Learning Pseudorandom Numbers with Transformers: Permuted Congruential Generators, Curricula, and Interpretability
Published 30 Oct 2025 in cs.LG, cond-mat.dis-nn, and cs.CR | (2510.26792v1)
Abstract: We study the ability of Transformer models to learn sequences generated by Permuted Congruential Generators (PCGs), a widely used family of pseudo-random number generators (PRNGs). PCGs introduce substantial additional difficulty over linear congruential generators (LCGs) by applying a series of bit-wise shifts, XORs, rotations and truncations to the hidden state. We show that Transformers can nevertheless successfully perform in-context prediction on unseen sequences from diverse PCG variants, in tasks that are beyond published classical attacks. In our experiments we scale moduli up to $2{22}$ using up to $50$ million model parameters and datasets with up to $5$ billion tokens. Surprisingly, we find even when the output is truncated to a single bit, it can be reliably predicted by the model. When multiple distinct PRNGs are presented together during training, the model can jointly learn them, identifying structures from different permutations. We demonstrate a scaling law with modulus $m$: the number of in-context sequence elements required for near-perfect prediction grows as $\sqrt{m}$. For larger moduli, optimization enters extended stagnation phases; in our experiments, learning moduli $m \geq 2{20}$ requires incorporating training data from smaller moduli, demonstrating a critical necessity for curriculum learning. Finally, we analyze embedding layers and uncover a novel clustering phenomenon: the model spontaneously groups the integer inputs into bitwise rotationally-invariant clusters, revealing how representations can transfer from smaller to larger moduli.
The paper demonstrates that Transformer models accurately predict PCG outputs and generalize to unseen generator parameters via in-context learning.
It systematically analyzes scaling laws and shows that curriculum learning effectively improves performance on large-modulus PCG tasks.
Key insights include the emergence of rotation-invariant token clustering, indicating that the model internalizes deep algorithmic structures.
Learning Pseudorandom Numbers with Transformers: Permuted Congruential Generators, Curricula, and Interpretability
Introduction and Motivation
This work systematically investigates the capacity of Transformer architectures to learn and predict sequences generated by Permuted Congruential Generators (PCGs), a widely used class of non-cryptographic pseudo-random number generators (PRNGs). PCGs, which underpin the default random number generator in NumPy, introduce significant complexity over classical linear congruential generators (LCGs) by applying bitwise permutations—shifts, XORs, rotations, and truncations—to the internal state. The study addresses both the practical question of whether modern sequence models can "crack" such generators and the theoretical question of what algorithmic structures Transformers can internalize and generalize from data.
PCG Variants and Task Formulation
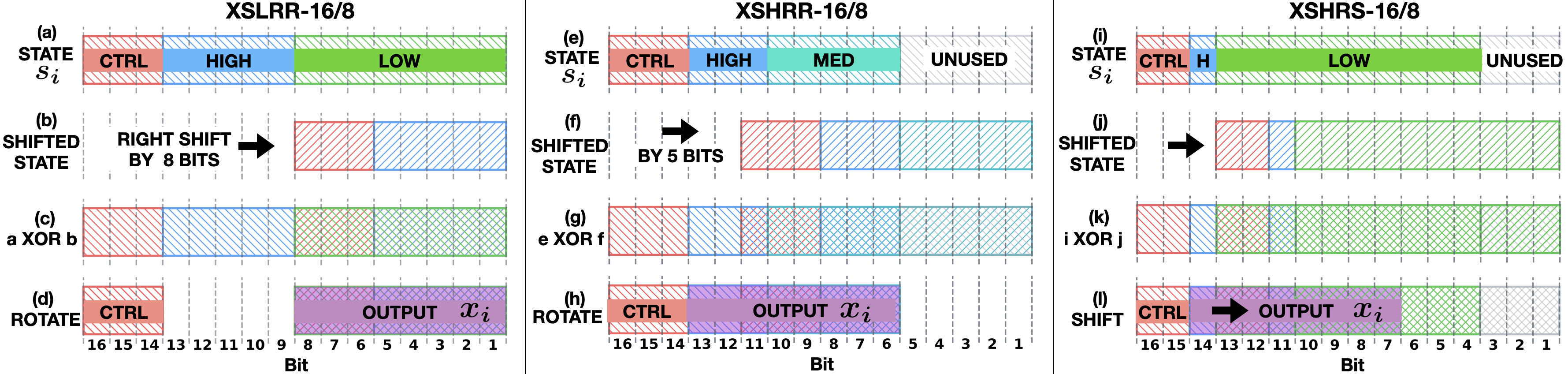
PCGs are defined by the recurrence si=(asi−1+c)modm with output xi=f(si), where f is a permutation function involving bitwise operations. The paper considers several PCG variants:
TLCG (Truncated LCG): Outputs only the high bits of the state.
