Growing with Your Embodied Agent: A Human-in-the-Loop Lifelong Code Generation Framework for Long-Horizon Manipulation Skills
Abstract: LLMs-based code generation for robotic manipulation has recently shown promise by directly translating human instructions into executable code, but existing methods remain noisy, constrained by fixed primitives and limited context windows, and struggle with long-horizon tasks. While closed-loop feedback has been explored, corrected knowledge is often stored in improper formats, restricting generalization and causing catastrophic forgetting, which highlights the need for learning reusable skills. Moreover, approaches that rely solely on LLM guidance frequently fail in extremely long-horizon scenarios due to LLMs' limited reasoning capability in the robotic domain, where such issues are often straightforward for humans to identify. To address these challenges, we propose a human-in-the-loop framework that encodes corrections into reusable skills, supported by external memory and Retrieval-Augmented Generation with a hint mechanism for dynamic reuse. Experiments on Ravens, Franka Kitchen, and MetaWorld, as well as real-world settings, show that our framework achieves a 0.93 success rate (up to 27% higher than baselines) and a 42% efficiency improvement in correction rounds. It can robustly solve extremely long-horizon tasks such as "build a house", which requires planning over 20 primitives.













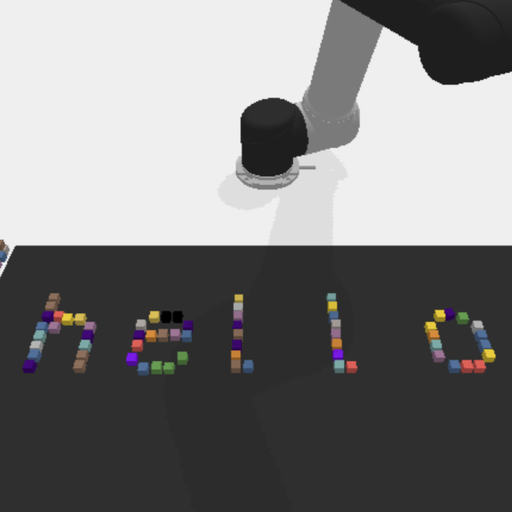





























































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to do long, complicated tasks by writing code, with help from humans. The authors built a system called LYRA that turns your instructions (“build a house with blocks”) into robot code, watches what happens, and learns new reusable “skills” from your feedback. Over time, it becomes better and faster at planning and completing long tasks, both in simulation and on a real robot arm.
What questions does the paper ask?
To make robot code generation work for big, multi-step tasks, the paper focuses on three simple questions:
- How can a robot store what it learns from human feedback in a way that’s reusable and doesn’t get forgotten?
- How can it keep improving these skills over time without breaking what already works?
- How can it pick the right past examples and skills to plan new tasks efficiently?
How does the system work?
Think of LYRA as teaching a robot like you’d teach a student:
- Skills are like recipes or functions in code. For example, a skill might be “stack_blocks(start_position)”. A skill reliably causes a certain behavior, like stacking blocks in a tower.
- Long-horizon tasks are projects with many steps, like “build a house” with more than 20 moves.
- Human-in-the-loop means a person guides the robot while it learns: they give instructions, watch results, and correct mistakes.
- External memory is like a library of learned skills and useful examples that the robot can look up later.
- Retrieval-Augmented Generation (RAG) is how the robot searches that library to find the most relevant past examples and skills for a new task.
- Hints are short notes from the user that nudge the robot toward the right skill (“use the stacking skill for this tower part”).
The learning process happens in three phases:
Phase I: Learn a base skill with human help
- You describe a skill in plain language (“stack four blocks in a corner-to-corner tower”).
- The system proposes a function definition with parameters (like a starting position).
- It tries code, shows the result (in sim or on the robot), and you say what to fix.
- After a few attempts, the skill matches your preferences and works reliably.
Phase II: Grow the skill with a simple curriculum
- A single skill isn’t enough for big projects. So you give a series of slightly harder tasks (like “stack blocks by color” → “build a pyramid” → “make a zigzag tower”).
