Kosmos: An AI Scientist for Autonomous Discovery
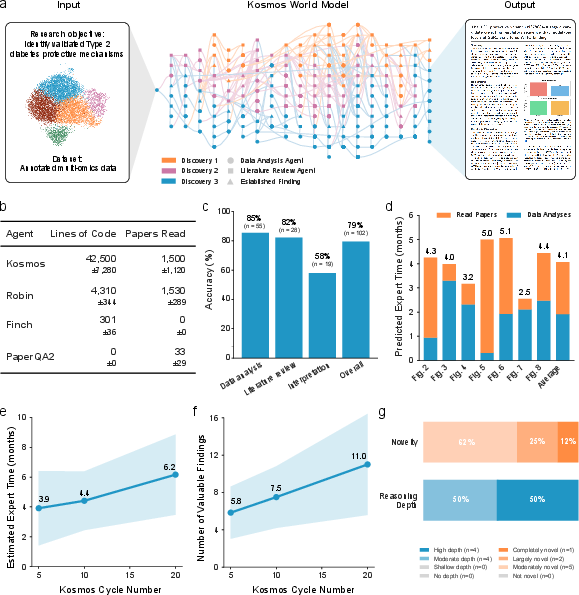
Abstract: Data-driven scientific discovery requires iterative cycles of literature search, hypothesis generation, and data analysis. Substantial progress has been made towards AI agents that can automate scientific research, but all such agents remain limited in the number of actions they can take before losing coherence, thus limiting the depth of their findings. Here we present Kosmos, an AI scientist that automates data-driven discovery. Given an open-ended objective and a dataset, Kosmos runs for up to 12 hours performing cycles of parallel data analysis, literature search, and hypothesis generation before synthesizing discoveries into scientific reports. Unlike prior systems, Kosmos uses a structured world model to share information between a data analysis agent and a literature search agent. The world model enables Kosmos to coherently pursue the specified objective over 200 agent rollouts, collectively executing an average of 42,000 lines of code and reading 1,500 papers per run. Kosmos cites all statements in its reports with code or primary literature, ensuring its reasoning is traceable. Independent scientists found 79.4% of statements in Kosmos reports to be accurate, and collaborators reported that a single 20-cycle Kosmos run performed the equivalent of 6 months of their own research time on average. Furthermore, collaborators reported that the number of valuable scientific findings generated scales linearly with Kosmos cycles (tested up to 20 cycles). We highlight seven discoveries made by Kosmos that span metabolomics, materials science, neuroscience, and statistical genetics. Three discoveries independently reproduce findings from preprinted or unpublished manuscripts that were not accessed by Kosmos at runtime, while four make novel contributions to the scientific literature.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Kosmos, a computer system designed to act like an “AI scientist.” Its job is to help discover new scientific ideas from data. It does this by:
- reading lots of research papers,
- writing and running code to analyze data,
- forming and testing hypotheses (ideas about how things work),
- and finally, writing a scientific report with sources and code so others can check its work.
The big idea: Kosmos can work for many hours in a row, across different fields (like biology, materials science, and neuroscience), and stay focused on a research goal—something most AI systems struggle to do over long, complex projects.
Research Questions
In simple terms, the researchers wanted to know:
- Can an AI scientist run many steps in a row without losing track of the goal?
- Can it combine what it reads (from papers) with what it finds (from data) to make accurate discoveries?
- Can it save scientists time and scale up—meaning, if you let it run longer, does it discover more?
- Can it make real contributions across different areas, like medicine, brain science, and solar cells?
How Kosmos Works
Think of Kosmos as a team:
- A data analysis agent writes and runs code to test ideas on a dataset.
- A literature search agent reads and summarizes scientific papers related to the topic.
- A shared “world model” is like a big, organized notebook. It stores what’s been learned so far and helps the agents stay coordinated.
Kosmos runs in cycles, like rounds in a game:
- It plans several small tasks (some are data analysis, some are paper reading).
- It does those tasks in parallel.
- It updates the world model with what it found.
- It uses that shared knowledge to plan the next round of tasks.
After many cycles (sometimes up to 12 hours), Kosmos writes a scientific report. Every claim in the report links to the code that produced it or to a paper it read, so you can trace the reasoning.
How they checked Kosmos:
- Expert scientists read statements from Kosmos’s reports. About 79% were accurate overall. Data-based claims were strongest (about 86% accurate), literature-based claims were also strong (about 82%), while “interpretation” statements (mixing data and papers into new ideas) were correct less often (about 58%).
- They estimated how much human time Kosmos replaced. A single run looked like months of expert work. Collaborators said a 20-cycle run was similar to about 6 months of their research time on average.
- Longer runs produced more valuable findings. The number of useful discoveries grew as Kosmos did more cycles.
What Did They Find?
Here are a few examples of what Kosmos discovered or reproduced across different fields. Each bullet introduces a case study and why it matters.
