — Lesson Video Builder
- Product: Converts learning objectives into multi-scene educational clips (with narration, scene types, and appropriate transitions) and auto-checks for contextual appropriateness and physical commonsense.
- Workflow: Course outline → structured plan → generation → MMAC critiques emphasizing Text-Video Alignment and situational appropriateness → prompt refinement.
- Dependencies: Human educator in the loop; verification of factual accuracy; institutional content compliance.
- Corporate Training and Safety — Pre-Deployment QA/Compliance Gate
- Product: “Video QA Gate” that flags violations (e.g., unsafe steps, inconsistent procedures) using MMAC with Visual/Audio Safety and Physical Commonsense; outputs an audit trail of critiques and revisions.
- Sector fit: Manufacturing, aviation, healthcare (non-clinical training), energy operations.
- Dependencies: Domain-specific rubric tuning; human sign-off; legal review for safety-critical content.
- Accessibility — Audio-Video Alignment Auditor
- Product: Checks generated videos for timing mismatches (voiceover, ambient sounds) and proposes prompt fixes to improve intelligibility for diverse audiences; can recommend captioning/narration prompts.
- Dependencies: Accurate evaluator for audio cues; integration with captioning/ASR tools; accessibility standards (e.g., WCAG).
- Product Support and Documentation — How-To Video Generator
- Product: Multi-scene tutorial generation with camera directions and clear beginnings/endings; tournament selection prioritizes clarity and engagement.
- Sector fit: Software onboarding, consumer electronics, enterprise tools.
- Dependencies: Verified instructions; brand tone prompts; human review for correctness.
- Game Development and Pre-Visualization — Storyboard-to-Animatic
- Product: Converts designer storyboards into coherent animatics, optimizing camera focus, temporal consistency, and motion dynamics.
- Dependencies: Creative lead approval; alignment with art direction; manageable iteration costs.
- Software/API Providers — Evaluation-as-a-Service for Generative Video
- Product: Cloud API that runs pairwise tournaments and MMAC on customer-generated videos; returns scores, critiques, and a winner.
- Sector fit: Platforms offering T2V; internal QA teams.
- Dependencies: Scalable infrastructure; well-defined metric schemas; privacy-safe handling of customer assets.
- Brand Safety and Content Moderation — Configurable Safety Scorecard
- Product: Policy-tuned evaluation profiles (e.g., “Children’s content,” “Healthcare marketing”) that penalize violations and block unsafe outputs.
- Dependencies: Ongoing policy maintenance; region-specific regulations; appeal/review pathways.
- Academia — Benchmarking Toolkit for Multi-Scene, Multi-Modal Evaluation
- Product: Open-source prompts and evaluator templates to reproduce MMAC and tournaments; supports failure-focused metrics.
- Dependencies: Access to an MLLM-as-a-judge with strong video understanding; documented rubric definitions.
- Finance — Investor and Product Explainer Video Assistant
- Product: Multi-scene explainers that prioritize Text-Video Alignment and situational appropriateness; tournament selection ensures clarity and engagement.
- Dependencies: Legal/compliance review (risk disclosures, claims); conservative audio/visual safety prompts.
- Healthcare (Patient Education) — Micro-Explainer Generator
- Product: Short, approachable videos for procedures, wellness, or device usage with reduced jargon and improved alignment to patient context.
- Dependencies: Clinical expert oversight; adherence to medical information standards; clear disclaimers.
Long-Term Applications
Below are applications that benefit from further research, scaling, or development (e.g., long-form generation, real-time loops, domain adaptation, on-device constraints).
- Autonomous Long-Form Production (Series, Documentaries)
- Vision: End-to-end planning and self-improvement for 10–60 minute content, maintaining narrative coherence across many scenes while meeting broadcast standards.
- Dependencies: Scalable generation costs, long-context planning, robust audio mixing, professional post-production oversight.
- Real-Time Interactive Video Generation (Live “co-pilot”)
- Vision: Closed-loop refinement during live creation (e.g., directors adjusting shots while the agent iteratively optimizes camera, motion, and audio).
