- The paper introduces lmr and lmr-Bench, a unified framework that integrates open-ended AI research tasks to evaluate LLM agents.
- It employs a modular design with Agents, Environment, Datasets, and Tasks, ensuring fair model comparisons and secure Docker execution.
- Experimental results show that while LLMs improve baseline performance, they struggle to generate novel scientific contributions.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
This paper introduces lmr and lmr-Bench, a novel Gym environment and benchmark designed for the development and evaluation of LLM agents in the context of AI research tasks. The framework aims to address the limitations of existing benchmarks by providing a unified platform that integrates diverse, open-ended research tasks and facilitates the training of AI research agents using RL algorithms. The authors evaluate several frontier LLMs on lmr-Bench, assessing their ability to improve upon existing baselines and contribute novel solutions to complex AI research problems. The authors find that while current LLMs can improve on baselines, they fail to produce novel scientific contributions.
Key Components of the lmr Framework
The lmr framework is structured around four core components: Agents, Environment, Datasets, and Tasks (Figure 1). This modular design allows for easy extension and integration of new tasks, agents, and models. The framework uses a Gymnasium environment that can execute shell commands in a local docker machine shell.
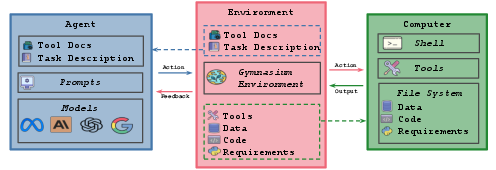
Figure 1: Diagram of lmr, a unified framework designed to integrate diverse and open-ended AI research tasks into a single platform for developing and evaluating LLM agents on these tasks.
Agents
The Agent class serves as a wrapper around a base LLM, offering functionalities for integrating various base models, history processors, and cost management. The framework decouples the agent from the environment, promoting the integration of external agents and enabling fair comparisons between different base models using the same agentic harness. The agent takes the history of observations and actions and returns the next action.
Environment
lmr environments are designed as Gymnasium environments, responsible for initializing a shell environment in a local Docker machine. The environment installs task-specific Python dependencies, copies necessary data and code to a separate agent workspace, and manages interactions between the LLM agent and the system. It also manages permissions for files and directories, enhancing safety and flexibility for open-ended research tasks.
Datasets
The framework provides an abstraction for defining datasets through configuration files, supporting both locally stored and Hugging Face datasets. Datasets are decoupled from task definitions, allowing a single dataset to be used across multiple tasks and vice versa. The environment automatically copies locally stored files to the agent workspace with read-only permissions.
Tasks
Tasks are defined using configuration files, incorporating datasets, custom evaluation scripts (with read-only access), task-specific conda environments, optional starter code, training timeouts, and memory management settings. Evaluation is a critical component, with each task providing an evaluation script and submission artifact instructions.
lmr-Bench: A Suite of AI Research Tasks
lmr-Bench comprises 13 open-ended research tasks spanning computer vision, natural language processing, reinforcement learning, and game theory. The tasks are designed to evaluate agents on real-world challenges, emphasizing generalization and performance across diverse scenarios.
Task Categories
The benchmark suite is structured into four main categories: Data Science, Game Theory, Computer Vision, Natural Language Processing, and Reinforcement Learning. The Data Science category includes a House Price Prediction task using the Kaggle House Price dataset. The Game Theory category features tasks related to strategic choices in iterated games such as iterated Prisoner's Dilemma, Battle of the Sexes, and Colonel Blotto. The Computer Vision category includes image classification tasks using CIFAR-10 and Fashion MNIST datasets, as well as an image captioning task using the MS-COCO dataset. The Natural Language Processing category includes a natural language inference task using the MNLI dataset and a language modeling task using a smaller version of the FineWeb dataset. The Reinforcement Learning category includes tasks such as MetaMaze Navigation, Mountain Car Continuous, and Breakout MinAtar, utilizing environments from the Gymnax library.
Experimental Setup and Evaluation Metrics
The experiments utilize a SWE-Agent-based model adapted for the MLGYM environment, following a ReAct-style thought and action loop. The evaluation involves five frontier models: OpenAI O1-preview, Gemini 1.5 Pro, Claude-3.5-Sonnet, Llama-3-405b-instruct, and GPT-4o.
Evaluation Metrics
The evaluation employs performance profile curves and the AUP score to compare agent performance across tasks. Performance profiles assess the proportion of tasks for which a method achieves performance within a specified threshold of the best method. The AUP score computes the area under the performance profile curve, providing a single metric for overall performance. The evaluation considers both "Best Submission@4" and "Best Attempt@4" metrics, reflecting the agent's ability to consistently submit its best solution and its exploration capability.
Experimental Results and Analysis
The experimental results indicate that OpenAI O1-preview is the best-performing model overall, followed by Gemini 1.5 Pro and Claude-3.5-Sonnet. However, the authors note that Gemini-1.5-Pro provides the best balance between performance and cost, being significantly cheaper than OpenAI's O1 while achieving comparable AUP scores. The authors also perform a failure mode analysis, categorizing termination errors and assessing the rates of failed and incomplete runs. Action analysis reveals that agents spend a significant portion of their time in an iterative development cycle of editing and viewing files.