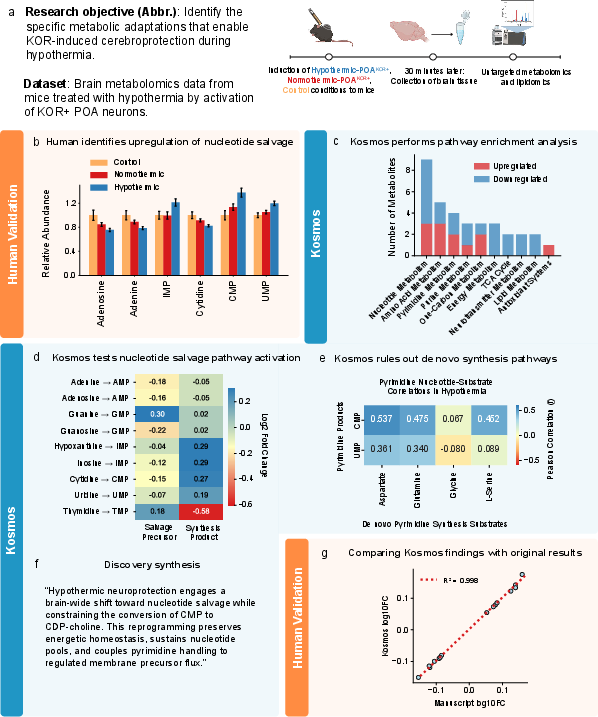
- Brain protection during cooling (metabolomics):
- Goal: Understand how cooling protects the brain in mice.
- What Kosmos found: The biggest changes were in “nucleotide salvage,” a way cells recycle building blocks for DNA/RNA to save energy. This matched an unpublished human study using the same data.
- Why it matters: It points to an energy-saving program during brain cooling that might protect cells, helping us understand and potentially improve treatments that use controlled cooling.
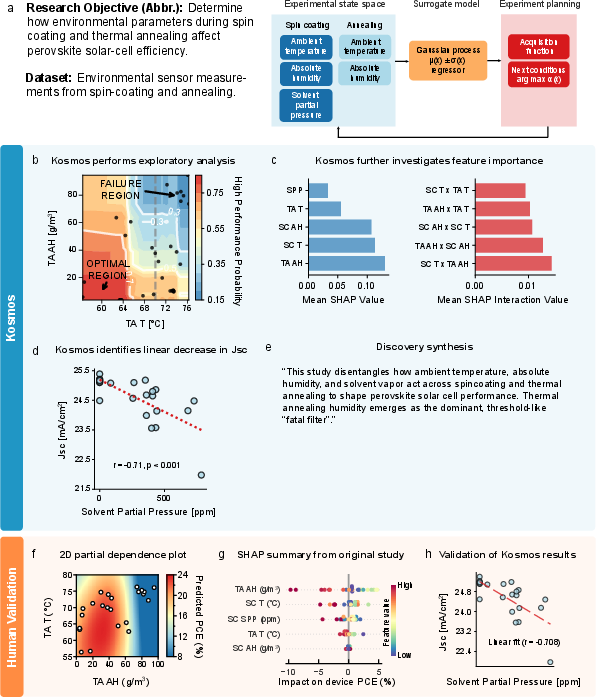
- Solar cell manufacturing (materials science):
- Goal: Figure out which environment settings during fabrication affect perovskite solar cell performance.
- What Kosmos found: The humidity during the “thermal annealing” step is critical—too much humidity at certain temperatures causes devices to fail. Kosmos also found a new, simple relationship: as the solvent pressure of DMF increases during spin-coating, a key performance measure (short-circuit current) goes down linearly. Researchers later confirmed this.
- Why it matters: Clear “do and don’t” rules help make solar cells more reliably and efficiently, which is important for clean energy.