XSLRR (XORShift Low with Random Rotation): Right-shifts and XORs the state, then rotates the lower bits.
XSHRR (XORShift High with Random Rotation): Similar to XSLRR but operates on higher bits.
XSHRS (XORShift High with Random Shift): Applies a right shift and XOR, then outputs a shifted window.
The complexity of these permutations is illustrated in (Figure 1).
Figure 1: Depiction of PCG protocols at m=216, showing the bitwise operations and output selection for XSLRR, XSHRR, and XSHRS variants.
The prediction task is next-token prediction: given a sequence of outputs x0,x1,...,xL−1, the model predicts xL. The challenge is exacerbated by the fact that the model is not given explicit knowledge of the generator parameters or the permutation function.
Transformer Model and Training Regime
The core architecture is a GPT-style, decoder-only Transformer with Rotary Positional Embeddings (RoPE). Model sizes range up to 50M parameters, with context lengths and vocabulary sizes scaling with the modulus and output bit-width. Training is performed with cross-entropy loss and AdamW optimizer, using large datasets (up to 5×109 tokens) and batch sizes of 512. Both "separate" (single generator type) and "combined" (multiple generator types) training regimes are explored.
In-Context Learning of PCGs
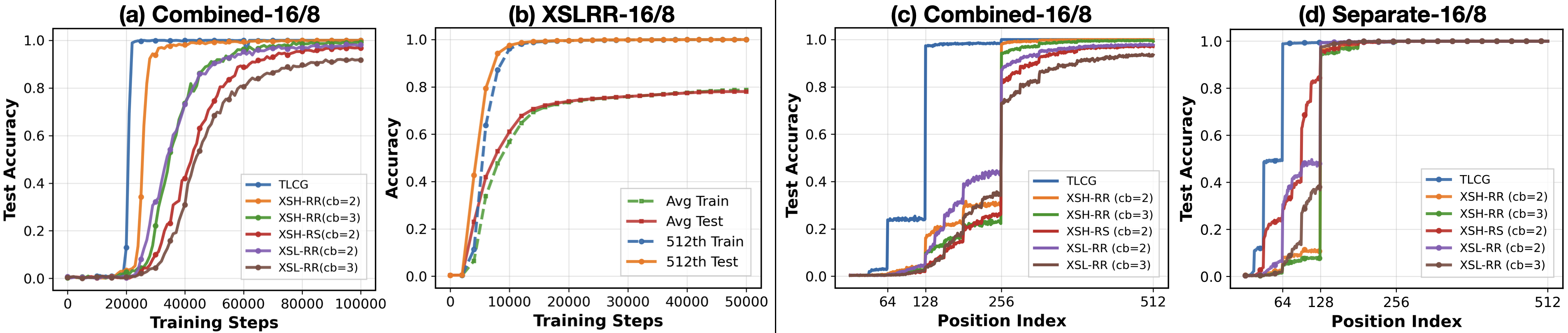
Transformers are shown to achieve high in-context prediction accuracy on PCG sequences, even when trained on combined datasets containing multiple generator types. Notably, the models generalize to unseen (a,c) parameter pairs, a regime beyond the reach of published classical attacks, which typically require knowledge of the modulus and multiplier.
Figure 2: (a) Test accuracy at the 512th token during training on combined datasets. (b) Accuracy during training on XSLRR-16/8. (c) Final test accuracy by position index for combined training. (d) Final test accuracy for separate training, with near-perfect accuracy after 128 in-context elements.
A key finding is that even with severe output truncation (e.g., retaining only the highest bit), the model achieves accuracy far above random guessing, indicating that Transformers can exploit subtle residual structure in the output sequence.