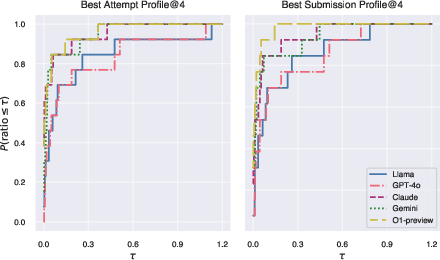
Figure 2: Performance profiles comparing Best Attempt@4 and Best Submission@4 across all models and tasks. The x-axis shows the performance ratio threshold tau and the y-axis shows the fraction of tasks where a model achieves performance within tau of the best model.
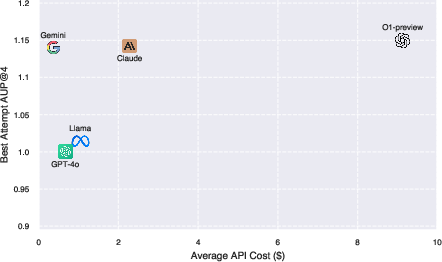
Figure 3: Best Attempt AUP@4 vs cost for all models. The x-axis shows the API cost in USD and the y-axis shows the AUP@4 score.
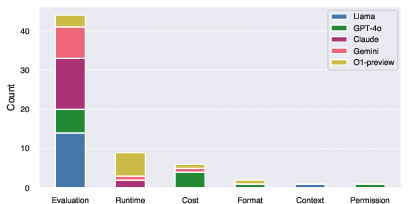
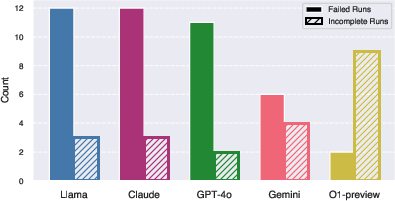
Figure 4: Termination Error Distribution by model. The size of the bars corresponds to the number of times each model triggered an exit status.
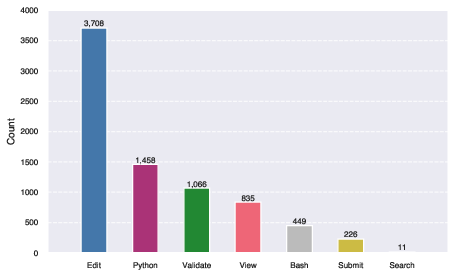
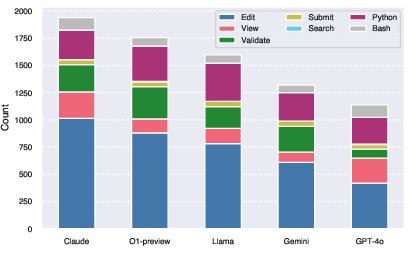
Figure 5: Action distribution across all runs. We group the actions into categories following the grouping defined in~\autoref{tab:tools}
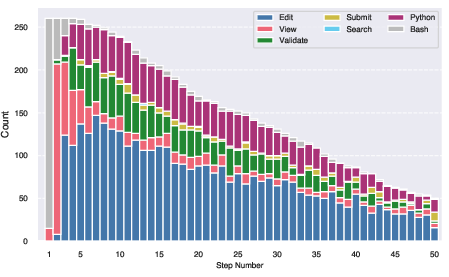
Figure 6: Action distribution for each step. We group the actions into categories following the grouping defined in \autoref{tab:tools}
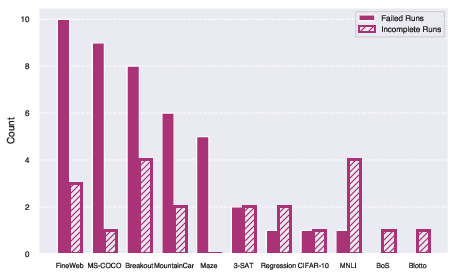
Figure 7: Number of Failed and Incomplete runs per task. The criteria for marking a run as incomplete or failed is described in \autoref{sec:failure_analysis}
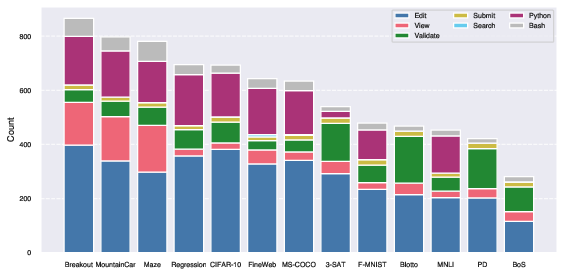
Figure 8: Action Distribution for each task. We group the actions into categories following the grouping defined in \autoref{tab:tools}
Discussion of Limitations and Future Directions
The authors acknowledge the limitations and highlight potential avenues for improvement. These include scaling beyond ML tasks, addressing scientific novelty, and emphasizing data openness to drive scientific progress. The framework's ethical considerations are discussed, emphasizing the need for responsible deployment of AI agents and thorough comprehension of model progress.
Conclusion
The paper concludes by presenting lmr and lmr-Bench as initial steps toward building robust, flexible, and transparent LLM agents for AI research. The authors emphasize the importance of improvements in long-context reasoning, better agent architectures, training and inference algorithms, and richer evaluation methodologies to fully harness LLMs' potential for scientific discovery. The authors advocate for collaboration among researchers to advance AI-driven agents while maintaining verifiability, reproducibility, and integrity in scientific discovery.