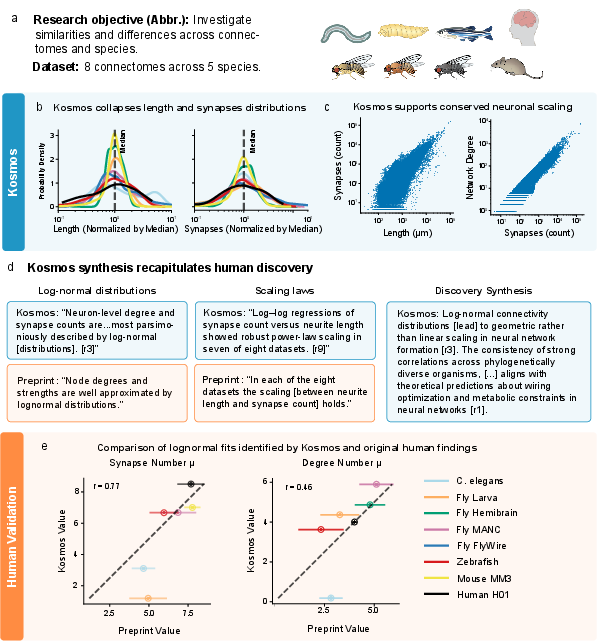
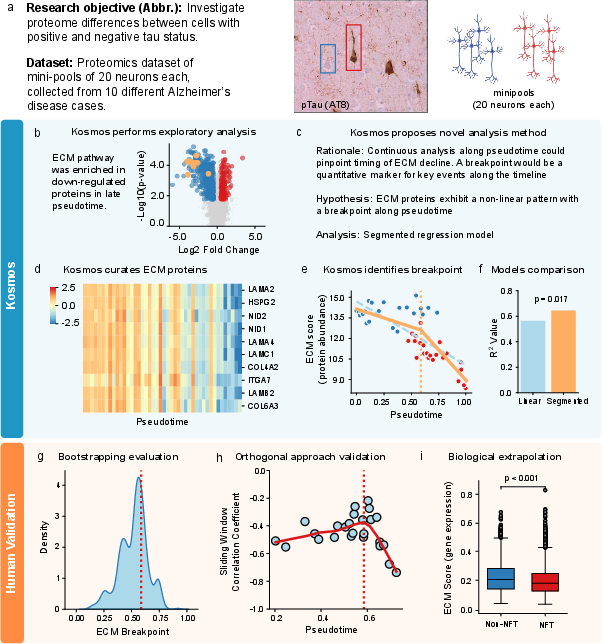
- Neuron networks (connectomics):
- Goal: Find universal patterns in how neurons connect across different animals.
- What Kosmos found: The number of connections and synapses per neuron follows a log-normal pattern (most neurons have a medium amount, a few have a lot, very few have very little). It also found scaling rules between neuron length and synapse count. These matched an existing preprint—even when Kosmos wasn’t allowed to access it.
- Why it matters: Recognizing these patterns helps explain how brains organize themselves and how complex networks arise in biology.
- Heart scarring (cardiology and genetics):
- Goal: Identify proteins that might cause or protect against myocardial fibrosis (scar-like thickening in the heart).
- What Kosmos found: Higher genetically predicted levels of SOD2 (an antioxidant enzyme) likely reduce heart fibrosis. Its results closely matched an independent human analysis. Kosmos suggested a possible mechanism too, though that part needs more lab testing.
- Why it matters: This could point to new treatments to prevent or reduce heart scarring, helping patients with heart failure.
- Type 2 Diabetes risk (human genetics):
- Goal: Explain how protective DNA variants lower risk of Type 2 Diabetes by affecting nearby genes.
- What Kosmos found: It prioritized a variant near the SSR1 gene and proposed a mechanism for how it could change gene activity to reduce risk. It backed this up by checking multiple data sources and doing enrichment tests for relevant transcription factors.
- Why it matters: Turning statistical DNA signals into real, testable biological mechanisms speeds up the path to therapies.
In total, the paper highlights seven discoveries. Some matched unpublished or very papers Kosmos could not access, showing independent reasoning. Others were novel contributions, moving beyond what human researchers had done.
Why It Matters
- Faster science: Kosmos can do many hours of coordinated work—reading papers, writing and running code, and synthesizing results. Collaborators said a single run often felt like months of human research.
- Breadth and depth: It works across different scientific areas and can keep track of complex goals over many steps.
- Transparency: Every claim in its reports is linked to code or a paper, making it easier for others to verify the work.
- Scaling: When Kosmos runs more cycles, it tends to produce more valuable findings, suggesting that investing computing time can yield more scientific output.
Caveats:
- Kosmos is not perfect. Its “interpretation” claims are less accurate than its straight data or literature claims, and it can run into technical issues with certain pipelines.
- Human experts are still needed to check results, confirm mechanisms, and run lab experiments.
- Good data matters. Some conclusions require special kinds of measurements (for example, time-resolved data to prove how fast a pathway runs).
Bottom line: Kosmos shows that AI can help push science forward by handling large amounts of information, exploring many ideas in parallel, and producing traceable, testable reports. Used alongside human experts, it could speed up discoveries in medicine, energy, and neuroscience, and help turn big datasets into real-world insight.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the paper’s unresolved issues—what is missing, uncertain, or left unexplored—phrased concretely so future researchers can act on them.
- World model specification and governance: The schema (entities/relations), update rules, conflict resolution, and persistence strategy for the “structured world model” are not described; release a formal ontology, data model, and consistency/integrity checks, and evaluate how these design choices affect coherence over 200+ rollouts.
- Ablation and causal attribution: No ablation studies isolate the contribution of the world model vs. parallelization vs. LLM choice; run controlled experiments to quantify each component’s effect on accuracy, novelty, and scaling.
- Planning and task allocation policy: The agent orchestration (how up to 10 tasks per cycle are chosen) is heuristic; evaluate formal planners (e.g., POMDPs, bandits) for exploration–exploitation trade-offs and objective alignment.
- Robustness across LLMs and versions: Apart from one Sonnet 4 vs. 4.5 check in a single case, sensitivity to LLM choice, temperature, tool-use prompts, and context window size is untested; perform systematic cross-model robustness studies.