- The system either creates new skills that call older ones or carefully extends the current skill (using modular code) without breaking what already works.
- Every skill and successful example is stored in the memory library to avoid “catastrophic forgetting” (suddenly failing past tasks).
Phase III: Plan long tasks with smart retrieval and hints
- For a new instruction (say, “build a house”), LYRA searches the memory library for the most similar examples and skill headers within its context budget.
- It uses these to write a task-specific code plan and selects only the relevant skills to avoid noise.
- If it gets stuck, you add a hint (“use place_block_at to finish the roof”), or pause to teach a missing sub-skill.
What did they find, and why does it matter?
Here are the main results the authors report:
- The system reached a 0.93 success rate and was up to 27% better than other methods that generate code from language without strong human guidance.
- It reduced the number of feedback rounds needed by 42%, meaning it learns faster with fewer corrections.
- It solved extremely long tasks like “build a house” that require planning over 20+ steps.
- It worked across different setups:
- Simulation benchmarks like Ravens, Franka Kitchen, and MetaWorld (varied objects, tools, and scenes).
- A real robot arm (Franka FR3) for tasks like stacking a Jenga tower and writing “ICLR”.
Why it matters:
- Robots often struggle with long, precise sequences because language can be vague and models can make mistakes or forget. LYRA keeps skills stable, grows them carefully, and uses memory + hints to stay focused.
- It’s practical: using code and human feedback is faster and easier than training huge end-to-end models that need tons of data and compute.
What’s the impact?
This approach makes it easier to build robots that:
- Learn like apprentices: they take guidance, fix mistakes quickly, and keep what they’ve learned organized.
- Handle complex projects: they can plan and execute many steps reliably using reusable skills.
- Adapt to new tasks and environments: a strong memory and hint system help transfer skills without getting overwhelmed.
In short, LYRA shows a path to more dependable, teachable robot assistants that grow with you—learning new skills over time, keeping old ones intact, and using smart retrieval to plan long tasks without getting lost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open questions that future work could address to strengthen and generalize the proposed framework.
- Quantitative evaluation transparency: The paper reports a 0.93 success rate and 42% fewer feedback rounds, but lacks task counts, per-task success distributions, variance/error bars, statistical significance tests, and details on trial numbers, resets, and failure categorization.
- Baseline fairness and coverage: Comparisons omit strong non-LLM planning/control baselines (e.g., Task and Motion Planning, Behavior Trees, classical program synthesis, hierarchical RL), and Voyager’s adaptation is described as impractical rather than benchmarked; the fairness and representativeness of baselines need justification.
- Hint mechanism ablation: The contribution of user “hints” relative to RAG is not isolated; there is no ablation quantifying how hints change retrieval quality, planning success, or human effort.
- RAG hyperparameter sensitivity: No analysis of retrieval parameters (e.g., K, embedding model, docstring quality, cosine similarity thresholds), their effect on performance, and how retrieval manages noisy or conflicting items.
- Memory scaling and maintenance: It remains unclear how the external memory handles growth (hundreds/thousands of skills/examples), deduplication, versioning, deprecation, conflicting skills, indexing updates, and retrieval latency.
- Skill formalization and composition semantics: The definition of skills as functions is informal; there is no clear semantics for skill composition, pre/post-conditions, parameter typing, constraints, or automatic verification via unit tests/typing/static analysis.
- Catastrophic forgetting mitigation beyond storage: While storage avoids prompt overwriting, the paper does not detail mechanisms for conflict resolution when skill code evolves, version management, or bake-in guarantees that previously validated behaviors remain intact after extensions.
- Modularity vs code bloat: The proposed if-else/match-case extension strategy risks “spaghetti code”; guidelines for refactoring, modular decomposition, and automated linting/refactoring are missing.
- Automatic detection of missing sub-skills: The framework relies on humans to identify and teach missing sub-behaviors; methods to automatically detect skill gaps, propose sub-skill candidates, or perform skill discovery are not explored.
- Human effort, cost, and variability: There is no quantification of human feedback time per skill/task, expertise requirements, inter-user variability, preference alignment metrics, or the impact of inconsistent feedback across users.
- Curriculum design burden: The framework assumes a user-designed curriculum; feasibility, best practices, and the potential for automated curriculum generation, sequencing, or difficulty scheduling are not investigated.
