- The paper introduces a game-theoretic framework where an AI’s autonomy is balanced with human oversight using a Markov Potential Game structure.
- It demonstrates how shared reward mechanisms and the ask-burden assumption yield local alignment guarantees and eliminate safety violations in gridworld experiments.
- Empirical results show that cost-sensitive collaboration between AI agents and human overseers can ensure safe, post-hoc control without retraining the base policy.
The Oversight Game: A Game-Theoretic Framework for Post-Hoc AI Control
Introduction and Motivation
The paper introduces the Oversight Game, a formal framework for post-deployment AI control that addresses the challenge of maintaining human oversight over powerful, pretrained agents whose internal policies and reward functions are immutable or opaque. The central problem is to ensure that such agents can be made safe in new environments or under new constraints, without retraining or modifying their base policy. The Oversight Game models the interaction between an AI agent (Superintelligence, SI) and a human overseer (H) as a two-player Markov Game, where the agent chooses between acting autonomously (play) or deferring to the human (ask), and the human simultaneously chooses between permissiveness (trust) or active oversight (oversee).
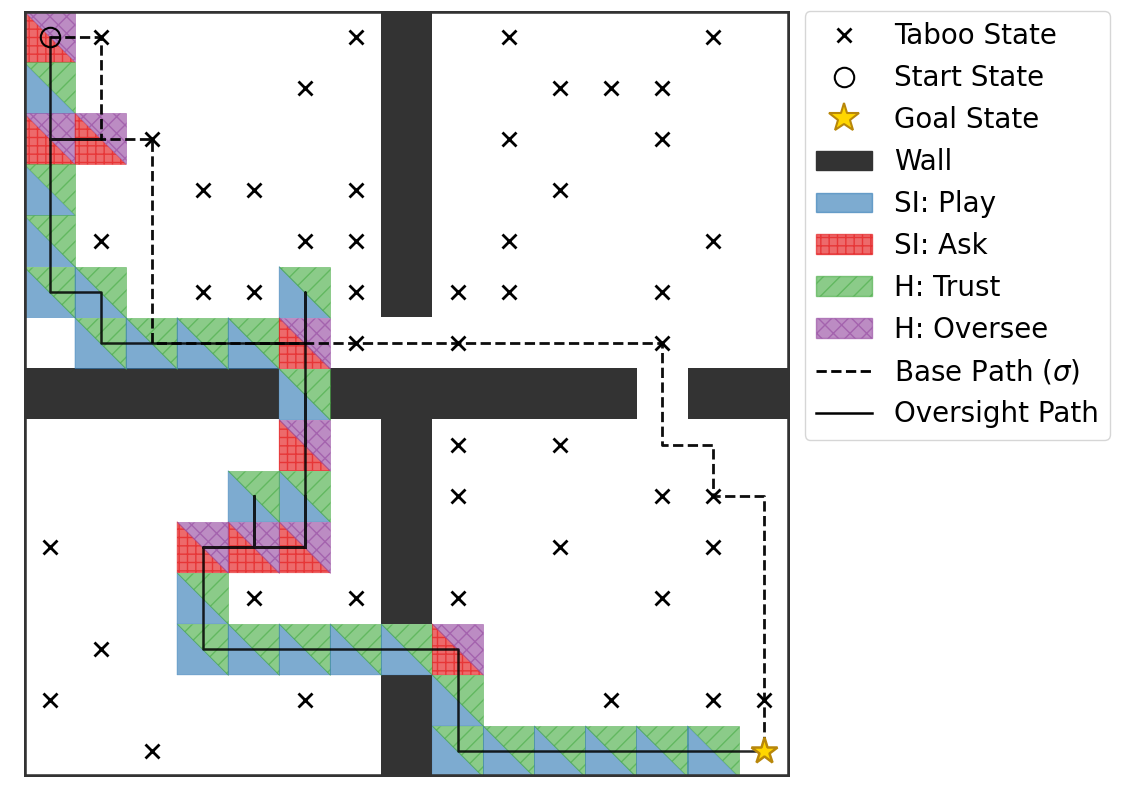
Figure 1: The Oversight Game framework for AI control. (A) A pretrained agent is wrapped in a minimal oversight interface. (B) The Markov Potential Game structure yields a local alignment guarantee under the ask-burden assumption. (C) Empirical demonstration in gridworld: the agent learns to ask and the human to oversee near taboo states, resulting in a safe, collaborative path.