Scaling Laws and Performance Limits
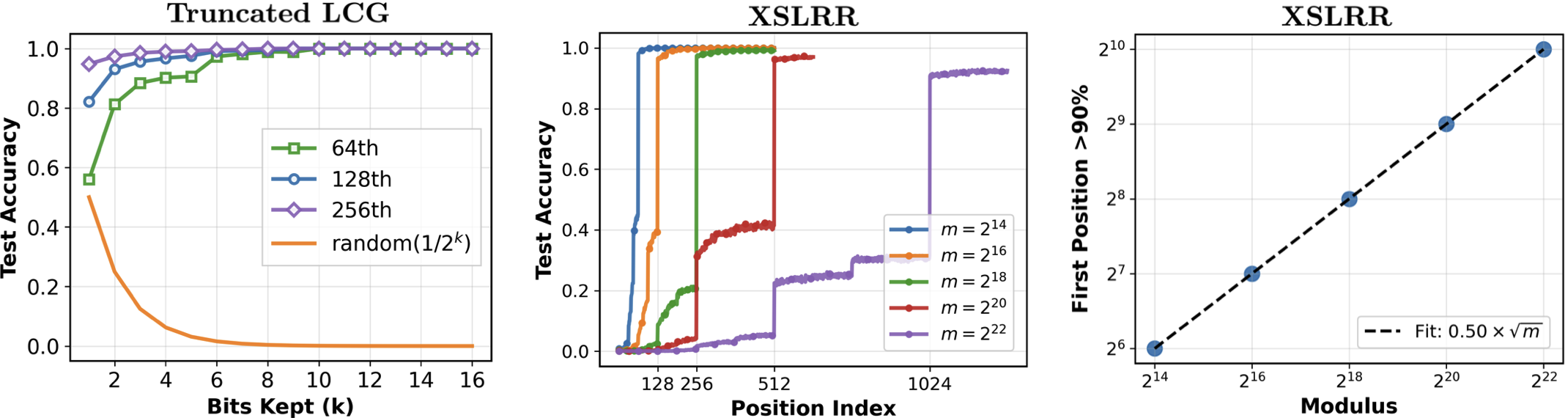
The study establishes a scaling law for the number of in-context elements required for high-accuracy prediction: for PCGs with modulus m, the required context length grows as m, which is significantly steeper than the m0.25 scaling observed for LCGs. This scaling is empirically validated across moduli from 214 to 222.
Figure 3: Prediction accuracy as a function of bits kept in truncated LCGs (left), context length for XSLRR (middle), and scaling of required context length with modulus (right).
The context length becomes the primary bottleneck as m increases, and the Transformer’s ability to generalize is fundamentally limited by the information obscuration introduced by the PCG permutations.
Data and Model Scaling
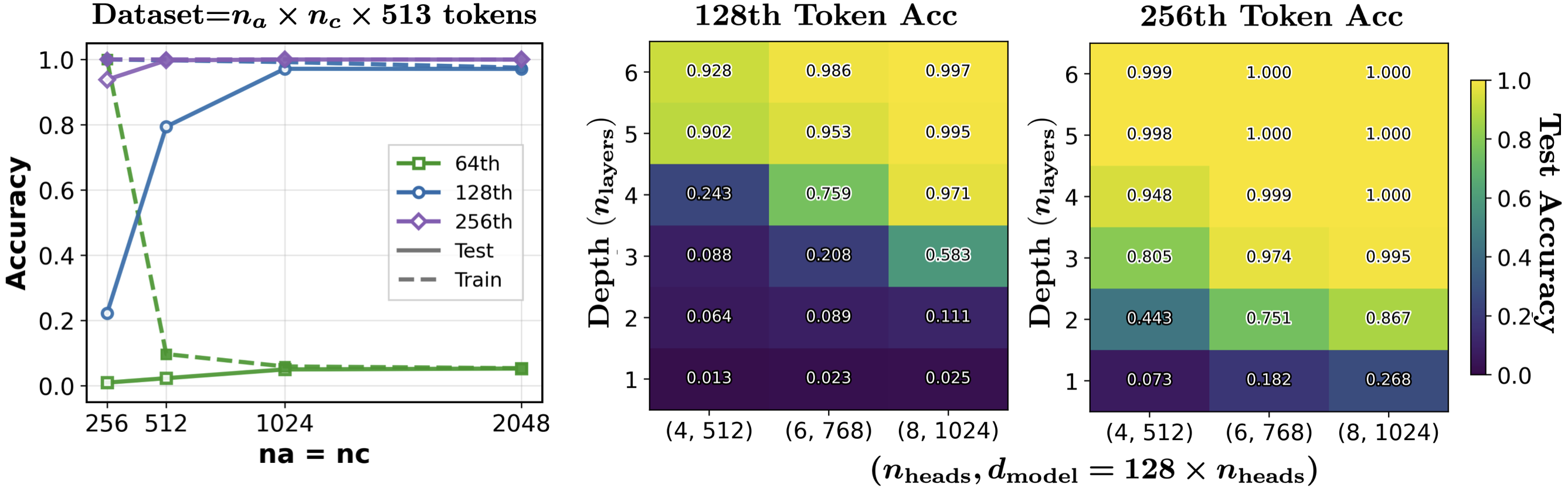
The required dataset size for generalization is modest compared to the total number of possible (a,c) pairs; na=nc=1024 suffices for m=216. Model scaling experiments show that increased depth and width allow the model to achieve high accuracy with fewer observed elements, but diminishing returns set in beyond 4 layers and 8 heads.