- Robustness to perception and environment noise: The paper does not evaluate sensitivity to occlusions, RGB-D noise, pose estimation errors, lighting changes, clutter, or dynamic scenes—nor strategies for closed-loop perception-driven correction.
- Execution safety and sandboxing: Safety constraints for executing LLM-generated code on real robots (e.g., collision avoidance, force limits, workspace limits, watchdogs) are not described; there is no safety analysis, sandboxing, or recovery protocol.
- Real-time performance and latency: End-to-end latency (LLM inference, retrieval, planning, deployment), time-to-success, and implications for time-critical tasks are not measured.
- Generalization across embodiments: Claims of cross-embodiment transfer are limited; systematic evaluation across different robots, end-effectors, sensors, action spaces, and sim-to-real conditions is absent.
- Domain breadth and task diversity: Tasks focus on tabletop long-horizon manipulation; applicability to contact-rich, deformable, non-prehensile, mobile, or multi-stage assembly tasks is untested.
- Multi-modal grounding: The approach is primarily language/code-centric; integration with VLMs for robust visual grounding, object state tracking, and closed-loop corrections is not evaluated.
- Automatic verification beyond human judgement: Success evaluation largely relies on human acceptance; formal task predicates, programmatic verifiers, and automated success metrics are limited or missing for long-horizon plans.
- Failure analysis and recovery: The paper does not characterize common failure modes (planning, perception, control), nor propose automated recovery strategies (replanning, fallback skills, error handling).
- LLM dependence and portability: The framework depends on proprietary LLMs/embeddings (OpenAI); portability to open-source models, model-specific prompt adaptations, and cost trade-offs are not studied.
- Prompt/context management under growth: With many skills/examples, the context window limit persists; policies for eviction, prioritization, compression, or hierarchical prompts are not provided.
- Metric standardization for long-horizon complexity: There is no standardized measure of “long-horizon” complexity (e.g., primitives count, branching factor, dependency depth) to enable fair comparison across tasks and methods.
- Reproducibility and code availability: Code is promised upon acceptance; currently, reproducibility details (environment configs, seeds, exact prompts, code versions, memory contents) are insufficient.
- Real-world evaluation scale: The real-world validation includes selected demonstrations; the number of trials, variability in setups, robustness to disturbances, and generalization across environments are not reported.
- Skill parameter inference and validation: How the system infers, validates, and constrains skill parameters (types, ranges, units) remains unclear, as does handling parameter mis-specification or runtime errors.
- Knowledge representation quality: Retrieval relies on docstrings/examples; guidelines to ensure high-quality documentation, semantic coverage, and consistent naming that improve retrieval precision are missing.
- Ethical and privacy considerations: Storing user-generated tasks, code, and preferences raises privacy/IP concerns; policies for data handling, access control, and consent are not discussed.
Glossary
- ablation: An experimental setup where components are removed or altered to analyze their impact on performance. "We also include a w/o memory version of our framework for ablation that simulates the human-in-the-loop updates at the prompt level"
- catastrophic forgetting: A phenomenon where learning new information degrades performance on previously learned tasks. "Updating the prompt directly can cause catastrophic forgetting, where performance on earlier tasks drops sharply."
- ChromaDB: An open-source vector database used to store and retrieve embeddings for efficient similarity search. "We implement this using ChromaDB and compute embeddings with OpenAI’s text-embeddings-3"
- CLIPort: A pretrained robotic manipulation policy that leverages CLIP and Transporter architectures for language-conditioned control. "using a pretrained RL policy CLIPort for execution."
- closed-loop control: A control strategy that uses feedback from the environment to adjust actions during execution. "A state-of-the-art code generation framework with LLM-based closed-loop control and incremental examples for in-context learning."
- closed-loop feedback: Iterative feedback provided during task execution that informs subsequent actions or corrections. "While closed-loop feedback has been explored,"
- Code-as-Policies (CaP): An approach that translates natural language instructions into executable robot control code. "Approaches like Code-as-Policies (CaP) translate human instructions into executable Python code with fixed sets of perception and control primitives"
- context window: The maximum number of tokens an LLM can consider when generating output. "limited context window prevents scaling with many examples."
