- The paper introduces GRPO as a critic-free alternative to traditional PPO, demonstrating efficient advantage estimation through group sampling.
- It adapts GRPO to both on- and off-policy frameworks, yielding empirical improvements in sample efficiency and reducing computational overhead.
- The work offers theoretical guarantees and empirical evidence for stable reward improvement, highlighting the adaptability of off-policy training.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
Introduction to Proximal Policy Optimization
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm known for improving stability during training and controlling sample efficiency. In scenarios like Reinforcement Learning from Human Feedback (RLHF) or from Verifiable Rewards, post-training of LLMs often aims to align with human values or enhance reasoning capabilities. Traditional PPO achieves this through a critic network that estimates the advantage function. The focus of this research paper is on enhancing PPO's efficiency by revisiting and adapting Group Relative Policy Optimization (GRPO), particularly in adapting it for both on-policy and off-policy regimes.
Group Relative Policy Optimization (GRPO)
Group Relative Policy Optimization diverges from standard PPO by removing the need for a separate critic network. Instead, GRPO computes a standardized reward using Monte Carlo sampling, where a group of samples is used to estimate the advantage function. This is particularly useful as it simplifies the PPO framework and reduces reliance on complex architectures. GRPO provides a unique benefit by estimating advantage functions using groups, thus enabling reinforcement learning models to be updated more efficiently, which has been seen in several open-source implementations, lending itself to rapid community adoption.
On-Policy and Off-Policy GRPO
The on-policy version of GRPO maintains its traditional advantage where policies are updated using samples from the current policy iteration. However, this paper introduces an off-policy variant, where advantage is estimated using samples from a previous policy iteration. This advancement allows for the inclusion of samples from policies that might differ from the current policy but still contribute to learning.
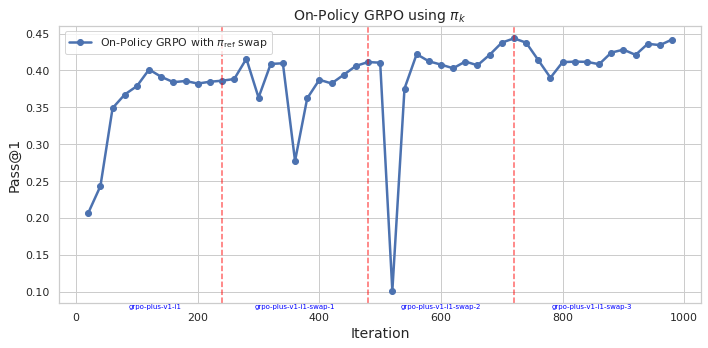
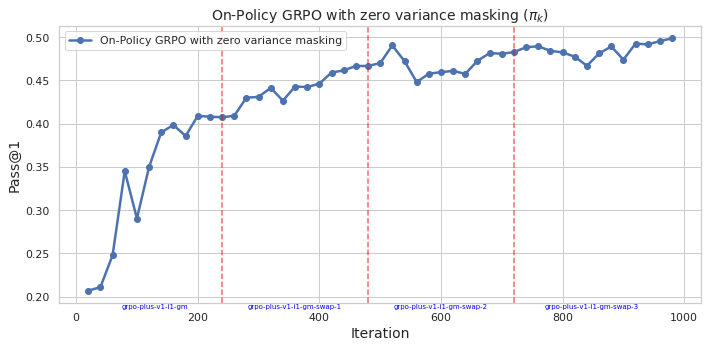
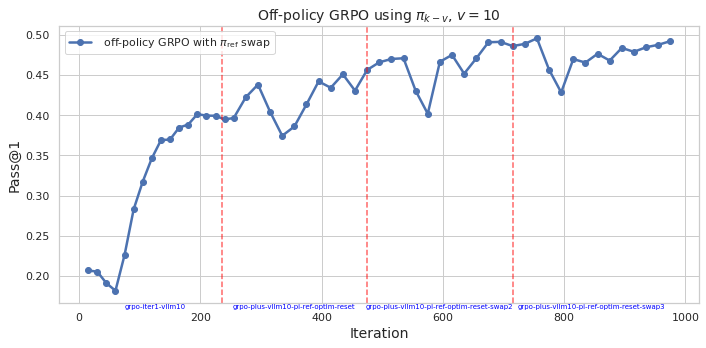
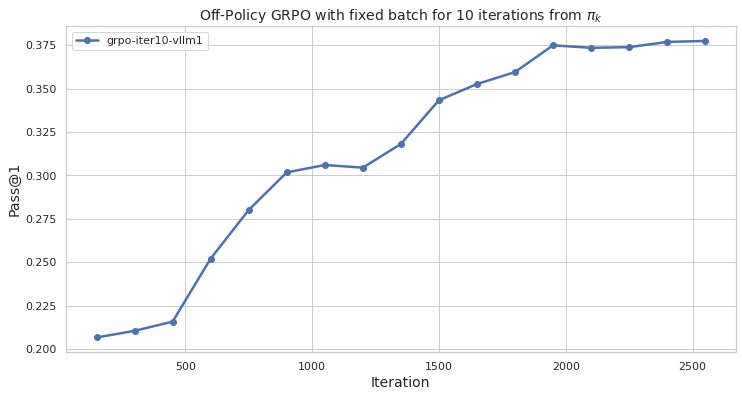
Figure 1: On-Policy GRPO with πref.