Figure 4: Scaling studies of dataset size and model capacity. Accuracy improves rapidly with dataset size and saturates; larger models achieve higher accuracy at earlier positions.
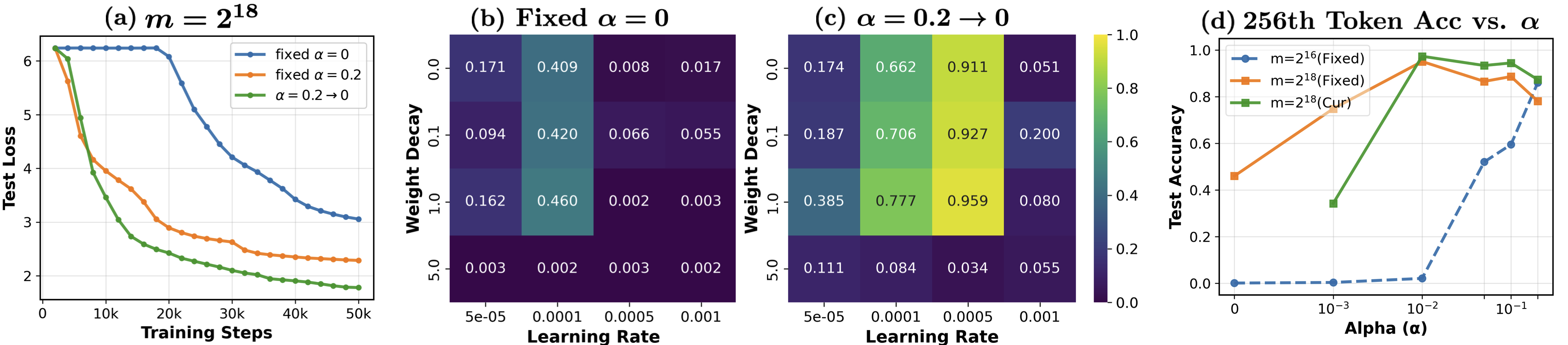
Curriculum Learning for Large Moduli
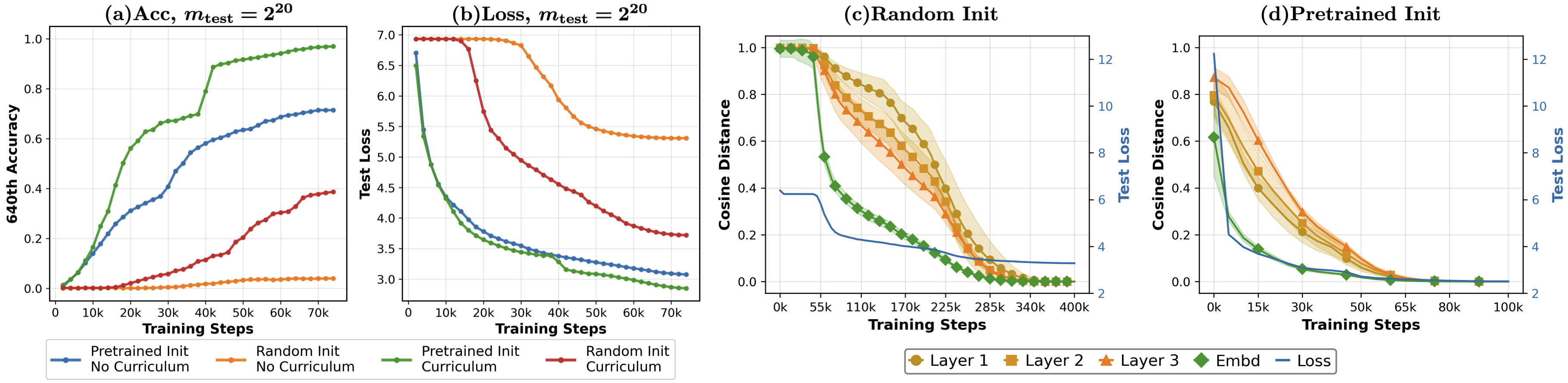
Direct training on large-modulus PCGs (m≥220) leads to optimization stagnation. The paper demonstrates that curriculum learning—mixing in data from smaller moduli and decaying the mixing ratio—removes stagnation and enables successful training within fixed compute budgets. Pretrained initialization from smaller-modulus models further accelerates convergence and improves final accuracy.
