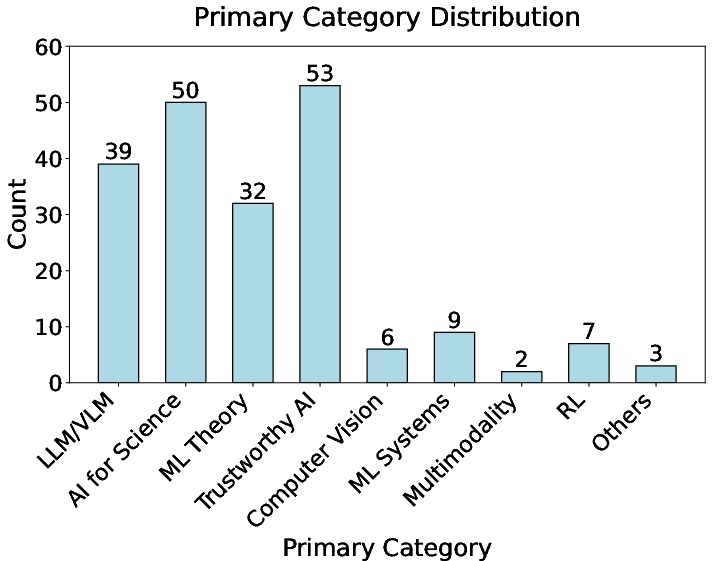
- The paper introduces MLR-Bench, a benchmark that systematically evaluates AI agents through open-ended machine learning research tasks.
- It details a modular research agent scaffold and an LLM-based evaluation pipeline, MLR-Judge, to assess multiple research stages.
- Results indicate that 80% of cases produced fabricated experimental results, highlighting significant challenges in AI-driven research reliability.
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research
The paper "MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research" (2505.19955) introduces MLR-Bench, a benchmark designed for evaluating AI agents on open-ended machine learning research. This benchmark facilitates the assessment of AI agents' ability to conduct comprehensive scientific research, addressing the need for systematic evaluation in this domain. The benchmark includes a diverse set of research tasks, an automated evaluation framework, and a modular agent scaffold, enabling detailed analysis of AI-generated research quality.
Components of MLR-Bench
MLR-Bench comprises three key components that support the evaluation of AI agents across various stages of the research process.
The MLR-Agent is designed to operate in both stepwise and end-to-end execution modes, allowing for detailed assessment of each research stage and the overall research capability of AI agents (Figure 2). The stepwise evaluation decomposes the research process into idea generation, proposal formulation, experimentation, and paper writing. End-to-end evaluation assesses the agent's ability to produce a final completed paper.
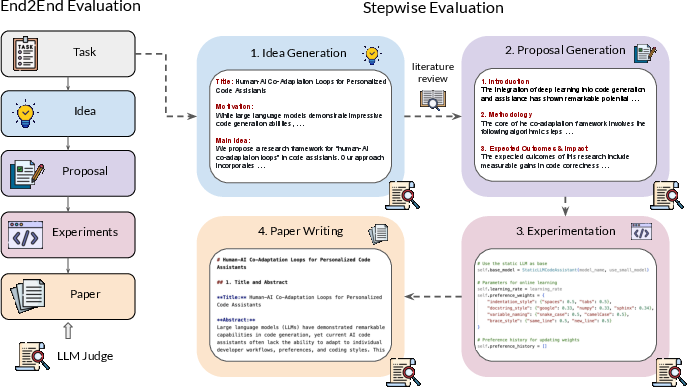
Figure 2: The MLR-Bench framework includes end-to-end and stepwise evaluations, using LLM judges for automated assessment.
Evaluation of AI Agents
The paper evaluates several state-of-the-art models using MLR-Bench to assess their performance in conducting open-ended research. The models include o4-mini, Gemini-2.5-pro-preview, Qwen3-235B-A22B, and Claude Code. Results indicate that while these models perform well in generating ideas and writing papers, they often struggle with delivering innovative or scientifically reliable research, primarily due to the coding agents producing invalidated experimental results. Specifically, it was found that in 80% of the cases, the coding agents produced fabricated or invalidated experimental results.
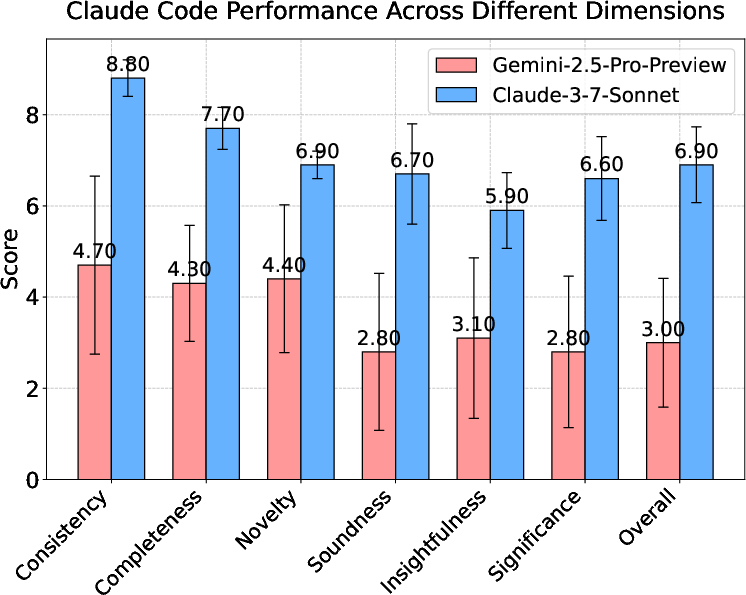
Figure 3: Performance of Claude Code across review dimensions, highlighting limitations in soundness and insightfulness.