- Compute, cost, and scalability: Runtime, GPU/CPU usage, token throughput, memory footprint, and monetary costs are not quantified; benchmark resource scaling beyond 12 hours/200 rollouts and identify bottlenecks.
- Error accumulation and world-model drift: The system’s resilience to hallucinations, contradictory entries, and stale information over long runs is unvalidated; implement and test drift detection, provenance-based pruning, and contradiction resolution.
- Provenance and citation verification: Evaluators did not access the original code or cited papers; release reproducible bundles (code, environments, notebooks, data snapshots) and perform independent third-party audits of citations and analyses.
- Literature intake quality: Reading “1,500 papers” per run lacks measures of comprehension, redundancy, and coverage bias; quantify extraction accuracy, deduplication, domain coverage, and the impact of low-quality/irrelevant sources.
- Uncertainty quantification: Synthesis statements have 57.9% accuracy; add calibrated uncertainty estimates, evidence grading, and counterfactual checks for integrative claims.
- Failure handling in pipelines: Cascading technical failures (e.g., colocalization: zero p-values, missing SD/MAF, column collisions) indicate inadequate data hygiene; add schema validation, robust defaults, and automatic repair/fallback strategies with audit trails.
- Statistical QA standards: Misuse of Kolmogorov–Smirnov tests (distribution collapse contradicted by pairwise tests) and known failure modes in power-law fitting led to erroneous or unstable inferences; adopt vetted statistical protocols, cross-fitting, and multiple-method triangulation.
- Generalization across domains: The case studies span several fields but lack a statistically powered, multi-domain benchmark; construct standardized cross-disciplinary test suites with ground truth to assess generality and limits.
- Novelty assessment rigor: Novelty and reasoning depth were rated subjectively by collaborators; integrate bibliometric prior-art detection, novelty scoring, and independent blinded panels to reduce bias.
- Human-evaluation bias: “Leading academic groups” evaluated outputs and may have engagement bias; run preregistered, blinded, multi-lab evaluations with standardized rubrics and inter-rater reliability analyses.
- Time-savings model validity: The expert time estimates (15 min/paper, 2 h/notebook) are assumptions; validate with time–motion studies across disciplines and task types, and model heterogeneity.
- Scaling returns and limits: Reported linear scaling of “valuable findings” up to 20 cycles lacks analysis beyond that point; test for diminishing returns, error compounding, and optimal stopping criteria.
- Integration with wet-lab automation: Kosmos does not design or execute wet-lab experiments; define interfaces to experimental planning, lab automation, and closed-loop validation to complete the discovery cycle.
- Ethical, safety, and governance: Risks (biased literature, dual-use insights, clinical claims without validation, data privacy) are unaddressed; implement safety filters, bias audits, stakeholder review, and disclosure policies.
- Data access and IP considerations: Reading full papers at scale raises licensing and rights questions; clarify data access methods, rights management, and reproducibility across institutions with differing subscriptions.
- Reproducibility infrastructure: Environment versioning, containerization, random seeds, and data snapshots are not documented; provide complete reproducibility artifacts (Docker/Conda, data hashes, seeds, OS specs).
- Code quality and reliability: “42,000 lines of code” is reported without tests or reliability metrics; add unit/integration tests, runtime error tracking, code coverage, and post-hoc static analysis.
- Benchmarking against baselines: Comparisons to prior agents (Robin, Sakana) emphasize iteration counts but not output quality on shared tasks; establish common tasks and metrics to compare accuracy, novelty, and robustness.
- Objective alignment and drift: How Kosmos stays aligned with broad objectives over long runs is unclear; measure objective fidelity, detect drift, and enforce alignment constraints in task proposals.
- Domain-specific methodological gaps (metabolomics): Flux inference was attempted from steady-state LC–MS data; integrate isotope tracing or time-series data to resolve salvage vs. de novo pathway activity.
- Domain-specific methodological gaps (materials): SHAP/partial dependence insights lack uncertainty bounds and prospective replication; plan controlled fabrication experiments to confirm thresholds (e.g., humidity “fatal filter”) and interaction effects.
- Domain-specific methodological gaps (connectomics): Heavy-tailed fits produced nonsensical parameters (negative μ) in some datasets; adopt robust distribution fitting (e.g., Bayesian hierarchical models) and goodness-of-fit diagnostics across species/datasets.
- Domain-specific methodological gaps (MR genetics—SOD2): Colocalization failure and reliance on SuSiE require broader sensitivity analyses; add MR-Egger, CAUSE, HEIDI tests, and pleiotropy diagnostics, with multi-cohort replication.
- Mechanism inference (SOD2 miRNA): The rs4555948–miR-222 binding claim conflicts with current databases; conduct wet-lab assays (luciferase reporter, CLIP-seq) and refine variant-to-function annotation pipelines (cis-regulatory mapping, RBP/miRNA motif libraries).
- SSR1/T2D locus (Discovery 5): The mechanistic prioritization framework is introduced but lacks causal validation; perform CRISPR perturbations, allele-specific expression, colocalization across tissues, and replication in diverse ancestries.
