SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity
Abstract: Recent advances in text-to-speech (TTS) synthesis have significantly improved speech expressiveness and naturalness. However, most existing systems are tailored for single-speaker synthesis and fall short in generating coherent multi-speaker conversational speech. This technical report presents SoulX-Podcast, a system designed for podcast-style multi-turn, multi-speaker dialogic speech generation, while also achieving state-of-the-art performance in conventional TTS tasks. To meet the higher naturalness demands of multi-turn spoken dialogue, SoulX-Podcast integrates a range of paralinguistic controls and supports both Mandarin and English, as well as several Chinese dialects, including Sichuanese, Henanese, and Cantonese, enabling more personalized podcast-style speech generation. Experimental results demonstrate that SoulX-Podcast can continuously produce over 90 minutes of conversation with stable speaker timbre and smooth speaker transitions. Moreover, speakers exhibit contextually adaptive prosody, reflecting natural rhythm and intonation changes as dialogues progress. Across multiple evaluation metrics, SoulX-Podcast achieves state-of-the-art performance in both monologue TTS and multi-turn conversational speech synthesis.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-read overview
This paper introduces SoulX-Podcast, an AI system that can create long, natural-sounding podcast conversations between multiple speakers. Unlike most text-to-speech (TTS) tools that read a single voice aloud, SoulX-Podcast handles multi-person, multi-turn dialogue, supports nonverbal sounds like laughter and sighs, and can speak in Mandarin, English, and several Chinese dialects (Sichuanese, Henanese, Cantonese). It aims to make AI-made podcasts feel realistic and consistent for a long time—over 90 minutes—without voices drifting or sounding fake.
What questions did the researchers ask?
The authors focused on simple but important questions:
- Can we make AI voices hold a smooth, realistic conversation between several people for a long time?
- Can the system control extra “human” sounds (like laughter or breathing) and speaking style (rhythm, tone) so the dialogue feels alive?
- Can it switch between languages and dialects—and even clone a person’s voice into another dialect—using only a short audio example?
- Can it do all that while still being great at normal TTS (reading text with a single voice)?
How did they build it? (Methods in everyday language)
Think of the system like a team putting on a radio show:
- The scriptwriter (a LLM, or LLM) plans what is said and how it should sound.
- The director adds stage directions—who is speaking, what dialect they’re using, and any nonverbal sounds like “laughter” or “sigh.”
- The sound engineer turns the plan into real audio.
More concretely:
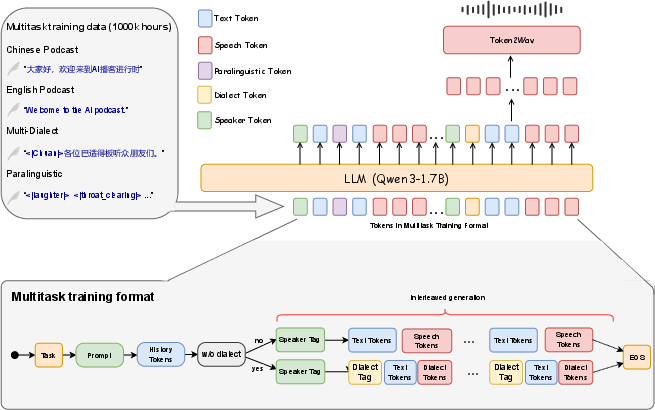
- They use an LLM (Qwen3-1.7B) that reads sequences mixing text and “speech tokens.” Tokens are like small LEGO pieces that represent bits of text or sound.
- The system arranges conversation as an interleaved timeline: for each turn, it places the speaker label, the dialect tag, the words, and then the speech tokens. Then the next speaker’s turn follows in order. This keeps track of who speaks when, in what style, and with which voice.
- A “flow matching” module and a vocoder then turn these speech tokens into the final audio waveform (what you hear).
Data collection and labeling (made simple):
- They assembled a huge training set (about 1.3 million hours total): around 0.3 million hours of real conversations and 1.0 million hours of solo speech.
- To clean messy real-world audio, they removed background music/noise, split long recordings into shorter parts, and used speaker diarization (figuring out “who spoke when”).
- They double-checked transcripts with two different speech recognizers and filtered out low-quality parts.