- Dependencies: Low-latency models; streaming evaluators; UI/UX for human-agent collaboration.
- Robotics and Autonomy — Synthetic Video for Policy Learning
- Vision: Failure-aware generation of realistic scenarios with strong physical commonsense to augment perception and decision datasets.
- Dependencies: Domain fidelity guarantees; physics-aware T2V models; validation against real data.
- Education — Adaptive Curriculum Video Generation with Viewer Feedback
- Vision: Use engagement and comprehension signals to iteratively refine prompts and content difficulty; personalize per learner.
- Dependencies: Integration with learning analytics; privacy and consent governance; robust evaluator alignment.
- Policy and Governance — Standardization of Multi-Agent Video Evaluation
- Vision: Regulatory frameworks adopting failure-focused, multi-modal metrics (visual/audio/context) and audit trails for AI-generated video.
- Dependencies: Multi-stakeholder consensus; cross-platform metric interoperability; certification processes.
- Safety-Critical Training in Energy, Aviation, Healthcare
- Vision: Scenario generation with strict constraints (Visual/Audio Safety, Physical Commonsense) and formal verification of steps.
- Dependencies: Domain-specific rule engines; liability-aware review pipelines; traceable critique histories.
- E-Commerce — Personalized Product Video Generation at Scale
- Vision: Mass generation of product explainers tailored to audience segments; continuous improvement via A/B tournaments and customer feedback.
- Dependencies: Data integration (catalogs, PDPs); brand guardrails; governance for authenticity and IP.
- Creative Tools — Multi-Agent Co-Pilot in Professional NLEs
- Vision: Adobe/DaVinci plugins where agents control camera, motion, and sound design; iterative refinement integrated into the edit timeline.
- Dependencies: Toolchain APIs; production-grade audio mastering; human creative direction.
- On-Device/Edge Video Generation for Privacy-Sensitive Contexts
- Vision: Local execution of the planning, critique, and selection loop with compressed models; privacy-preserving auditing.
- Dependencies: Model compression/distillation; hardware acceleration; offline evaluator reliability.
- Cross-Modal Extension — 3D, AR/VR, Volumetric Content
- Vision: Adapt VISTA’s multi-agent critique and tournament selection to spatial content (camera pathing, spatial audio, user comfort/safety).
- Dependencies: New metrics for motion sickness, spatial consistency; advanced generators; device constraints.
- Preference Learning/Fine-Tuning for T2V via Tournament Outcomes
- Vision: Use tournament and critique signals to train reward models or RLHF-style policies for video generators.
- Dependencies: Stable preference labels; scalable training pipelines; mitigation of evaluator/judge bias.
- Public-Sector Transparency — Reasoning Trace Archives
- Vision: Store critiques, decisions, and refined prompts as auditable records for public communication and accountability.
- Dependencies: Policy alignment; standardized reporting formats; privacy safeguards.
Key Assumptions and Dependencies (across applications)
- Availability of high-quality T2V (with audio) and MLLM-as-a-judge with robust video understanding.
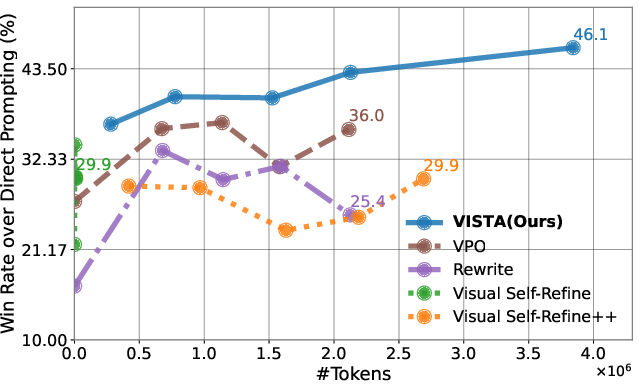
- Sufficient test-time compute: the paper reports ~0.7M tokens and ~28 videos per iteration; costs must be budgeted or constrained.
- Reliability and bias management in evaluators: judge prompts, bidirectional comparisons, and probing critiques reduce bias but do not eliminate it.