- Data quality and harmonization: Pipeline failures suggest upstream data inconsistencies; enforce standardized schemas (GWAS, eQTL, pQTL), metadata completeness (MAF, SD), and harmonization protocols across sources.
- Interoperability of the world model: No examples of schema interchange or integration with external knowledge graphs; evaluate interoperability (e.g., RDF/OWL, KG embeddings) and portability between projects.
- Transparency of agent prompts and policies: Prompts and decision policies are not fully disclosed; publish prompt templates, tool-use policies, and guardrails to enable replication and scrutiny.
- Uncertainty-aware reporting: Reports lack calibrated confidence levels per claim; include probabilistic assessments, evidence grades, and explicit limitations per statement/figure.
- Failure taxonomy and recovery: The paper provides ad hoc examples of failures; build a taxonomy of failure modes (data, code, statistics, literature) and implement automated recovery playbooks with human-in-the-loop escalation.
- Long-run maintenance and updates: How the world model and agents handle updates to datasets and literature is unspecified; study versioning, change detection, and incremental re-analysis strategies.
- User studies and collaboration protocols: Human–AI division of labor and accountability are not formalized; design and evaluate collaboration workflows (handoffs, review checkpoints, provenance sign-off).
- Security and misuse prevention: No discussion of safeguards against generating harmful protocols or exploiting vulnerabilities; implement red-teaming, content filters, and controlled-access policies for sensitive domains.
Practical Applications
Immediate Applications
The following use cases can be deployed today based on Kosmos’s demonstrated capabilities: multi-agent orchestration with a structured world model; traceable, code-backed reporting; high-throughput literature ingestion; domain-agnostic data analysis; and reproducible pipelines (e.g., MR, SHAP analysis, enrichment tests).
- Academic R&D accelerator (academia; healthcare; neuroscience; materials)
- What: Run 8–20+ cycle Kosmos sessions on lab datasets to produce exploratory data analyses, literature syntheses, hypotheses, figures, and draft reports with linked notebooks and citations.
- Tools/workflows: “Kosmos-runner” service for PIs; auto-generated Jupyter notebooks; world-model-integrated electronic lab notebook (ELN) add-on.
- Dependencies/assumptions: Clean, well-annotated datasets; compute budget; domain-package availability (e.g., TwoSampleMR, susieR); human-in-the-loop review given ~79% statement accuracy (lower for synthesis).
- Reproducibility auditor for manuscripts and preprints (academia; publishers; funders)
- What: Independent re-analysis of public datasets accompanying a paper/preprint, producing a concordance report (effect sizes, distributional fits, model choices), as shown in connectomics and metabolomics case studies.
- Tools/workflows: “Reproducibility Auditor” pipeline that ingests data + methods, regenerates results, and flags divergence; per-claim traceability.
- Dependencies/assumptions: Data and code availability; standardized metadata; versioned environments; author consent for embargoed datasets.
- Causal-protein and biomarker triage via proteome-wide MR (healthcare; biopharma; diagnostics)
- What: Rapid target nomination and ranking (e.g., SOD2 for myocardial fibrosis) using GWAS/pQTL/TWAS resources with MR, colocalization, and fine-mapping.
- Tools/workflows: “Causal Protein Finder” pipeline (TwoSampleMR, coloc, susieR); auto-generated volcano plots, PP.H4 summaries, mechanism briefs.
- Dependencies/assumptions: High-quality summary stats; instrument validity; LD reference panels; human vetting to resolve colocalization/fine-mapping edge cases.
- Process-window mapping and failure-boundary discovery in manufacturing (materials; energy; semiconductors)
- What: Identify dominant environmental/process parameters and interaction regimes from fab logs (e.g., annealing humidity as “fatal filter” in perovskites).
- Tools/workflows: “Process Window Mapper” with SHAP, partial dependence, and DOE recommendations; alerts for failure thresholds; knowledge capture in the world model.
- Dependencies/assumptions: High-resolution process telemetry; robust labeling of outcomes; data-sharing/IT integration with MES/LIMS.
- Mechanism-focused omics triage (biomedicine; translational research)
- What: Fast EDA for metabolomics, transcriptomics, proteomics with pathway enrichment and mechanistic hypotheses (e.g., nucleotide salvage under hypothermia).
- Tools/workflows: Auto-variance stabilization, differential testing, pathway/GO enrichment, hypothesis canvas tied to primary literature.
- Dependencies/assumptions: Appropriate normalization and QC; access to pathway databases; flux vs steady-state caveats clearly surfaced.
- Cross-domain literature synthesis at scale (academia; policy; R&D strategy)
- What: Read 1,000+ papers/run to produce evidence maps, novelty assessments, and priority lists aligned to a research objective.
- Tools/workflows: “Living Evidence Map” dashboards; world-model summary tables linking claims to sources and code.
- Dependencies/assumptions: Access to paywalled literature (licensing); deduplication and hallucination checks; citation quality control.