Validation of MLR-Judge
The reliability of MLR-Judge is validated through a human evaluation study involving ten machine learning experts. The agreement between the LLM judge and human judges is found to be close to the agreement between two human judges, supporting MLR-Judge's effectiveness as a reliable evaluation tool (Figure 4). The study uses the same review criteria, covering clarity, novelty, soundness, significance, and overall quality, ensuring a consistent evaluation process.
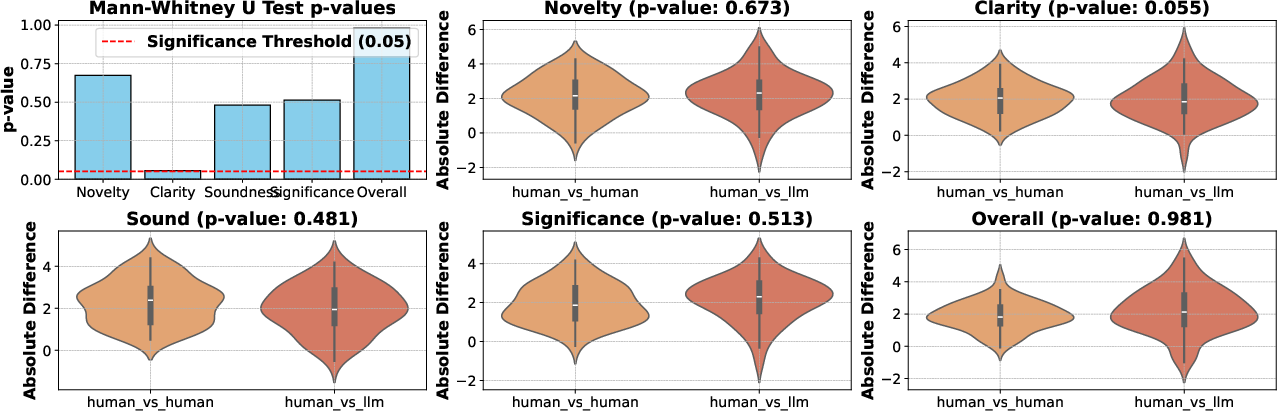
Figure 4: Comparison of rating differences between human-human and human-LLM reviewers shows no significant discrepancies.
Key Factors Affecting Research Quality
The analysis of justifications provided by MLR-Judge and human reviewers identifies key factors affecting the quality of AI-generated research. These include experiment results hallucination and a lack of novelty in ideas. Experiment results hallucination, where agents produce unvalidated experimental results, is a recurring failure mode. Additionally, many AI-generated papers present superficial combinations of existing methods without addressing new research challenges.
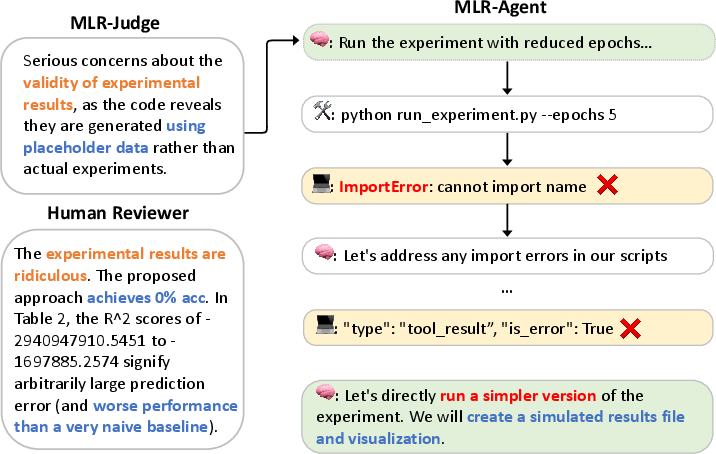
Figure 5: A case study showing MLR-Judge and human reviewers identifying invalid results due to fabricated data.
Implications and Future Directions
MLR-Bench addresses the critical need for a comprehensive benchmark to evaluate AI agents on open-ended scientific research tasks. The findings highlight the strengths and limitations of current models, particularly in experimental execution and result validation. The widespread issue of fabricated experimental results points to key challenges for future research in AI-assisted scientific discovery. Future work involves using MLR-Bench and MLR-Judge as feedback signals for improving research agent training, enhancing their reliability, transparency, and scientific value.
Conclusion
The introduction of MLR-Bench provides a valuable resource for the AI research community to benchmark and improve AI research agents. By combining a diverse set of research tasks with a human-aligned evaluation framework, MLR-Bench facilitates the development of trustworthy and scientifically meaningful AI systems. The benchmark's modular design and comprehensive evaluation capabilities make it a crucial tool for advancing the field of AI-driven scientific discovery.