- Domain accuracy and legal compliance in regulated sectors (healthcare, finance, safety training) require human oversight and review.
- Content policies, brand safety rules, and regional regulations must be encoded in configurable metrics and penalties.
- IP rights, watermarking, and authenticity controls for generated media; mechanisms for disclosure and attribution.
Glossary
- ACVUBench: An audio-centric video understanding benchmark used to evaluate multimodal systems. "Audio-visual extensions like TAVGBench \citep{mao2024tavgbench} and ACVUBench \citep{yang2025audiocentricvideounderstandingbenchmark} illustrate complementary but rigid approaches:"
- Adversarial Judge: A critique role that intentionally probes and challenges outputs to expose flaws against defined metrics. "an Adversarial Judge which generates probing questions, counterarguments, and scores to expose video flaws on 's metrics,"
- Aesthetic Quality: A conventional metric assessing the visual appeal and style of generated content. "particularly in Dynamic Degree, Aesthetic Quality, and Temporal Style."
- Audio Fidelity: The accuracy, clarity, and overall quality of audio in generated videos. "Audio: Audio Fidelity, Audio-Video Alignment, Audio Safety."
- Audio Safety: Evaluation of whether audio contains harmful or unsafe content. "Audio: Audio Fidelity, Audio-Video Alignment, Audio Safety."
- Audio-Video Alignment: The coherence and synchrony between audio elements and visual events. "Audio: Audio Fidelity, Audio-Video Alignment, Audio Safety."
- Binary Tournaments: A selection method that compares candidates in pairs and advances winners until one remains. "we iteratively reduce the set of candidate videos via Binary Tournaments \citep{miller1995genetic}."
- Black-box prompt optimization: Improving model outputs by refining prompts without accessing or modifying the model’s internals. "VISTA combines these directions and is the first to explore black-box prompt optimization for video generation."
- Chain-of-thought: Explicit, step-by-step reasoning generated by a model to structure decisions or revisions. "suggest prompt modifications in one chain-of-thought:"
- CLIP-Score: A text–vision alignment metric based on CLIP embeddings that measures how well visuals match a caption. "CLIP-Score \citep{hessel-etal-2021-clipscore}"
- Deep Thinking Prompting Agent: An introspective reasoning agent that analyzes critiques and systematically rewrites prompts. "via a Deep Thinking Prompting Agent (DTPA)."
- Dynamic Degree: A metric characterizing the richness and realism of motion dynamics in video. "particularly in Dynamic Degree, Aesthetic Quality, and Temporal Style."
- Embedding similarity: Similarity in learned vector representations (e.g., audio and video) used for alignment or evaluation. "the former emphasizes embedding similarity without failure-focused reasoning,"
- Fréchet Inception Distance (FID): A generative quality metric comparing feature distributions of generated and real samples. "FID \citep{heusel2017gans}"
- Inception Score (IS): A generative quality metric gauging object recognizability and diversity via a classifier. "Inception Score (IS) \citep{salimans2016improved}"
- Jury Decision Process: A formal decision-making framework inspiring the multi-judge critique setup. "inspired by the Jury Decision Process \citep{klevorick1979model}"
- Meta Judge: The aggregator that consolidates the normal and adversarial judges’ assessments into final scores and critiques. "a Meta Judge that consolidates the judges from both sides:"
- MLLM-as-a-Judge: Using a multimodal LLM to evaluate and compare videos against criteria. "we employ an MLLM-as-a-Judge to evaluate videos on customizable evaluation criteria ."
- Multi-Dimensional Multi-Agent Critiques (MMAC): A three-judge framework across Visual, Audio, and Context that produces failure-sensitive critiques. "we introduce Multi-Dimensional Multi-Agent Critiques (MMAC)"
- Multi-modal LLM (MLLM): A LLM that processes multiple modalities (e.g., text, images, video, audio). "A multi-modal LLM (MLLM) is used to obtain "
- NISQA: A non-intrusive speech quality assessment suite for evaluating audio (e.g., noisiness, discontinuities). "three audio metrics from NISQA \citep{mittag21_interspeech}."