- Grant, IRB, and manuscript drafting co-pilot (academia; industry R&D)
- What: Draft aims, methods, preliminary results sections with embedded figures and provenance to accelerate submissions and publications.
- Tools/workflows: “Evidence-to-Report Writer” that compiles code-backed results, figure legends, and citations.
- Dependencies/assumptions: Institutional authorship and AI-use policies; journal/grant compliance; human authors’ oversight.
- Portfolio triage for R&D leaders (industry; venture; translational centers)
- What: Rapid diligence across multiple problem statements/datasets to identify high-potential avenues, with predicted “expert-months” saved and novelty scores (as observed linear scaling with cycles).
- Tools/workflows: Multi-project queue with cycle budgeting; decision memos auto-generated from the world model.
- Dependencies/assumptions: Comparable metrics across projects; governance for prioritization and risk management.
- Education and training in computational research (education; workforce development)
- What: Course labs or lab rotations where Kosmos generates annotated notebooks, reproducible analyses, and critique prompts for students.
- Tools/workflows: “Notebook Tutor” mode with stepwise rationale and references; sandboxed datasets.
- Dependencies/assumptions: Curated datasets; instructor guardrails; academic integrity policies.
- Internal knowledge memory for labs (software; research IT)
- What: Structured world model as a research memory that connects analyses, hypotheses, and sources across projects.
- Tools/workflows: World-model API integrated with ELN/LIMS; entity linking (datasets, tasks, findings).
- Dependencies/assumptions: Schema governance; access control; PII/PHI handling; audit logs.
- Evidence briefs for policy teams (policy; public health; standards bodies)
- What: Topic-focused evidence summaries with traceability (e.g., environmental impacts on manufacturing quality; causal evidence for biomarkers) to inform guidance or standards.
- Tools/workflows: “Policy Brief Builder” from the world model; versioned statements with citation trails.
- Dependencies/assumptions: Transparency standards; conflict-of-interest disclosures; peer review of critical statements.
Long-Term Applications
These use cases are feasible but require advances in reliability, integration, governance, or tooling (e.g., higher synthesis accuracy, wet-lab APIs, regulatory acceptance, standardized provenance).
- Self-driving labs: closed-loop hypothesis → experiment → analysis → redesign (healthcare; materials; robotics)
- What: Kosmos proposes experiments, triggers robotic execution, analyzes results, and iterates autonomously.
- Dependencies/assumptions: Robust lab-automation integration (robotics, LIMS APIs), safety interlocks, experiment planning under constraints, validated active-learning policies, comprehensive provenance.
- Regulatory-grade evidence generation and submissions (healthcare; diagnostics; med devices)
- What: AI-assembled integrated evidence packages (RWE, MR, omics, literature) for pre-INDs, IDEs, reimbursement dossiers.
- Dependencies/assumptions: GxP compliance, model validation, auditability, regulator-aligned standards for AI-assisted analysis.
- Continuous portfolio discovery engines (biopharma; agritech; chemicals)
- What: Always-on scanning of new datasets and literature to propose ranked targets, biomarkers, and mechanisms across therapeutic areas.
- Dependencies/assumptions: Data partnerships; IP frameworks; de-duplication and novelty adjudication; human governance boards.
- Autonomous method development and benchmarking (software; meta-research)
- What: Kosmos invents, tests, and benchmarks new analytical methods across public benchmarks, writing methods papers with executable artifacts.
- Dependencies/assumptions: Gold-standard benchmarks; reproducibility leaders; community acceptance and citation norms for AI-developed methods.
- Living systematic reviews and guideline co-authorship (policy; public health)
- What: Near-real-time updates to clinical and environmental guidelines with continuous ingestion, causal synthesis, and certainty grading.
- Dependencies/assumptions: Methodological guardrails (GRADE-like), expert panels, bias detection, transparent conflict management.
- Factory and fab autotuning across lines (semiconductors; photovoltaics; batteries)
- What: Kosmos generalizes “fatal filter” detection and interaction mapping to multi-line, multi-site environments with automated setpoint recommendations.
- Dependencies/assumptions: Secure industrial data pipelines, digital twins, change-control, union/worker safety considerations.
- Population-scale causal inference for precision health (healthcare; insurers)
- What: Multi-omic MR, colocalization, and TWAS across biobanks to stratify risk and personalize interventions.
- Dependencies/assumptions: Privacy-preserving analytics, federated learning, fairness auditing, clinical validation, payer/regulator buy-in.
- Cross-institution research knowledge graphs and crediting (academia; funders)
- What: Institution-spanning world models that track hypotheses, data lineage, and contributions to attribute credit and reduce duplication.
- Dependencies/assumptions: Interoperable schemas, contributor IDs, IP/licensing agreements, incentive alignment.
- AI co-first-author with accountability frameworks (academia; publishers)
- What: Formalized roles for AI-generated analyses and text with disclosure, version control, and responsibility matrices.
- Dependencies/assumptions: Publisher policies, research-ethics norms, provenance enforcement, model cards and data cards.