- They labeled nonverbal sounds (paralinguistic cues) like laughter and sighs, first with automatic tools and then with an AI helper to refine the timing and type.
- They also gathered and labeled dialect data: about 2,000 hours of Sichuanese, 1,000 of Cantonese, and 500 of Henanese.
Training tricks to make it work:
- Curriculum learning: first train on lots of single-speaker data to learn the basics, then specialize on dialogue and dialects.
- Context regularization: during training, the model sometimes “forgets” old audio tokens but keeps the text history, so it learns to stay coherent over long stretches without getting stuck repeating sounds.
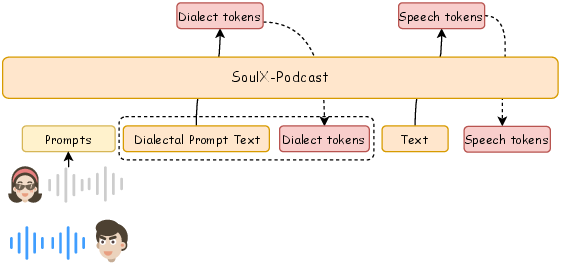
- Dialect-Guided Prompting (DGP): to clone a voice across dialects, the model starts with a short, very “dialect-typical” sentence in the target dialect. This acts like a tuning fork, steering the voice into the right dialect even if the original prompt voice was in Mandarin.
Key terms, simplified:
- TTS (text-to-speech): turning written text into spoken audio.
- Paralinguistics: non-word sounds and speaking cues—laughter, sighs, breaths, coughs, tone, and rhythm.
- Dialect: a regional way of speaking the same language (different sounds, words, or expressions).
- Voice cloning: using a short audio clip to copy someone’s voice style into new speech.
What did they find? (Main results and why they matter)
The team tested SoulX-Podcast on both normal TTS and multi-speaker podcast-style conversation.
Monologue (single voice) TTS:
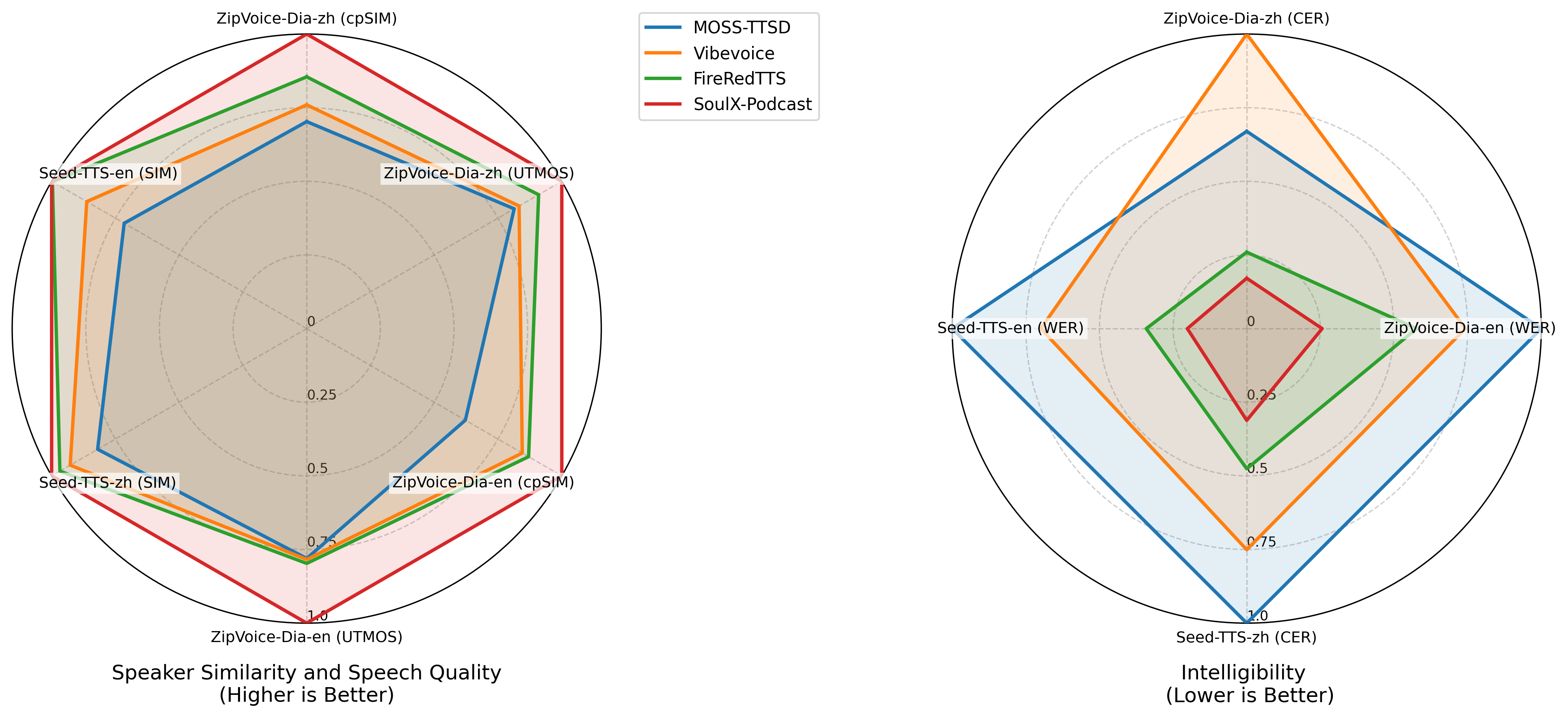
- It made fewer text mistakes than most other top systems in Chinese and was near the top in English.
- It kept voice similarity high (the AI voice sounded a lot like the target voice in cloning tests).
Dialogue (multi-speaker) generation:
- On a long-dialogue benchmark, it made fewer word errors and kept each speaker’s voice consistent better than other systems.
- It can run for over 90 minutes while keeping voices stable and transitions smooth.
- Prosody (speaking rhythm and intonation) adapts to the context, making dialogue sound less robotic and more human.
Paralinguistic control:
- When asked to include certain sounds, like laughter or a sigh, the system did so correctly most of the time (about 82% overall, perfect for laughter, strong for sighs and throat clearing).
Dialect support:
- The system speaks Sichuanese, Henanese, and Cantonese as well as Mandarin and English.
