- The paper introduces a unified PyTorch framework that integrates over 1,000 pretrained backbones to support diverse visual tasks.
- Its modular design separates the encoding process from task-specific heads, optimizing classification, face recognition, and retrieval.
- The framework supports scalable training and deployment with YAML-configured workflows, elastic distributed training, and exportable model formats.
DORAEMON: A Unified Library for Visual Object Modeling and Representation Learning at Scale
The paper presents DORAEMON, a comprehensive PyTorch-based framework designed to streamline large-scale visual object modeling and representation learning. This unified library encapsulates a broad array of tasks inherently tied to visual data such as classification, face recognition, and image retrieval, integrating over 1,000 pretrained backbones and offering robust deployment capabilities.
Unified Approach to Visual Representation
DORAEMON addresses key challenges in visual modeling, including fragmented codebases and inconsistent training practices, by providing a cohesive framework facilitating seamless integration of various datasets, model architectures, and loss functions.
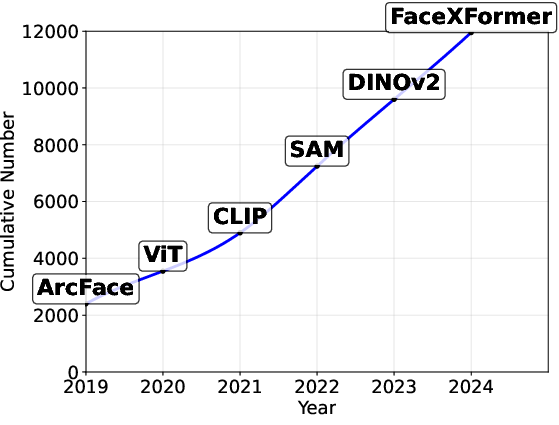
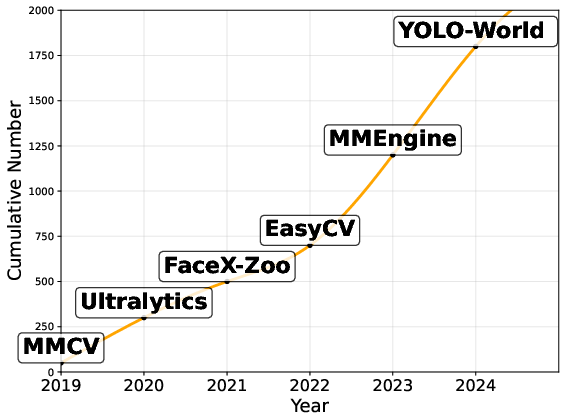
Figure 1: The trends of large-scale visual object modeling (2019 - 2024).
DORAEMON's unified training pipeline is inherently modular, supporting configurable components such as data processing, loss functions, and optimization strategies, all governed by a YAML-defined framework. This systematic approach not only enhances reproducibility but also accelerates experimentation across diverse cognitive domains.
Technical Architecture
The core of DORAEMON is its unified backbone architecture, which serves as a foundational encoder for diverse visual tasks. The framework strategically separates representation learning from task-specific prediction heads, where each task is linked to a lightweight head optimized with task-relevant losses. This modularity translates into a highly adaptable system that can accommodate a range of downstream applications:
- Image Classification uses softmax classifiers optimized via cross-entropy loss, foundational to supervised learning.
- Face Recognition leverages metric learning objectives such as ArcFace and CircleLoss, focusing on intra-class compactness and inter-class separability.
- Content-Based Image Retrieval (CBIR) employs triplet or contrastive losses to maintain semantic proximity in the embedding space.
