- The paper introduces the KineMask framework that combines low-level kinematic control and high-level textual conditioning to generate realistic object interactions.
- It employs a two-stage training strategy with synthetic data and velocity mask dropout to effectively learn and control object motion trajectories.
- Experimental results demonstrate significant improvements in motion fidelity, object consistency, and causal interaction generation compared to existing VDMs.
Physics-Guided Video Diffusion for Object Interaction Generation: The KineMask Framework
Introduction
The paper "Learning to Generate Object Interactions with Physics-Guided Video Diffusion" (2510.02284) presents KineMask, a novel framework for synthesizing physically plausible object interactions in video generation using Video Diffusion Models (VDMs). The approach addresses the limitations of existing VDMs, which often fail to generate realistic rigid-body dynamics and lack mechanisms for physics-grounded control. KineMask introduces a two-stage training strategy leveraging synthetic data and integrates both low-level kinematic control and high-level textual conditioning, enabling the generation of complex object interactions from a single input image and user-specified object velocity.

Figure 1: KineMask results. Object-based control and synthetic data enable pretrained diffusion models to synthesize realistic object interactions in real-world scenes.
Methodology
Video Diffusion Model Conditioning
KineMask builds upon the CogVideoX backbone, extending it with a ControlNet branch for dense conditioning. The model is trained to generate videos conditioned on a reference image, a velocity mask encoding instantaneous object motion, and a textual description of the scene dynamics. The velocity mask is a three-channel tensor representing per-pixel velocity vectors for each object, facilitating fine-grained control over motion trajectories.
Two-Stage Training Strategy
The training procedure consists of two stages:
- First-Stage Training: The ControlNet is trained with full supervision, using velocity masks for all frames in synthetic videos rendered in Blender. This enables the model to learn structured guidance for object motion.
- Second-Stage Training (Mask Dropout): To simulate realistic inference conditions, the model is fine-tuned with truncated velocity masks, where only the initial frame contains velocity information and subsequent frames are zeroed. This forces the model to infer future object interactions from initial conditions alone.
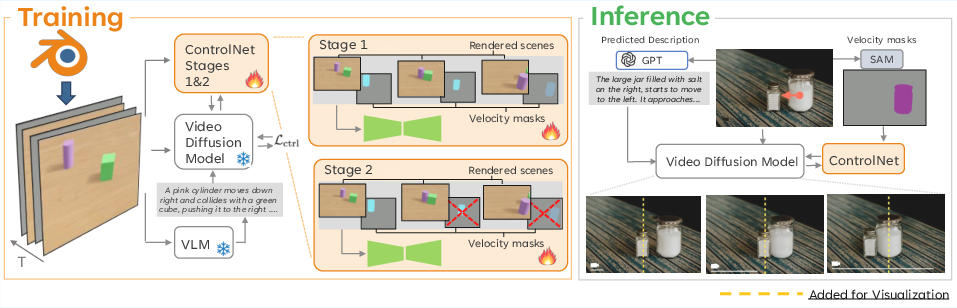
Figure 2: KineMask pipeline. Low-level control via velocity masks and high-level textual conditioning are combined in a two-stage training regime using synthetic Blender videos.
Data Generation and Conditioning
Synthetic datasets are generated with cubes and cylinders on textured surfaces, with randomized initial velocities and directions. Two datasets are constructed: Simple Motion (isolated object motion) and Interactions (multi-object collisions). High-level textual descriptions are extracted using a vision-LLM (VLM) for training, and GPT-5 is used at inference to predict scene outcomes based on the initial frame and velocity.
Inference Pipeline
At inference, the user provides an input image and desired object velocity. Object masks are extracted using SAM2, and GPT-5 generates a textual description of expected scene dynamics. The model synthesizes videos by denoising from random noise, conditioned on the image, velocity mask, and text prompt.
Experimental Results
Qualitative and Quantitative Evaluation
KineMask demonstrates substantial improvements over baselines (CogVideoX, Wan, Force Prompting) in both synthetic and real-world scenarios. The model generates realistic object interactions, preserves motion direction, and maintains object consistency, outperforming baselines that suffer from hallucinations and incorrect dynamics.