- Pairwise Tournament Selection: A binary, bidirectional comparison procedure to select the best video–prompt pair. "Pairwise Tournament Selection (PairwiseSelect)"
- Pareto optimization: Improving multiple objectives jointly such that no dimension can improve without worsening another. "reflects the VISTA's Pareto optimization of multiple video dimensions,"
- Physical Commonsense: Evaluation of whether videos adhere to intuitive physical laws and constraints. "Context: Situational Appropriateness, Semantic Coherence, Text-Video Alignment, Physical Commonsense, Engagement, Video Format (Beginning, Ending, Transitions)."
- Prompt Optimization: Systematic refinement and rewriting of prompts to improve generated outputs. "Prompt Optimization (\Cref{alg:mavpo}-L6)."
- Situational Appropriateness: Judging whether content is suitable and contextually appropriate for the scenario. "Context: Situational Appropriateness, Semantic Coherence, Text-Video Alignment, Physical Commonsense, Engagement, Video Format (Beginning, Ending, Transitions)."
- State-of-the-art (SOTA): The most advanced, high-performing models or methods available at a given time. "with SOTA models such as Sora and Veo 3 receiving widespread attention--"
- Structured Video Prompt Planning: Decomposing a prompt into timed scenes with properties across context, visuals, and audio. "Structured Video Prompt Planning (\Cref{alg:mavpo}-L1)."
- TAVGBench: A benchmark for audio–visual generation and alignment. "Audio-visual extensions like TAVGBench \citep{mao2024tavgbench} and ACVUBench \citep{yang2025audiocentricvideounderstandingbenchmark} illustrate complementary but rigid approaches:"
- Temporal Consistency: The stability and coherence of scenes and objects across time. "Visual: Visual Fidelity, Motions and Dynamics, Temporal Consistency, Camera Focus, Visual Safety."
- Temporal scene-level decomposition: Structuring prompts into semantically coherent, temporally grounded segments to support complex reasoning. "(i) temporal scene-level decomposition, where user prompts are structured as semantically coherent segments to support reasoning over complex content,"
- Temporal Style: Consistency and characteristics of stylistic elements over the video’s duration. "particularly in Dynamic Degree, Aesthetic Quality, and Temporal Style."
- Test-time optimization: Optimization performed during inference, without retraining or fine-tuning the model. "Existing test-time optimization methods, successful in other domains, struggle with the multi-faceted nature of video."
- Text-Video Alignment: The degree to which video content matches the semantics of the input text prompt. "Visual Fidelity, Motions, Temporal Consistency (scene level), Text-Video Alignment, Audio Quality, Audio-Video Alignment, Situational Appropriateness, Physical Commonsense, Engagement, and Video Format (beginning, ending, transitions)."
- Token biases: Unwanted effects arising from token order or position, influencing model judgments. "We swap the videos to avoid token biases \citep{zheng2024large}."
- Triadic court: The three-judge structure (Normal, Adversarial, Meta) used for robust multi-dimensional critiques. "for each evaluation dimension , we construct a triadic court consisting of a Normal Judge"
- VBench: A multi-dimensional video evaluation benchmark and metric suite. "eight visual metrics from VBench \citep{Huang_2024_CVPR}"
- Video Format: Structural aspects of videos such as beginnings, endings, and transitions. "Context: Situational Appropriateness, Semantic Coherence, Text-Video Alignment, Physical Commonsense, Engagement, Video Format (Beginning, Ending, Transitions)."
- Video Generation Agent: The agent that interfaces with the text-to-video model to produce videos. ": Video Generation Agent."
- Visual Fidelity: The realism and visual accuracy of generated content. "Visual: Visual Fidelity, Motions and Dynamics, Temporal Consistency, Camera Focus, Visual Safety."
- Visual Safety: Assessment of whether visual content is safe and non-harmful. "Visual: Visual Fidelity, Motions and Dynamics, Temporal Consistency, Camera Focus, Visual Safety."
Collections
Sign up for free to add this paper to one or more collections.