- Consumer-facing research assistants for citizen science (daily life; education)
- What: Guided analysis of open datasets (environment, public health, astronomy) for community projects and student research.
- Dependencies/assumptions: Simplified UIs, safety rails, curated datasets, pedagogy-aligned outputs.
- National and corporate horizon scanning (policy; strategy; finance)
- What: Continuous novelty detection and risk/opportunity mapping across disciplines for funding and investment prioritization.
- Dependencies/assumptions: High-quality ingestion pipelines, bias controls, human analyst triage, scenario testing.
- Discovery marketplaces and collaboration brokers (platforms; innovation ecosystems)
- What: Match unsolved problems and datasets with AI-generated hypotheses and teams, with smart contracts for attribution and rewards.
- Dependencies/assumptions: Legal frameworks for IP/provenance, trust/reputation systems, secure data enclaves.
Cross-cutting assumptions and risks
- Data quality, access, and licensing: Outcomes depend on clean, well-described datasets and legal access to literature and proprietary data.
- Model reliability and oversight: Synthesis accuracy is lower than analysis accuracy; human review is critical for high-stakes claims.
- Compute and tooling: Stable access to LLMs, domain libraries, and reproducible environments; cost governance for long runs.
- Governance and ethics: Clear policies for authorship, credit, conflicts, and AI disclosure; audit trails and reproducibility standards.
- Security and privacy: Especially for health and manufacturing data; need for PII/PHI controls and SOC2/ISO compliance where applicable.
Glossary
- 3' UTR: The three-prime untranslated region of an mRNA, often containing regulatory elements that influence post-transcriptional control. "rs4555948 within the SOD2 3'UTR as a credible-set variant predicted to disrupt a hsa-miR-222-3p binding site"
- Absolute humidity: The mass of water vapor per unit volume of air, a critical environmental parameter during materials processing. "absolute humidity during thermal annealing"
- Adenosine Triphosphate (ATP): The primary energy-carrying molecule in cells. "maintaining Adenosine Triphosphate (ATP) levels and nucleotide pools"
- ATAC-seq: Assay for Transposase-Accessible Chromatin using sequencing; measures genome-wide chromatin accessibility. "chromatin accessibility (ATAC-seq)"
- ATF3: Activating Transcription Factor 3; a transcription factor involved in stress responses and gene regulation. "ATF3 ()"
- Bayesian optimization: A probabilistic global optimization method that uses a surrogate model to efficiently explore complex parameter spaces. "a closed-loop Bayesian optimization strategy was applied to efficiently explore and map how these variables influence device outcomes"
- Bonferroni correction: A multiple testing adjustment that controls family-wise error rate by scaling the significance threshold. "Both Kosmos and human analysis applied Bonferroni correction to MR p-values"
- Cardiac magnetic resonance imaging: MRI applied to the heart to quantify tissue properties and pathology. "Native T1 relaxation times measured by cardiac magnetic resonance imaging reflect myocardial tissue composition"
- Chemogenetic tools: Genetically encoded receptors or channels activated by specific chemicals to modulate cell activity. "Using chemogenetic tools, Kamal et al. selectively activated kappa opioid receptor–expressing (KOR) neurons"
- ChIP-seq: Chromatin immunoprecipitation followed by sequencing; maps protein-DNA interactions genome-wide. "ChIP-seq validation rate"
- cis-protein quantitative trait loci (pQTL): Genetic loci near a gene that influence its protein abundance. "cis-protein quantitative trait loci (pQTL)"
- Colocalization: Statistical assessment that two association signals (e.g., GWAS and QTL) share the same causal variant. "The colocalization analysis failed"
- coloc: An R package for Bayesian colocalization analysis of association signals. "coloc for colocalization"
- Connectome: A comprehensive map of neural connections within the brain or nervous system. "connectome reconstructions"
- Credible set: A set of genetic variants with high posterior probability of containing the causal variant in fine-mapping. "a credible set of directionally consistent variants"
- Dimethylformamide (DMF): An organic solvent; its vapor pressure can affect thin-film fabrication. "Dimethylformamide (DMF) solvent partial pressure"
- eQTL: Expression quantitative trait locus; a genetic variant associated with gene expression levels. "expression (eQTL)"
- Enrichr: A web-based tool and database for gene set enrichment analysis. "Enrichr TF-target datasets"
- Fine-mapping: Statistical refinement of association signals to pinpoint likely causal variants. "susieR for fine-mapping"
- Gaussian process regressor: A nonparametric Bayesian model for regression that defines a distribution over functions. "Average PCE (colour scale) predicted by Gaussian process regressor"
- Genome Wide Association Study (GWAS): A study scanning the genome to find variants associated with traits or diseases. "myocardial T1 Genome Wide Association Study (GWAS)"
- Hemodynamic pathway: Physiological processes related to blood flow and pressure that can link molecular changes to cardiac remodeling. "a plausible hemodynamic pathway"