- It can do cross-dialect voice cloning: for example, use a short Mandarin voice sample and then speak in Sichuanese in the same voice style, guided by the DGP method.
Why this matters:
- Realistic, long, multi-person audio is hard—voices can drift, switch, or sound flat. Getting stable, expressive, multi-dialect conversations unlocks more lifelike podcasts, audiobooks, role-play tutoring, and more.
What’s the impact? (So what?)
If used responsibly, systems like SoulX-Podcast could:
- Power engaging, long-form podcasts and dramas without hiring many voice actors.
- Help with language and dialect learning by providing clear, natural examples.
- Make educational content, audiobooks, and game dialogues more expressive and inclusive (including regional dialects).
- Speed up localization and dubbing for videos and films.
The authors also emphasize ethics:
- Synthetic voices can be misused for impersonation or misinformation.
- They recommend safeguards like consent, watermarking, and misuse detection, and they position the system for research and responsible applications.
In short, SoulX-Podcast is a strong step toward AI that can “host” realistic, long, multi-speaker shows—complete with natural timing, emotions, and dialect variety—while still being excellent at regular text-to-speech tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of unresolved issues that future work could address to strengthen the claims and broaden the applicability of SoulX-Podcast.
- Absence of human listening studies: no crowd or expert MOS, ABX, or preference tests for dialogue naturalness, turn-taking smoothness, paralinguistic realism, or dialect authenticity; automated proxies (UTMOS, cpSIM, LLM-based detectors) lack validation against human judgments.
- Unclear definition and validation of
cpSIM: the metric is not formally defined, and its correlation with human-perceived speaker coherence across turns is unknown; needs calibration and reliability analysis. - No ablations on key components: interleaved text–speech sequencing, curriculum learning, context regularization (dropping historical speech tokens), and Dialect-Guided Prompting (DGP) lack controlled studies quantifying individual contributions.
- Long-form robustness under length and topic shifts: claims of >90 minutes are not accompanied by measurements of timbre drift, prosody stability, intelligibility degradation, or memory footprint over time; systematic stress tests are missing.