Figure 3: Qualitative comparison with CogVideoX. KineMask generates realistic object interactions, including collisions and causal effects, while CogVideoX exhibits hallucinations and motion errors.
User studies with 30 participants confirm KineMask's superiority in motion fidelity, interaction realism, and physical consistency.
Low-Level Motion Control
Ablation studies isolate the effects of low-level conditioning. The two-stage training strategy significantly boosts performance metrics (MSE, FVD, FMVD, IoU) compared to direct training or baselines. The model supports control over direction, speed, and object selection, enabling diverse world modeling scenarios.












Figure 4: Analysis on low-level motion control. KineMask enables control over direction, speed, and object, with quantitative gains from two-stage training.
Impact of Training Data
Training on interaction-rich synthetic data is critical for generalization to real-world scenes. Models trained only on Simple Motion fail to generate realistic collisions, while those trained on Interactions produce plausible multi-object dynamics.

Figure 5: Impact of training data. Interactions data enables realistic collisions and plausible motion, while Simple Motion leads to hallucinations.
Emergence of Causality
KineMask captures causal relationships in object motion, with outcomes varying according to initial velocity, supporting informed planning and world modeling.
High-Level Text Conditioning
Incorporating rich textual descriptions during training enables the model to exploit VDM priors and generate effects beyond the synthetic training distribution, such as glass shattering or liquid spilling.

Figure 6: Impact of text. Training with rich captions allows KineMask to generate complex effects, leveraging VDM prior knowledge.
Quantitative results show improved object consistency and overall realism when using high-level text conditioning.
Robustness and Failure Modes
KineMask's mask-based control is robust to ambiguous scenes with overlapping objects, outperforming Force Prompting, which suffers from hallucinations due to ambiguous control signal mapping.






Figure 7: Motion control comparison. Mask-based control in KineMask is robust to ambiguous scenes, while Force Prompting fails in such cases.
Failure cases include scenarios with low object height or complex multi-object arrangements, leading to missed collisions or object duplication.












Figure 8: Failure Cases. Examples include ignored collisions and object ambiguities in complex scenes.
Implementation Considerations
- Computational Requirements: Training requires synthetic data generation (Blender), VDM backbone (CogVideoX), and ControlNet integration. Mixed precision (bf16) and batch sizes of 40 are used.
- Data Annotation: Velocity masks and textual descriptions are generated automatically, minimizing manual annotation.
- Inference: Object masks can be extracted with SAM2; textual conditioning is generated via GPT-5 with in-context learning.
- Scalability: The approach generalizes from synthetic to real-world scenes, but further scaling may require more diverse synthetic scenarios and richer physical parameterization (e.g., friction, mass).
- Limitations: Current conditioning is limited to velocity; real-world dynamics depend on additional factors. Textual prompts may introduce ambiguity in complex scenes.
Implications and Future Directions
KineMask advances the controllability and physical plausibility of video generation, with direct applications in robotics, embodied decision making, and world modeling. The integration of low-level kinematic control and high-level textual conditioning demonstrates the complementary roles of multimodal guidance in VDMs. Future work should explore conditioning on additional physical parameters, richer multimodal prompts, and scaling to more complex environments. Advances in multimodal LLMs may further enhance text-based physical reasoning and video synthesis.
Conclusion
KineMask establishes a robust framework for physics-guided video generation, enabling realistic object interactions and effects from initial conditions and textual prompts. The two-stage training strategy, synthetic data generation, and multimodal conditioning yield significant improvements over existing models. The methodology provides a foundation for future research in physically grounded world modeling and controllable video synthesis, with broad implications for AI-driven simulation and planning.