The development of off-policy GRPO draws parallels to the Proximal Policy Optimization evolution, where sample efficiency is crucial. By using a clipped surrogate objective derived from first principles, the paper shows both theoretical and empirical evidence that off-policy GRPO may outperform on-policy versions or at least match them, offering improved efficiency regarding resource allocation when executing policy updates.
Off-Policy GRPO: Theoretical Foundations and Empirical Analysis
Off-policy GRPO builds on empirical observations that off-policy behavior can be beneficial. The paper introduces theoretical guarantees ensuring that updates in the off-policy regime will lead to reward improvement, provided certain conditions are maintained. These guarantees are crucial for practical implementations, ensuring that reward optimization is both stable and efficient, avoiding detrimental divergences that can arise from improper sample usage.
The empirical evaluation of off-policy GRPO shows significant potential, either outperforming or equaling on-policy GRPO. The practical benefit here is the reduction in overhead from communication during model serving, a critical factor when deploying in environments where computational resources are at a premium, such as large distributed systems.
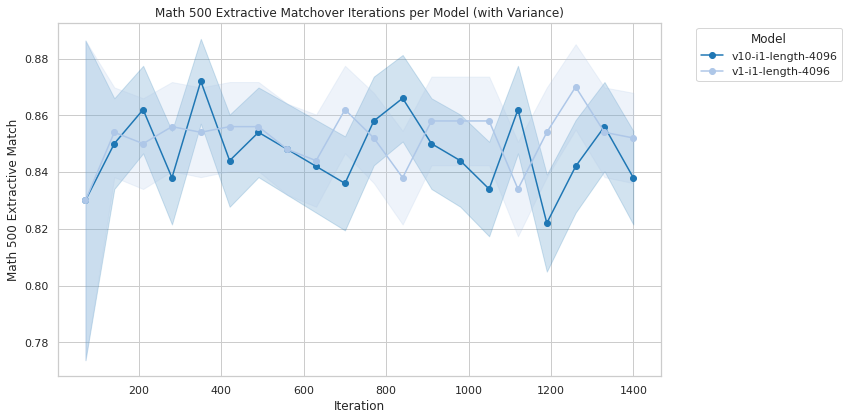
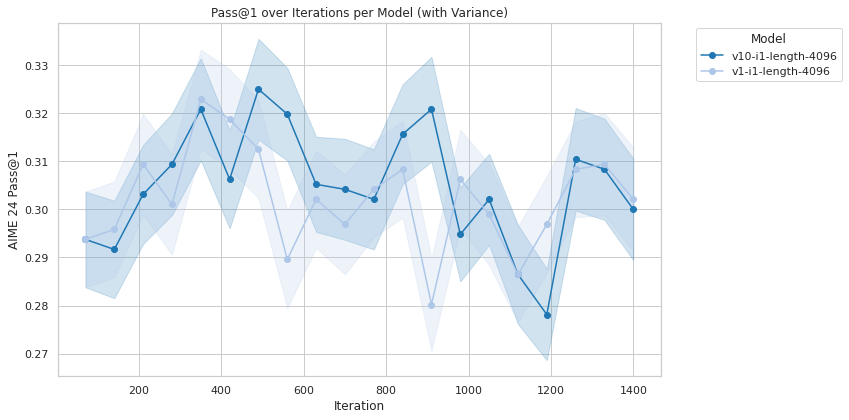
Figure 2: Aime 24.
Implications and Future Directions
The implications of integrating off-policy GRPO into existing reinforcement learning frameworks are numerous. Primarily, it reduces the computational and sample complexity of training large models, encouraging broader adoption in production environments constrained by resources. Additionally, this framework's modular nature makes it adaptable to other off-policy methods within reinforcement learning, potentially broadening its applications beyond LLMs to other domains.
Looking ahead, further exploration into the scalability of off-policy GRPO in more complex environments and model architectures will be crucial. There is potential for even more optimization through techniques like distributed computing or parallelized sample gathering, ensuring reinforcement learning remains applicable as models and data continue to grow.
Conclusion
Revisiting Group Relative Policy Optimization through the lens of on-policy and off-policy training has presented both theoretical and empirical advancements in reinforcement learning efficiency. Integrating these findings may lead to steps where reinforcement learning can be applied more broadly and efficiently across industries, ensuring that AI remains aligned with increasingly complex human values and operational constraints.