- cosine similarity: A metric that measures the similarity between two vectors based on the cosine of the angle between them. "retrieve the K=10 most similar examples based on cosine similarity"
- DAHLIA: A code generation framework that uses LLM-based closed-loop control and incremental examples to improve robustness. "DAHLIA: A state-of-the-art code generation framework with LLM-based closed-loop control and incremental examples for in-context learning."
- docstrings: In-code documentation strings used to describe functions, here leveraged for indexing and retrieval of skills. "and one for skills indexed by their docstrings."
- embodied AI: AI systems instantiated in physical agents that perceive, act, and learn in the real world. "Using LLMs for code generation in robotic manipulation has shown strong potential in embodied AI."
- environmental perturbations: Unpredictable changes or disturbances in the environment that can degrade policy performance. "due to environmental perturbations and imperfect policy design."
- external memory: An auxiliary storage module that maintains skills and examples for retrieval during planning. "An external memory with Retrieval-Augmented Generation and a hint mechanism supports dynamic reuse"
- few-shot examples: A small set of task demonstrations included in the prompt to guide model behavior. "few-shot examples that show mappings from instructions to task-specific code plan"
- Franka FR3: A model of the Franka Emika robotic arm used for real-world validation. "real-world settings using a Franka FR3 across diverse long-horizon tasks."
- Franka Kitchen: A simulated benchmark environment for long-horizon manipulation tasks with a Franka robot. "Franka Kitchen (long-horizon tasks with a Franka Panda in a kitchen scene)"
- Franka Panda: A widely used 7-DoF robotic manipulator model from Franka Emika. "Franka Kitchen (long-horizon tasks with a Franka Panda in a kitchen scene)"
- GPT-4o: A multimodal version of GPT-4 capable of processing text and visual inputs. "LoHoRavens (GPT-4o)"
- hallucination: When an LLM generates incorrect or fabricated content that diverges from ground truth or intended behavior. "risks hallucination, where LLMs may rewrite or fabricate code during long-horizon interactive planning"
- hint mechanism: A lightweight user-provided signal that directs the agent toward relevant skills or behaviors during retrieval and planning. "An external memory with Retrieval-Augmented Generation and a hint mechanism supports dynamic reuse"
- human-in-the-loop: A paradigm where human feedback is integrated into the learning and planning process to improve reliability. "we propose a human-in-the-loop lifelong skill learning and code generation framework"
- imitation learning: Learning policies by mimicking expert demonstrations rather than optimizing explicit reward functions. "reinforcement learning or imitation learning"
- in-context adaptation: Modifying prompts and contextual inputs to adapt an LLM’s behavior without changing its parameters. "support LLM in-context adaptation."
- in-context learning: The ability of LLMs to learn task behaviors from examples provided within the prompt. "through in-context learning, adapting general-purpose LLMs to specific tasks"
- LLM Program (LMP): A formulation where an LLM is treated as a program that maps instructions to code or behaviors. " is termed a LLM Program (LMP) in prior work"
- language-conditioned policy: A control policy that takes language inputs to guide low-level actions. "invokes a pre-trained language-conditioned policy to execute low-level primitives."
- language embeddings: Vector representations of language used to condition or inform learning algorithms. "relied on language embeddings conditioned within reinforcement learning or imitation learning"
- language grounding: Linking linguistic expressions to corresponding actions, perceptions, or states in the physical world. "task decomposition and language grounding"
- lifelong learning: Continuous learning that accumulates skills over time while preserving prior capabilities. "Inspired by lifelong learning, we extend the pipeline"
- LoHoRavens: A baseline method that leverages GPT-4o and RL policies for language-guided manipulation tasks. "LoHoRavens (GPT-4o) \cite{zhang2023lohoravens}: A language-generation baseline with explicit LLM feedback, using a pretrained RL policy CLIPort for execution."
- LLMs: LLMs that perform reasoning and code generation from natural language inputs. "LLMs and vision-LLMs (VLMs) have become integral to robotic manipulation"
- long-horizon manipulation: Robotic tasks that require many sequential steps or primitives to complete. "Our work focuses on tabletop long-horizon manipulation tasks."
- long-horizon planning: Planning that spans many steps, often stressing an agent’s reasoning and error-handling abilities. "LLM outputs are often noisy and error-prone in long-horizon planning."