Figure 5: Effect of mixing smaller-modulus data on training stability and final accuracy. Curriculum learning removes stagnation and broadens the range of stable learning rates.
Figure 6: Impact of pretrained initialization and curriculum training on scaling to larger moduli. Pretraining and curriculum both accelerate convergence and improve final accuracy.
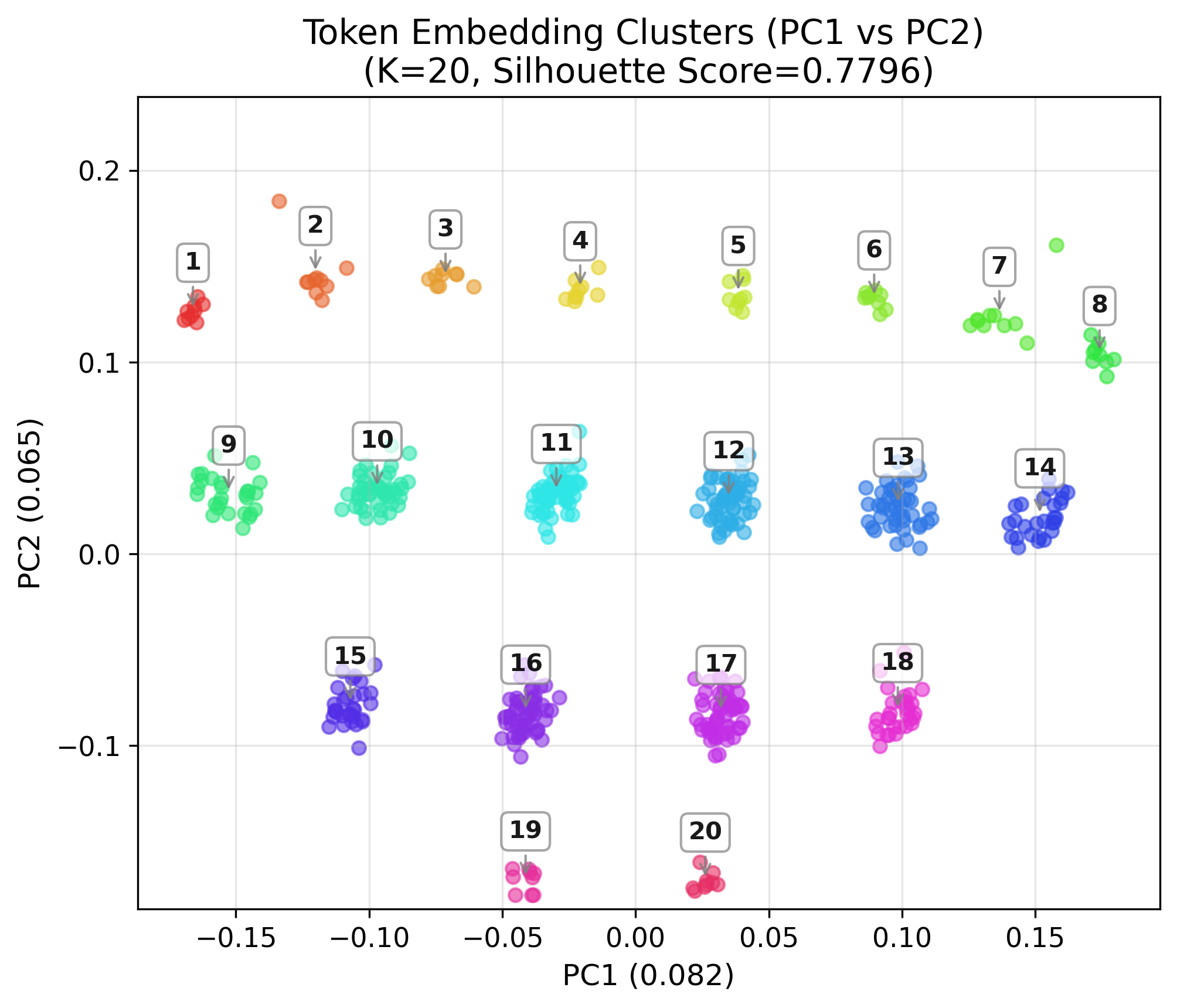
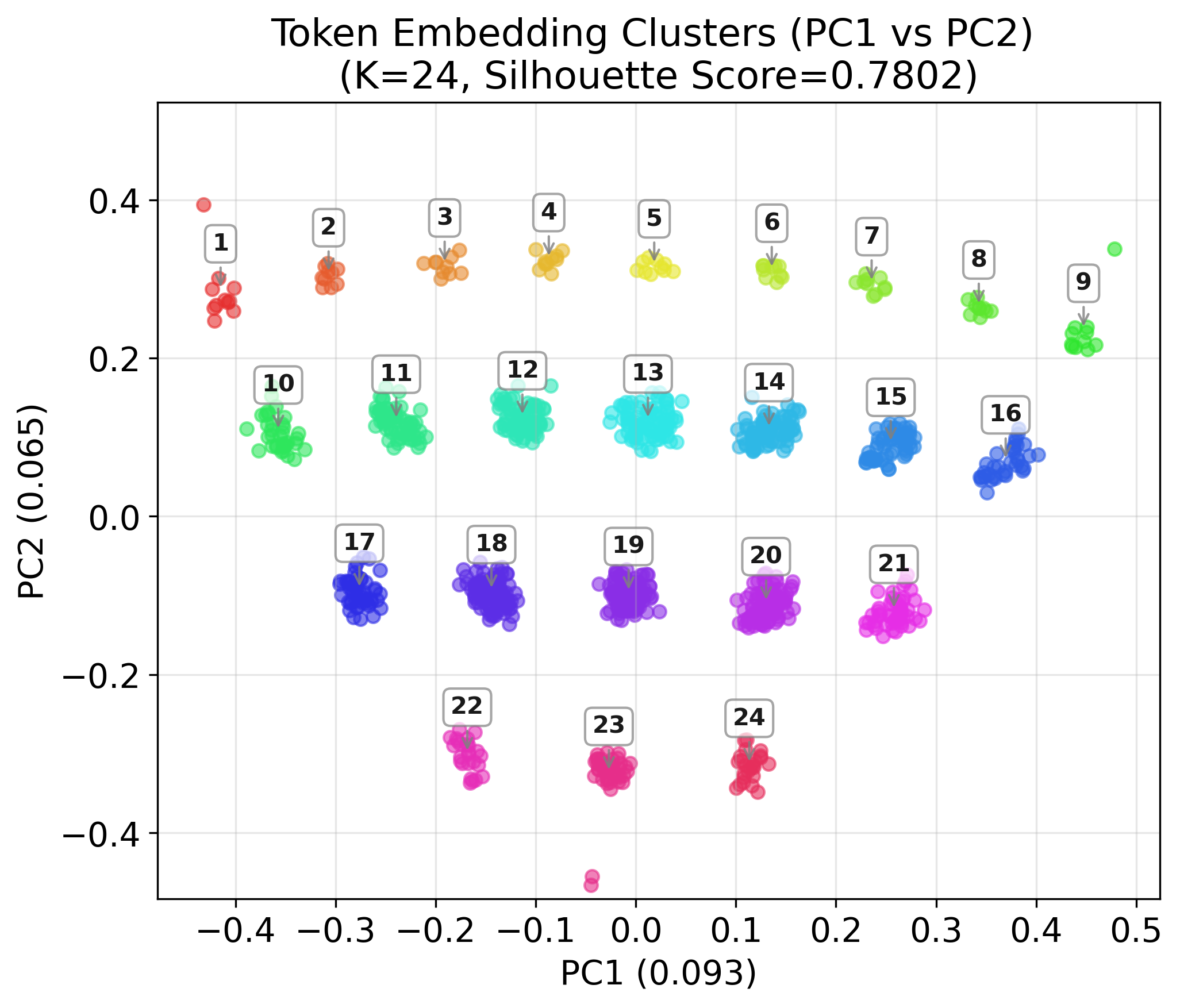
Interpretability of Learned Representations
Principal component analysis of the token embedding matrix reveals that the model spontaneously organizes tokens into clusters based on rotation-invariant features of their binary representations, specifically the number and arrangement of contiguous zero runs. This structure is consistent across moduli and persists when transferring models via pretraining.