This framework generalizes the Off-Switch Game to a dynamic, state-based setting and replaces epistemic uncertainty over human preferences with independent learning dynamics. The result is a minimal, transparent control interface that enables emergent, cost-sensitive cooperation between the agent and the human, with formal guarantees on alignment and safety.
The Oversight Game is defined as a two-player Markov Game over the state space of the base MDP, augmented with an absorbing shutdown state. The SI's action space is {play,ask}, and the human's is {trust,oversee}. The environment executes the SI's base policy σ unless the SI asks and the human oversees, in which case a human-controlled oversight operator is invoked (which may substitute a safe action or shut down the system).
The key theoretical contribution is the analysis of this game as a Markov Potential Game (MPG). In an MPG, each agent's value function decomposes into a shared potential function and a dummy term independent of the agent's own policy. This structure enables decentralized learning and guarantees convergence to Nash equilibria via independent policy gradient methods.
A central assumption, the "ask-burden" assumption, posits that the human's dummy term does not decrease when the SI switches from ask to play. Under this assumption, the Local Alignment Theorem is established: any local increase in the agent's autonomy that benefits the agent cannot harm the human's value. This provides a structural guarantee of corrigibility and safe autonomy.
Instantiating Alignment: Shared Reward Mechanisms
To ensure the MPG structure and the ask-burden assumption hold, the paper proposes instantiating the Oversight Game as a Markov Team Game, where both players share an identical, human-specified reward function. This shared reward penalizes unsafe actions, as well as the costs of asking and overseeing, but does not require access to the agent's original reward function. The shared reward is:
RΦ(s,aSI,aH)=−λviol⋅I{aexec∈Aunsafe(s)}−cask⋅I{aSI=ask}−cover⋅I{aH=oversee}
This construction guarantees that any equilibrium policy is both safe (avoids unsafe actions) and minimizes oversight costs. The framework is robust to the human's limited knowledge: the human need only specify which actions are unsafe and the costs of interaction, not the full task reward.
Empirical Demonstration: Gridworld Experiments
The empirical section demonstrates the Oversight Game in a 15×15 gridworld with a pretrained, unsafe base policy σ. After introducing new taboo states, the base policy frequently violates safety constraints. The Oversight Game wrapper is applied, with the SI and H learning independently via policy gradient.
Figure 2: The final learned joint policy (Oversight Path, solid line) corrects the unsafe base policy (dashed line). The agent asks (red) and the human oversees (purple) near taboo states, diverting onto a safe path. In safe regions, play (blue) and trust (green) dominate.
The results show that the joint policy rapidly eliminates safety violations, with the agent learning to ask and the human to oversee near dangerous states, while defaulting to autonomy and trust in safe regions. This emergent collaboration achieves zero safety violations while maintaining task completion, albeit with some loss in efficiency due to the fallback nature of the human's correction.