- Hypothermic conditions: Physiological state of reduced body temperature affecting cellular metabolism. "under hypothermic conditions"
- Inosine monophosphate (IMP): A nucleotide intermediate in purine metabolism and salvage pathways. "inosine monophosphate (IMP)"
- Kappa opioid receptor (KOR+): A G protein–coupled receptor subtype; here indicates neurons expressing KOR are targeted. "kappa opioid receptor–expressing (KOR) neurons"
- Kolmogorov-Smirnov tests: Nonparametric tests comparing two empirical distributions. "pairwise Kolmogorov-Smirnov tests"
- Liquid chromatography--mass spectrometry (LC--MS): An analytical technique combining separation and mass analysis to identify and quantify molecules. "liquid chromatography--mass spectrometry (LC--MS) dataset"
- Log-log regressions: Regression analysis performed on logarithmically transformed variables to assess power-law relationships. "Log-log regressions of synapse count versus neurite length"
- Lognormal distributions: Distributions where the logarithm of the variable is normally distributed; often arise from multiplicative processes. "lognormal distributions"
- Medial preoptic area (POA): A brain region involved in thermoregulation and other functions. "medial preoptic area (POA)"
- Mendelian randomization (MR): A causal inference method using genetic variants as instrumental variables. "Mendelian randomization (MR) leverages the random allocation of genetic variants at conception to infer causal relationships"
- Missense variant: A single nucleotide change that results in an amino acid substitution in a protein. "missense variant rs9379084"
- Multiplicative processes: Processes where outcomes result from products of many factors; often yield lognormal distributions. "multiplicative processes can govern neuronal properties"
- Myocardial fibrosis: Fibrotic remodeling of heart muscle that increases stiffness and impairs function. "myocardial fibrosis"
- Native T1 relaxation times: MRI-derived measure sensitive to tissue composition, including fibrosis and edema. "Native T1 relaxation times measured by cardiac magnetic resonance imaging reflect myocardial tissue composition"
- Nucleotide-salvage pathway: Metabolic pathway that recycles bases and nucleosides into nucleotides, conserving energy. "nucleotide-salvage pathway"
- Over-representation analysis: Statistical test assessing whether a set of genes is enriched for specific annotations. "Kosmos conducts an over-representation analysis"
- Partial dependence plot: An interpretability visualization showing the marginal effect of selected features on a model’s prediction. "2D partial dependence plot"
- Perovskite solar cells: Photovoltaic devices using perovskite-structured materials for light absorption. "perovskite solar cells"
- Pleiotropic effects: Effects where a single genetic variant influences multiple traits. "providing strong evidence for pleiotropic effects"
- Posterior inclusion probabilities (PIPs): Bayesian probabilities that a variant is included as causal in a fine-mapping model. "posterior inclusion probabilities (PIPs)"
- Power conversion efficiency (PCE): The percentage of solar energy converted into usable electrical energy. "Average PCE (colour scale) predicted"
- Power-law scaling: A relationship where one quantity varies as a power of another. "power-law scaling"
- Proteome-wide MR: Mendelian randomization applied across the set of measured proteins. "proteome-wide MR framework"
- PP.H4: In coloc, the posterior probability that two traits share a single causal variant (hypothesis 4). "PP.H4 = 1.00"
- Purine and pyrimidine salvage: Biochemical recycling processes that recover nucleobases and nucleosides for nucleotide synthesis. "purine and pyrimidine salvage"
- Random forest model: An ensemble machine learning method using multiple decision trees for prediction. "based on a random forest model"
- Redox homeostasis: Balance of oxidants and reductants in biological systems, crucial for vascular function. "vascular redox homeostasis"
- SHapley Additive exPlanations (SHAP): A method to attribute feature contributions to model predictions using Shapley values. "SHapley Additive exPlanations (SHAP)"
- Short-circuit current density (J_SC): The current per unit area generated by a solar cell at zero voltage. "Short-circuit current density (J) decreases linearly"
- SOD2 (superoxide dismutase 2): A mitochondrial enzyme that dismutates superoxide radicals, implicated in cardiac remodeling. "superoxide dismutase 2 (SOD2)"
- Spin-coating: A thin-film deposition technique where a solution is spread by spinning a substrate. "spin-coating"
- SSR1: Signal sequence receptor subunit 1; a gene potentially regulated by protective T2D variants. "SSR1 and SNRNP48"
- SuSiE: Sum of Single Effects; a Bayesian fine-mapping method and software (susieR). "SuSiE fine-mapping"
- Transcriptome-Wide Association Study (TWAS): Analysis linking genetically predicted gene expression to complex traits. "TWAS Z-scores"
- Transcription Factor Binding Sites (TFBS): DNA sequences bound by transcription factors to regulate gene expression. "Transcription Factor Binding Sites (TFBS)"
- TwoSampleMR: An R package for performing two-sample Mendelian randomization analyses. "TwoSampleMR for Mendelian randomization"
- Volcano plot: A plot of effect sizes versus statistical significance used to highlight important associations. "Volcano plot showing"
Collections
Sign up for free to add this paper to one or more collections.