Figure 7: XSLRR-18/9 Model Token Clusters, showing rotation-invariant grouping in the embedding space.
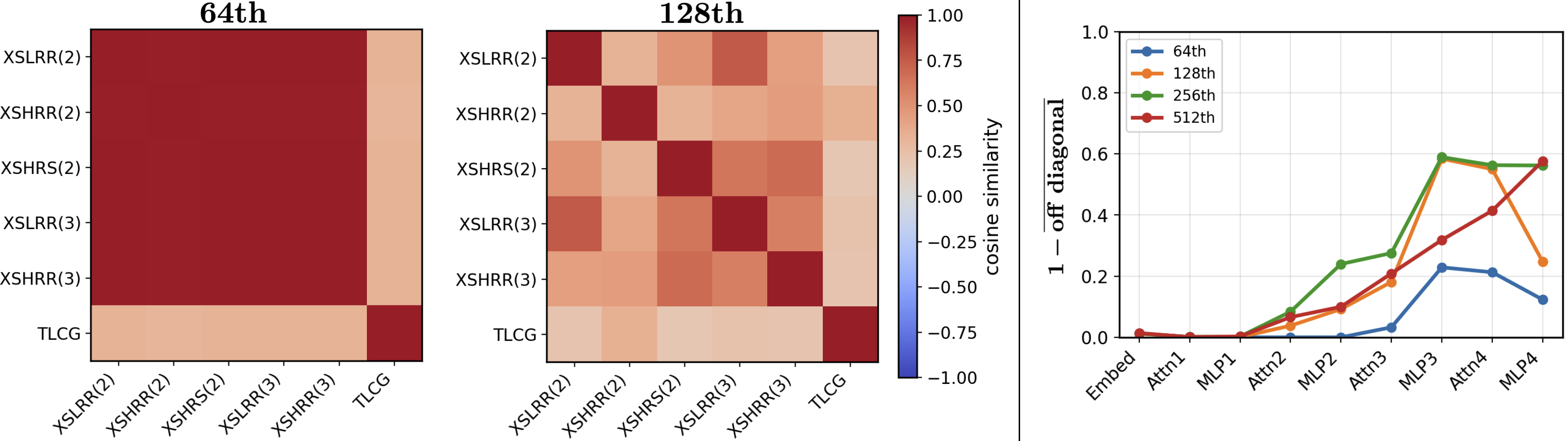
When trained on combined datasets, the model develops a more general, permutation-agnostic grouping of tokens, but intermediate activations in deeper layers cleanly separate different generator variants.
Figure 8: Cosine similarity of representations across PRNG variants. By the 128th token, the model’s third-layer MLP outputs cleanly separate all PCG variants.