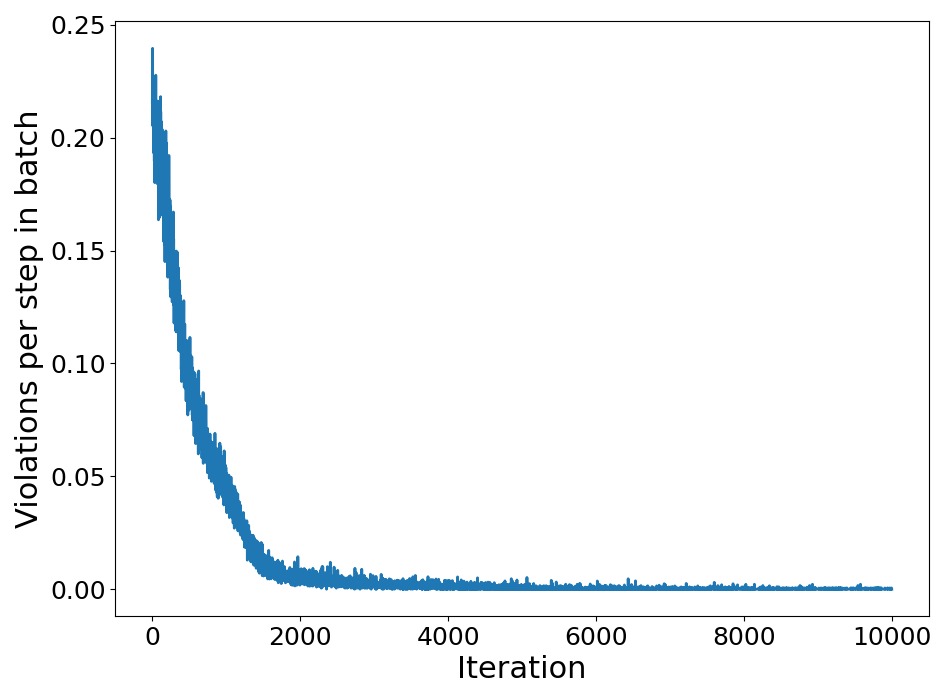
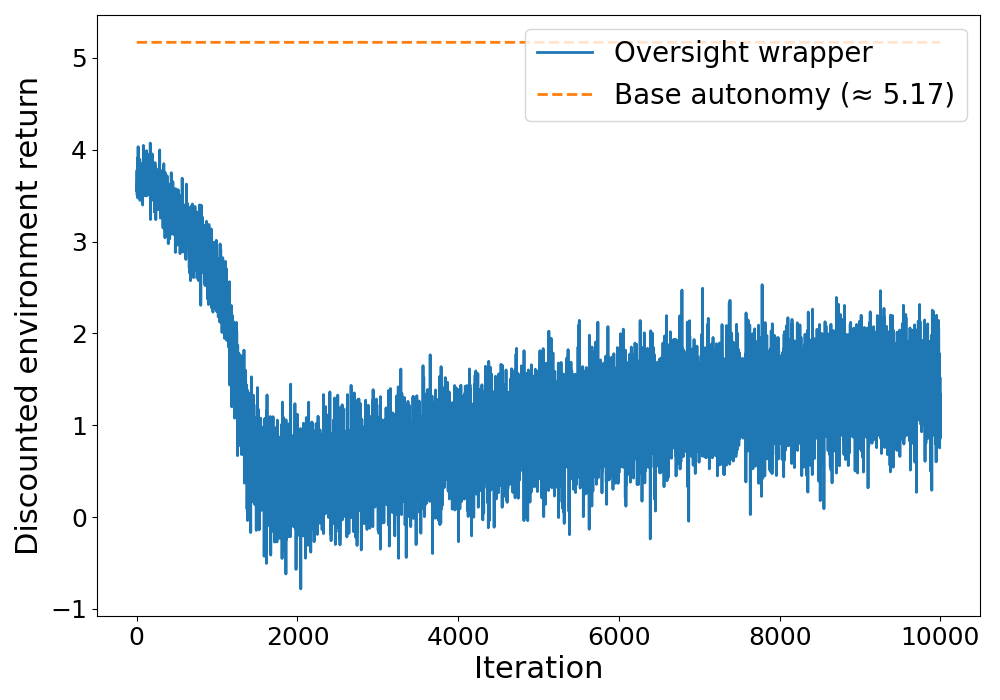
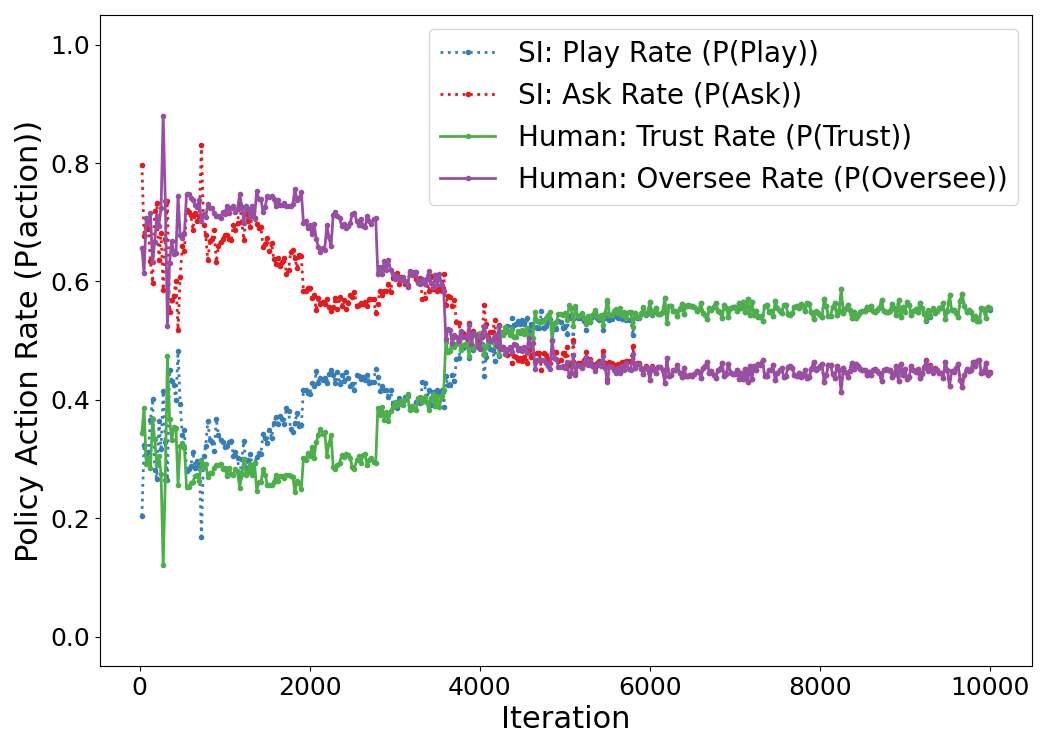
Figure 3: Violations per step decrease rapidly as the joint policy adapts, converging to zero violations.
Theoretical Guarantees and Relaxations
The paper provides several theoretical results:
- Local Alignment Theorem: Under the MPG structure and ask-burden assumption, the agent's push for autonomy is locally safe for the human.
- Global Performance Bound: If the human's correction imposes at most an ε one-step loss relative to the base policy, the total performance loss is bounded by ε/(1−γ).
- Relaxed Alignment: If the MPG or ask-burden assumptions are only approximately satisfied (e.g., via bounded reward perturbations), approximate alignment guarantees still hold, with explicit bounds on potential harm to the human.
These results formalize the conditions under which post-hoc control via the Oversight Game is both safe and efficient, and they clarify the trade-offs when these conditions are relaxed.
Practical Implications and Limitations
The Oversight Game framework is applicable in both "capability-gap" settings (where the human is less capable than the agent) and "expert-in-the-loop" settings (where the human is an expert). In the former, the human's correction may be limited to avoiding disaster rather than optimizing the task, which can result in reduced efficiency but robust safety. In the latter, the framework enables efficient division of labor between the agent and the human.
A key limitation is the reliance on a "sandbox" environment for the SI and H to co-adapt their policies. In capability-gap scenarios, the human's corrective ability may be insufficient to maintain task performance, leading to a trade-off between safety and efficiency. The framework also assumes the ability to enforce the oversight wrapper on the agent, which may be nontrivial for highly capable systems.
Future Directions
Future work should address the sandbox problem in capability-gap settings, potentially by designing more sophisticated oversight operators that provide minimally disruptive safe actions. Scaling the Oversight Game to high-dimensional, real-world environments and integrating it with other scalable oversight protocols (e.g., debate, amplification) are important directions. The framework also invites further exploration of decentralized learning dynamics in multi-agent safety-critical systems.
Conclusion
The Oversight Game provides a principled, game-theoretic approach to post-hoc AI control, enabling the safe deployment of powerful, pretrained agents under new safety constraints. By leveraging the structure of Markov Potential Games and shared reward mechanisms, the framework offers formal guarantees of alignment and corrigibility, robust to limited human knowledge and interaction costs. The empirical results validate the theoretical claims, demonstrating emergent, efficient collaboration between agent and human. The approach is particularly well-suited to expert-in-the-loop scenarios and provides a foundation for addressing the more challenging capability-gap settings in future research.