- MetaWorld: A benchmark suite of diverse tabletop manipulation tasks using the Sawyer robot. "Experiments on Ravens, Franka Kitchen, and MetaWorld"
- Minecraft: A sandbox environment used in prior LLM skill-learning research due to its simplified action space. "designed for the Java-based game “Minecraft”"
- meta-prompt: A higher-level instruction embedded in the prompt that enforces constraints or preferences across learning phases. "with an added meta-prompt that explicitly asks the agent to preserve prior functionality while adapting to new tasks."
- open-loop code generation: Generating code without incorporating feedback from execution to correct or refine behavior. "A representative baseline for LLM-based open-loop code generation without correction or retrieval."
- OpenAI’s text-embeddings-3: An embedding model for converting text into vectors used in retrieval and similarity search. "compute embeddings with OpenAI’s text-embeddings-3"
- PyBullet: A physics simulation engine used to model and evaluate robotic manipulation tasks. "PyBullet-based Ravens benchmark"
- RAG (Retrieval-Augmented Generation): Enhancing generation by retrieving relevant external information, such as skills and examples. "Retrieval-Augmented Generation (RAG) to retrieve relevant skills and examples"
- Ravens: A robotic manipulation benchmark focused on tabletop tasks and object interactions. "PyBullet-based Ravens benchmark"
- RGB-D: Combined color (RGB) and depth sensing used for visual feedback and evaluation. "where RGB-D scenes before and after execution are given to LLM to determine task success and provide feedback."
- Sawyer: A robotic arm platform used in the MetaWorld benchmark. "MetaWorld (Sawyer with diverse tabletop tasks)"
- UE5: Unreal Engine 5, used here for simulation of robotic manipulation with realistic graphics and physics. "where a UE5 robot manipulates multiple tabletop objects."
- vector databases: Datastores optimized for embedding-based similarity search and retrieval. "with two vector databases: one for few-shot examples indexed by their instructions, and one for skills indexed by their docstrings."
- vision-LLMs (VLMs): Models that jointly process visual and language inputs for tasks like grounding and planning. "LLMs and vision-LLMs (VLMs) have become integral to robotic manipulation"
- Vision–Language–Action (VLA) foundation models: Large pretrained models that integrate vision, language, and action for end-to-end decision-making. "creating end-to-end visionâlanguageâaction (VLA) foundation models"
- Voyager: An LLM-based framework that performs automatic skill learning and feedback in the Minecraft domain. "Recent work, Voyager \cite{wang2023voyager}, explores skill learning with LLM-based automatic feedback"
Practical Applications
Immediate Applications
These applications can be deployed with existing LLMs, standard robot control stacks, and the human-in-the-loop skill learning workflow described in the paper.
- Robotics and Manufacturing: Rapid operator-taught skill authoring for flexible assembly
- Sector: Robotics, Manufacturing
- Use case: Engineers and operators teach robots to perform long-horizon tasks such as kit assembly, fixture setup, part alignment, and post-processing (e.g., stacking, sorting, screwing) using LYRA’s skill functions and human-corrected code plans.
- Tools/products/workflows:
- “Teach–Store–Retrieve–Plan” workflow: define skill header → run small test scenario (1–4 primitives) → human feedback → store skill and examples in memory → task-specific retrieval for deployment.
- Skill Library Manager (code-based skills with docstrings) integrated with ROS/MoveIt and perception APIs.
- Memory-backed planner: ChromaDB + embeddings for few-shot example and skill retrieval.
- Operator Hint UI to nudge retrieval to the correct subset of skills.
- Assumptions/dependencies: Reliable perception (pose estimation, object segmentation), robot safety interlocks, pre-defined control primitives (grasp, place, move-to-pose), access to LLMs and embeddings, and a supervised operator for feedback.
- Warehousing and Logistics: Operator-in-the-loop picking, packing, and kitting with long-horizon sequences
- Sector: Robotics, Logistics/Retail
- Use case: Build packing recipes (stacking, arranging, kit creation) from reusable skills; adapt quickly to SKU changes and seasonal workflows.
- Tools/products/workflows:
- Packing Recipe Memory: examples of successful task plans (instruction, code) retrievable by natural-language queries.
- Retrieval-Augmented Generation to select relevant stacking/arranging skills and avoid prompt overload.