Computational Efficiency
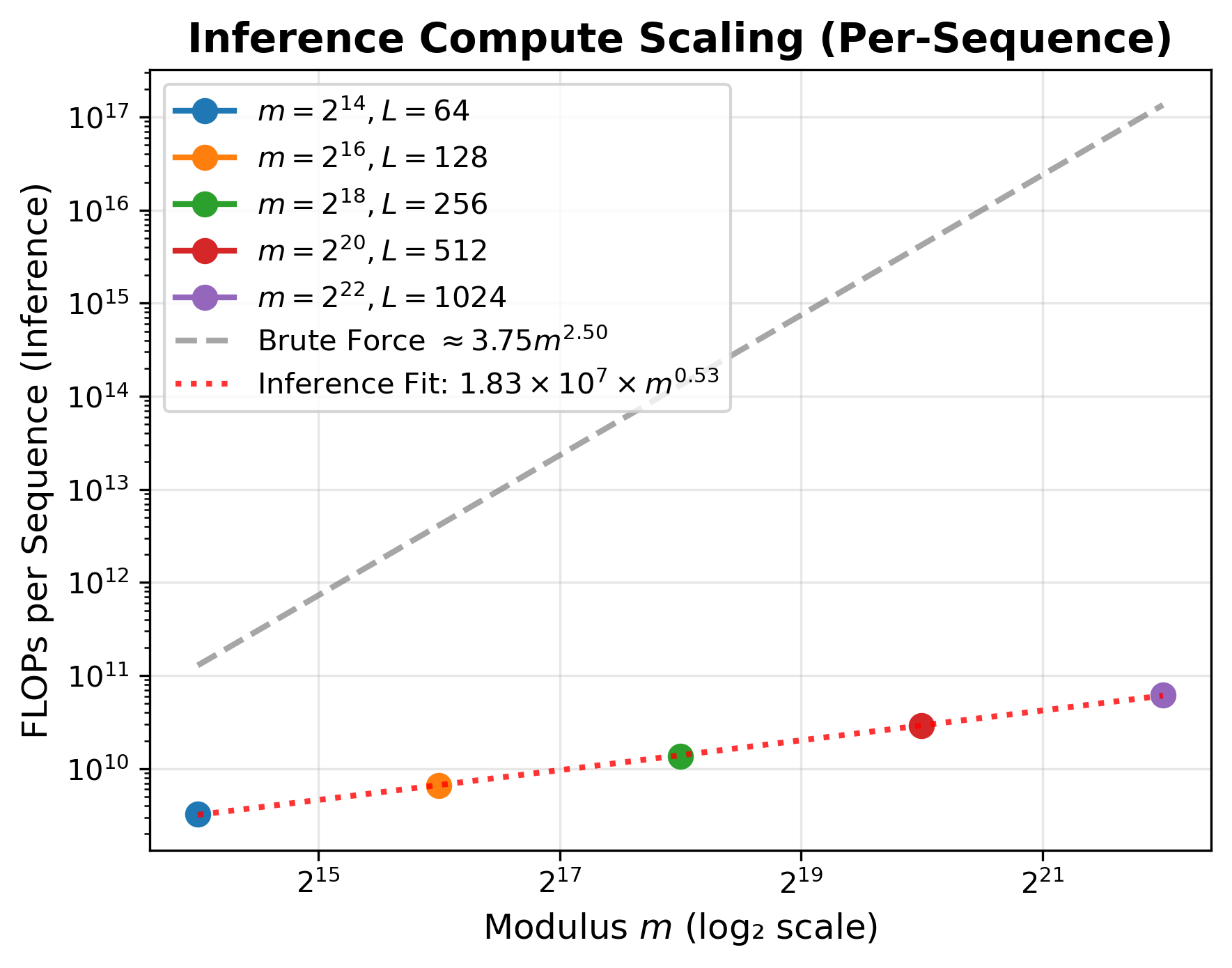
The inference compute required for Transformer-based prediction grows as m0.53 for L≤dmodel, which is substantially more efficient than brute-force search (m2.5). This demonstrates the practical viability of Transformer-based attacks on non-cryptographic PRNGs at moderate scales.
Figure 9: FLOPs scaling with modulus. Inference compute per sequence for models trained on PCGs compared to brute-force baseline.
Implications and Future Directions
The results demonstrate that Transformers can learn to predict outputs of complex, non-cryptographic PRNGs, including PCGs, in regimes beyond the reach of classical algebraic attacks. The scaling law with modulus and the necessity of curriculum learning for large-scale generalization provide concrete guidance for both the design of robust PRNGs and the application of sequence models to algorithmic tasks. The emergence of rotation-invariant clustering in the embedding space suggests that Transformers can internalize and exploit deep symmetries in algorithmic data.
From a cryptanalytic perspective, while the models do not threaten cryptographically secure PRNGs, the findings highlight the need for caution in using non-cryptographic generators in adversarial settings. The demonstrated efficiency of Transformer-based attacks relative to brute-force baselines motivates further research into the limits of neural cryptanalysis, the development of more efficient architectures (e.g., state-space models), and the interpretability of learned algorithmic representations.
Conclusion
This study provides a comprehensive analysis of the ability of Transformer models to learn and predict sequences from permuted congruential generators. The work establishes new scaling laws, demonstrates the necessity of curriculum learning for large-scale generalization, and uncovers interpretable structure in the learned representations. These findings have significant implications for both the theory of in-context learning and the practical security of widely used PRNGs. Future research should explore the extension of these methods to cryptographically secure generators, the mechanistic understanding of learned algorithms, and the design of architectures tailored for algorithmic reasoning.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.