- The paper presents a novel RL approach, using LOOP to directly train digital agents via a POMDP framework for task completion.
- It introduces a simplified PPO variant that uses a single LLM for improved memory efficiency and sample-efficient learning.
- Evaluation on AppWorld shows a 9% improvement over benchmarks, establishing a new state-of-the-art for open-weight models.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Introduction
This paper presents a novel approach for training Interactive Digital Agents (IDAs) using Reinforcement Learning (RL). Unlike previous instruction-tuned LLMs, which can handle feedback through multi-step exchanges, the proposed method involves direct training in target environments, formalized as a Partially Observable Markov Decision Process (POMDP). The LOOP algorithm, introduced as a variant of Proximal Policy Optimization (PPO), optimizes memory and data efficiency by using a single LLM copy in memory, outperforming significant benchmarks, notably the OpenAI o1 agent.
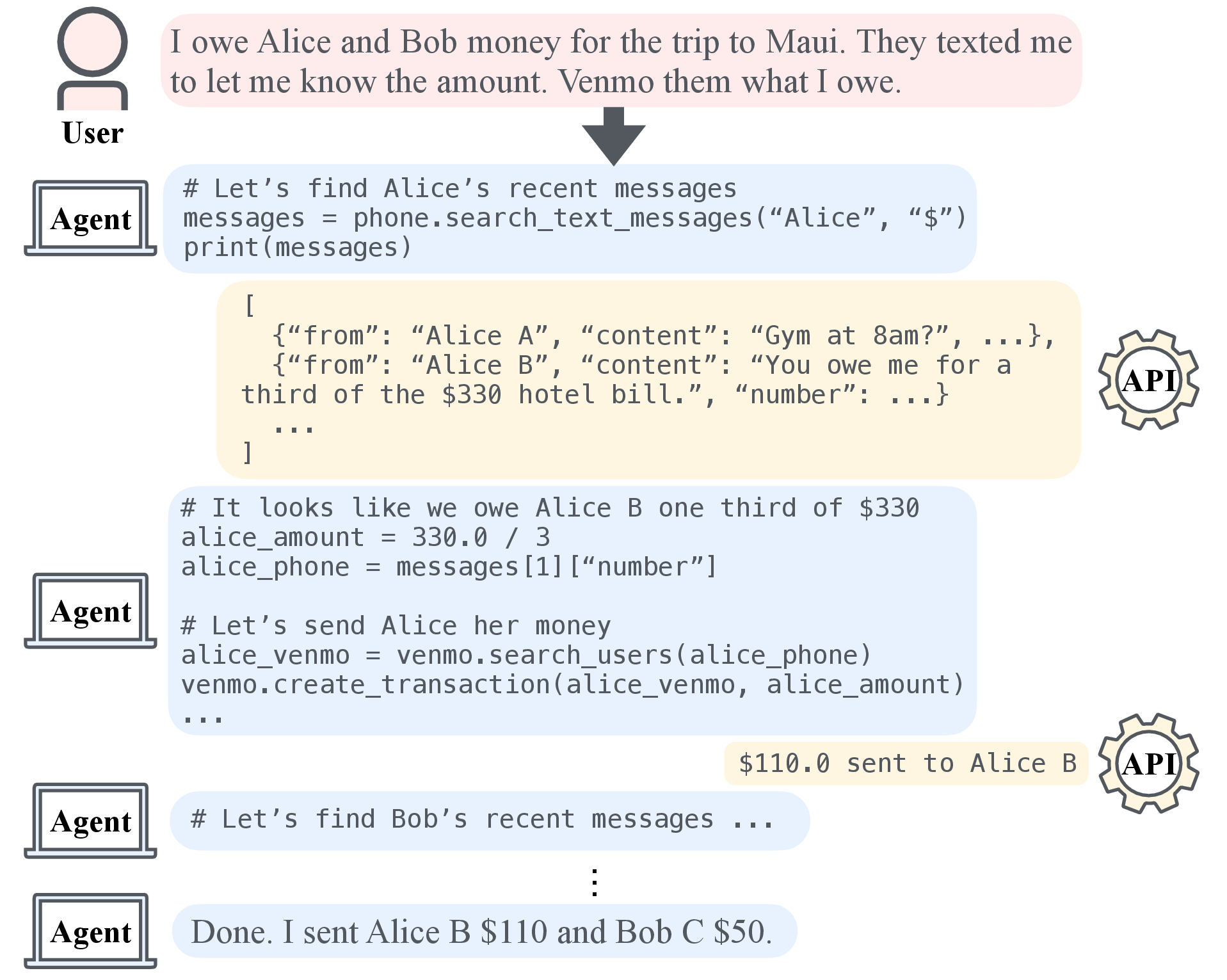
Figure 1: An interactive digital agent receives a user request and iteratively interacts with APIs through a Python read-eval-print loop (REPL) to accomplish the task.