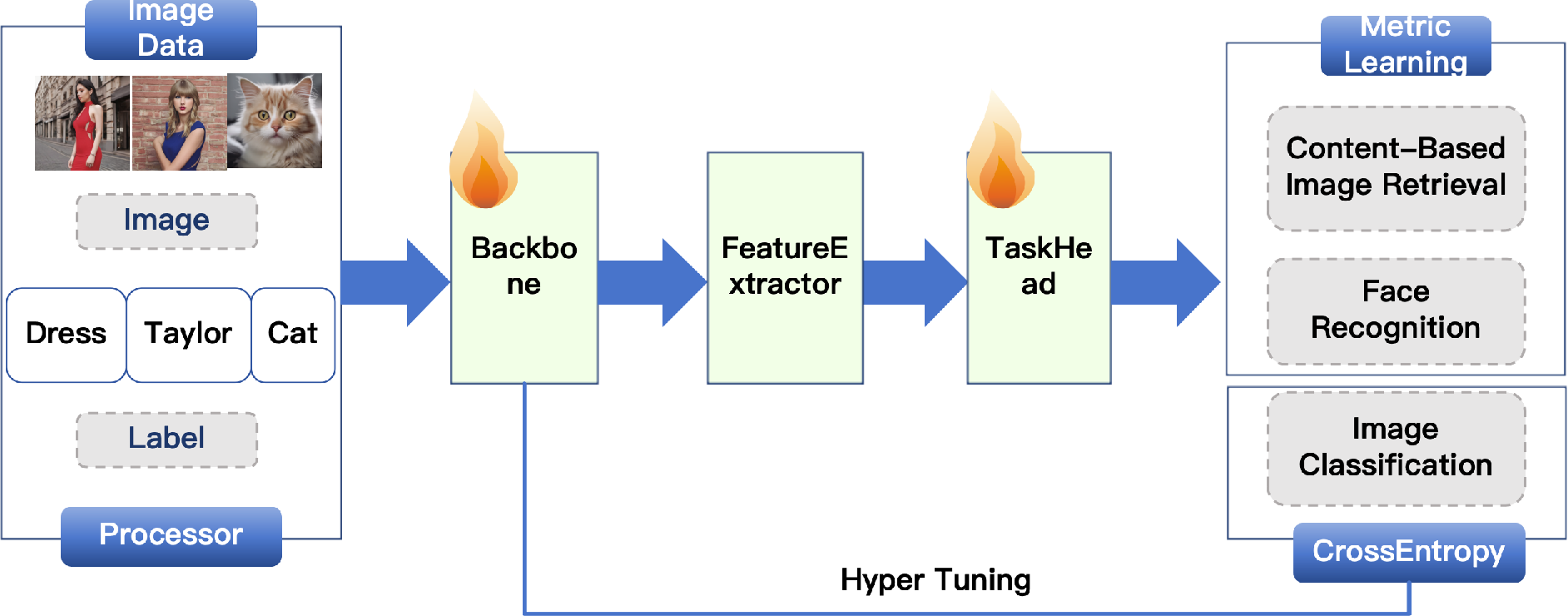
Figure 2: Unified training pipeline of DORAEMON. The framework uses a shared visual backbone with modular task heads for classification, face recognition, and retrieval. Data processing, loss functions, and optimization are all configurable via YAML for scalable deployment.
This architecture is supported by an extensive set of pretrained models accessible via the timm library, encompassing popular designs like ResNet, Swin Transformer, and Vision Transformer, thereby facilitating scalable pretraining, fine-tuning, and evaluation processes.
Scalable Integration and Deployment
DORAEMON is engineered for scalability, enabling effortless integration of new methods and extending its utility from academia to industry applications. The library features elastic distributed training and hassle-free model export to formats such as ONNX and TorchScript, promoting wide-ranging deployment scenarios.
The interpretability tools embedded within, such as built-in Grad-CAM visualizations, empower researchers to conduct qualitative analyses of learned representations without additional configuration. Furthermore, integration with HuggingFace accelerates deployment in production environments.
Future Directions and Implications
Future enhancements for DORAEMON aim to encompass advanced capabilities such as agent-based integration for extended functionalities and multimodal LLM frameworks supporting continuous multimodal pretraining and prompt-based tuning across modalities. These innovations are poised to further bridge the gap between robust visual recognition systems and intelligent, decision-aware multimodal frameworks.
Conclusion
DORAEMON stands as a pivotal tool in large-scale visual object modeling, offering a structured and efficient methodology for tackling various visual learning tasks. Its modular design, combined with a comprehensive set of ready-to-use workflows and pretrained models, facilitates accelerated research developments while laying down robust pathways for future expansions into multimodal AI. The inclusion of scalable training and deployment solutions underscores its significance as both a research enabler and a practical solution for real-world applications.