- Hint mechanism to enforce the use of correct skills (e.g., “use stack_blocks at table center with 45° rotation”).
- Assumptions/dependencies: Consistent bin/tote geometry, robust grippers for varied packaging materials, integration with WMS/ERP for task dispatch, and safety certification.
- Laboratory Automation and Academia: Multi-step experimental procedures taught via code skills
- Sector: Healthcare/Biotech, Academia
- Use case: Encode and extend skills for instrument positioning, sample handling, long-horizon pipetting sequences, and multi-device coordination in controlled lab settings.
- Tools/products/workflows:
- Lab Protocol Skill Library: modular skills (e.g., move_to_reference, align_by_color/size) and task examples stored for reuse across experiments.
- Iterative feedback rounds to align behavior to researcher preferences; LYRA shows a 42% reduction in correction rounds.
- Assumptions/dependencies: Sterility requirements, validated tool calibration, integration with lab devices (serial/ROS interfaces), operator oversight.
- Education and Training: Curriculum-based robotics coding that mirrors LYRA’s lifelong skill extension
- Sector: Education
- Use case: Students design, refine, and extend skills (e.g., stacking towers, arranging shapes, writing letters) in simulators and on classroom robot arms, learning modular control and prompt engineering.
- Tools/products/workflows:
- Courseware using PyBullet/UE5 simulators and a low-cost arm (e.g., Dobot/uArm).
- Skill extension exercises using meta-prompts (“preserve previous functionality”) and nested skill composition.
- Assumptions/dependencies: Classroom hardware access, safe training environments, institutional policies for AI use.
- Software/DevOps for Robotics: Memory-backed planning services and reusable skill libraries
- Sector: Software, Robotics
- Use case: Build internal services that provide skill retrieval, code plan synthesis, and hint-driven disambiguation for multi-robot deployments.
- Tools/products/workflows:
- RAG Planner microservice (ChromaDB + embeddings + LLM).
- Skill Library Manager with docstring indexing and API contracts.
- CI/CD pipelines to regression-test skill preservation (avoid catastrophic forgetting).
- Assumptions/dependencies: Stable LLM APIs or on-prem models, version-controlled skill repositories, data privacy policies for stored examples.
- Human-Robot Interaction and Safety: Human-in-the-loop gating for new skills
- Sector: Policy, Robotics
- Use case: Require human validation before deploying newly learned or extended skills; log feedback and code changes for auditability.
- Tools/products/workflows:
- Audit logs of feedback rounds and final task plans.
- Meta-prompts and workflows that enforce “preserve previous functionality.”
- Assumptions/dependencies: Organizational safety standards, compliance tracking, and operator training.
- Real-World Prototyping and Demonstrations
- Sector: Startups, Labs
- Use case: Rapidly prototype complex tabletop tasks (e.g., “build a house,” “write ICLR,” “stack a jenga tower”) on arms like Franka FR3 to validate customer-specific workflows.
- Tools/products/workflows: Out-of-the-box deployment of LYRA with prebuilt stacking/arranging skills, simulator-to-real transfer testing.
- Assumptions/dependencies: Controlled environments and repeatable object sets; tuning for graspers and perception systems.
Long-Term Applications
These applications require further research in perception robustness, scaling across embodiments, safety certification, or broader environmental variability.
- General-Purpose Household Robots: Continual learning of long-horizon chores
- Sector: Consumer Robotics, Daily Life
- Use case: Users teach robots to set tables, sort laundry, arrange items, and perform multi-step tidying; skills persist and extend over time.
- Tools/products/workflows:
- “LYRA Home” skill library synchronized to a household memory store; hintable routines (“use place_kettle,” “arrange cutlery circle”).
- Assumptions/dependencies: Robust mobile manipulation, reliable home perception in clutter/dynamics, safe contact-rich manipulation, cost-effective hardware.
- Fleet-Level Lifelong Learning in Industry: Centralized skill registries and cross-site RAG
- Sector: Manufacturing, Logistics
- Use case: Share verified skills and task examples across a fleet; operators contribute corrections that propagate safely to all robots.
- Tools/products/workflows:
- Fleet Skill Registry, federated memory servers, automatic regression suites to confirm “preserve functionality.”