Methodology
The paper introduces LOOP, a PPO-based RL algorithm designed to leverage a leave-one-out baseline estimate and per-token clipping to enable sample-efficient learning. Unlike traditional implementations requiring multiple LLM instances—the reward model, trained policy, reference policy, and critic—LOOP uses only one LLM in-memory akin to single LLM fine-tuning.
With its simplified structure, LOOP maintains performance while circumventing the requirement of a value network, thus enhancing efficiency in implementation. The agent's behavior emerges from straightforward task-completion rewards and generalizes across diverse, unforeseen tasks. LOOP's configuration employs a 32-billion-parameter LLM model, demonstrating considerable performance improvements across test sets of the AppWorld environment.
Evaluation and Results
The experiment conducted over AppWorld showed LOOP's superiority over existing models, with significant margin improvements. LOOP exceeded the OpenAI o1 model by 9 percentage points, establishing a new state-of-the-art performance for open-weight models. The enhanced agent exhibits reinforced strategic behaviors across different sessions, consulting API documentation systematically before action and significantly minimizing errors such as unwarranted assumptions or use of placeholders.
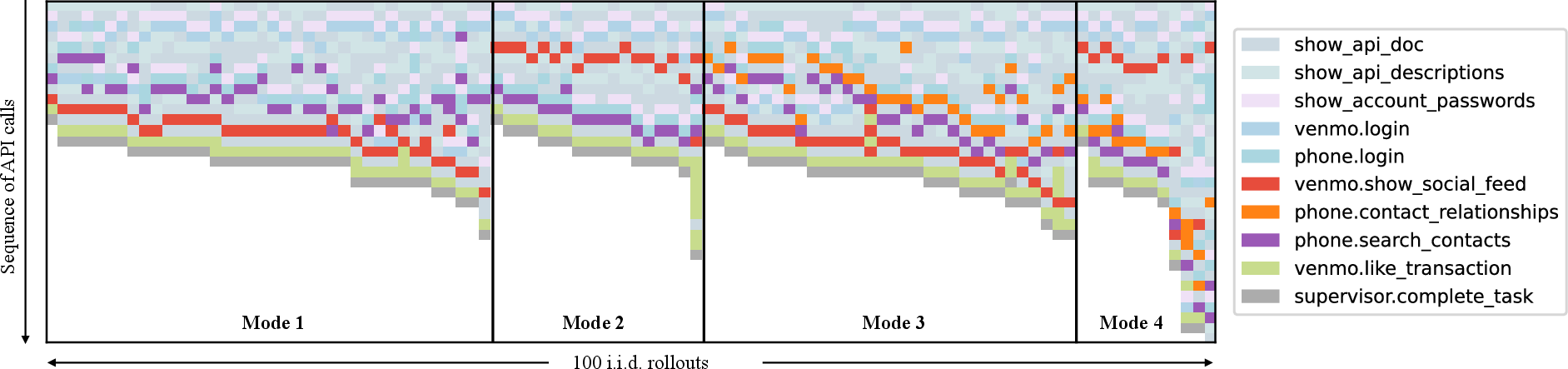
Figure 2: A visualization of 100 i.i.d.\ rollouts of an agent on the same task after LOOP training. Most rollouts successfully complete tasks with unique strategies.
Behavioral Insights
The behavioral analysis highlights how reinforcement learning fosters improved agent decision-making. Notably, LOOP facilitates agents to eschew suboptimal decisions by avoiding multiple simultaneous code submissions and enhancing documentation consultation prior to API invocation. Notably, the agent incorporated strategies to recover promptly from setbacks, significantly reducing task capitulations after API call failures.
Implications and Future Work
While LOOP improves task success rates significantly, there remains room for enhancement, particularly in contexts demanding high-level autonomy or within adversarial settings. The paper establishes groundwork for future developments, potentially incorporating non-determinism, transient failures, or unsolvable tasks within RL frameworks for IDAs. Expanding training beyond static scenarios to dynamic, real-world environments could also prove beneficial, elevating the practical applicability of IDAs.
Conclusion
The paper successfully demonstrates RL's viability for training complex IDAs, highlighting LOOP's operational efficiency and superior performance relative to large-scale existing models. This research aligns with broader AI objectives, focusing on bridging theoretical advancements with applied practicality in ever-evolving tech ecosystems.