- Role-based access control for skill updates; change management and rollback.
- Assumptions/dependencies: Standardized skill interfaces across robot models, cybersecurity and IP protection, robust QA processes.
- Healthcare Facility Logistics and Assistive Robotics
- Sector: Healthcare
- Use case: Long-horizon room prep, medication tray assembly, device positioning, and personalized assistive routines taught via human-in-the-loop curricula.
- Tools/products/workflows:
- Hospital RAG Planner integrated with EMR/task scheduling; audited skill expansion logs.
- Assumptions/dependencies: Strict safety and compliance (sterility, HIPAA), validated perception of medical objects, clinician oversight; regulatory approval cycles.
- Cross-Embodiment Skill Transfer and Standardization
- Sector: Robotics
- Use case: Port learned skills across different arms and grippers (e.g., Franka, Sawyer) using device-agnostic APIs; build a marketplace of reusable skills.
- Tools/products/workflows:
- Abstraction layers for kinematics, constraints, and gripper types; semantic docstrings for retrieval across embodiments.
- Assumptions/dependencies: Standardized motion/control APIs (ROS2/MoveIt profiles), calibration tooling, community standards for skill definitions.
- Construction and Field Robotics: Modular assembly and maintenance procedures
- Sector: Construction, Energy
- Use case: Teach robots long-horizon assembly of modular structures or multi-step inspection/maintenance tasks; reuse skills across sites via RAG.
- Tools/products/workflows:
- Procedure libraries with environment-conditioned parameters; on-device retrieval augmented by operator hints.
- Assumptions/dependencies: Heavy-duty hardware, outdoor perception under variable lighting/weather, advanced safety certification, ruggedization.
- Compliance Auditing and Governance for AI Robotics
- Sector: Policy, Governance
- Use case: Use memory logs of feedback, code changes, and deployment outcomes to support audits under regulations (e.g., EU AI Act).
- Tools/products/workflows:
- Skill provenance tracking; differential testing to detect regressions (“catastrophic forgetting” safeguards).
- Assumptions/dependencies: Clear regulatory frameworks for human-in-the-loop systems, standardized reporting formats, privacy/security controls for stored examples and logs.
- Commercial Software Platforms
- Sector: Software
- Use case: “LYRA Studio” as a commercial platform combining skill authoring, memory-backed planning, hint UIs, and safety gates; cloud and on-prem editions.
- Tools/products/workflows:
- Integration with enterprise identity, observability (metrics on success rates, feedback rounds), and simulation-to-real validation suites.
- Assumptions/dependencies: Sustainable LLM access or high-quality local models, scalable embedding and retrieval, multi-tenant data isolation.
- Semi-Autonomous Continual Learning with Reduced Human Overhead
- Sector: Robotics
- Use case: Robots propose skill extensions and self-tests; humans validate only at milestones, accelerating capability growth.
- Tools/products/workflows:
- Auto-generation of challenge tasks outside the original distribution; built-in re-evaluation on prior tasks; formal safety constraints.
- Assumptions/dependencies: Reliable self-evaluation and verifiers, formal safety checks, mechanisms to detect and prevent hallucinated code modifications.
Cross-Cutting Assumptions and Dependencies
- LLM and Embedding Services: Current results rely on high-quality LLMs and text-embedding models (e.g., OpenAI text-embeddings-3). On-prem alternatives may be needed for privacy or cost.
- External Memory and RAG: Requires a robust vector database (e.g., ChromaDB), well-written docstrings/instructions, and careful indexing for effective retrieval.
- Control and Perception Primitives: Success depends on stable low-level APIs (grasp/place/move), accurate object detection/pose estimation, and reliable calibration.
- Human-in-the-Loop Availability: The framework’s strength is rapid human correction; sustained operator involvement or structured curricula are necessary for skill acquisition and extension.
- Safety and Compliance: Industrial and healthcare deployments require safety interlocks, audit trails, and adherence to regulatory protocols.
- Scope and Generalization: The paper focuses on tabletop manipulation; extension to mobile, deformable, or contact-rich tasks demands further research and hardware capabilities.
- Cost and Latency: Cloud LLM inference may introduce latency and ongoing costs; edge deployment may require smaller models and optimization.
Collections
Sign up for free to add this paper to one or more collections.