- Overlapped speech and interruptions: real podcasts often include crosstalk, interruptions, and backchannels; current interleaved sequencing appears to preclude overlap, and the system’s ability to render realistic overlap is not evaluated.
- Real-time and streaming constraints: inference latency, throughput, and resource usage (GPU/CPU, memory) are not reported; feasibility for live, interactive podcast production remains unknown.
- Paralinguistic control granularity: the system supports a small set of discrete events, but lacks controls for intensity, duration, onset timing, coarticulation with speech, and overlapping events; no evaluation of how these cues affect intelligibility and conversational appropriateness.
- Paralinguistic evaluation confined to monologues: controllability and realism of nonverbal events within multi-speaker dialogues (e.g., aligned laughter, breathing during turn-taking) are not assessed.
- Dialect coverage and generalization: support is limited to Sichuanese, Henanese, and Cantonese; scalability to other Chinese dialects and accents (and non-Chinese varieties) and data requirements for low-resource dialects are unexplored.
- Dialect authenticity and sociophonetic fidelity: high CERs are attributed to ASR limitations without human validation; native-speaker ratings, accent identification, and sociophonetic analyses are needed to confirm genuine dialectal realizations.
- Reliance on DGP (prepended dialect-typical sentence): dialect control depends on a priming utterance; methods for robust dialect conditioning without prompt engineering (e.g., stronger conditioning tokens, phonetic/tonal conditioning) are not investigated.
- Phonetic/tonal modeling across dialects: the approach appears text-driven without explicit phoneme- or tone-level conditioning; the impact on dialectal prosody, tone sandhi, and phonotactic patterns remains unclear.
- Code-switching capability: mixed-language and mixed-dialect dialogues (intra-utterance and inter-turn) are not evaluated; mechanisms to control and measure code-switching frequency and placement are absent.
- Speaker diarization and purity refinement quality: diarization accuracy, clustering thresholds, and error rates are not quantified; downstream impact of diarization errors on speaker stability in synthesis is unknown.
- Data composition transparency and bias: the 1.3M-hour corpus lacks detailed breakdowns (domains, topics, gender/age/geography, recording conditions); no fairness or bias analyses (e.g., accent/gender performance gaps) are provided.
- Dataset availability and reproducibility: the training corpus is not released; licensing, sourcing, and replicable data recipes are missing, hindering independent verification and scaling studies.
- Background ambience and soundscapes: recordings were denoised via UVR-MDX, but real podcasts include ambient music, room acoustics, and Foley; controllable background rendering and its effect on realism are not modeled or evaluated.
- Emotion and conversational style control: beyond discrete paralinguistics, there is no explicit control over emotions, speaker personas, or conversation-level style arcs; evaluation of listener engagement or narrative flow is absent.
- Safety mechanisms are declarative, not implemented: watermarking, consent gating, and misuse detection are recommended but not integrated; empirical robustness against voice spoofing or impersonation remains untested.
- Cross-dialect voice cloning trade-offs: the balance between preserving speaker identity and achieving target dialect characteristics is not quantified; potential identity drift during dialect transfer needs measurement.
- Training and model specifics: optimization hyperparameters, compute budget, tokenizer design for “semantic tokens,” vocoder architecture, sampling rate, and flow-matching details are under-specified; hinders reproducibility and targeted improvements.
- Robustness to noisy or imperfect training transcripts: the pipeline discards audio with high CER/WER while retaining text; the effect of such filtering and text–audio mismatches on training and synthesis quality is not analyzed.
- Comparative evaluation protocol transparency: prompt design, conditioning, and test-time settings for baselines are not fully described; fairness of comparisons and sensitivity to prompt variations are unknown.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging SoulX-Podcast’s demonstrated capabilities: multi-speaker, multi-turn TTS; paralinguistic controls; Mandarin/English plus Sichuanese, Henanese, Cantonese dialect support; cross-dialect zero-shot voice cloning via DGP; and the scalable dialogue data processing pipeline.
- Bold use case: AI podcast production studio
- Sector: media/creator economy, software
- Description: Generate full-length, multi-speaker podcast episodes (>90 minutes) from scripts, with stable speaker timbre, smooth turn transitions, and context-adaptive prosody. Include dialect episodes and expressive cues (laughter, sighs) to match genre/style.
- Tools/products/workflows: A “Creator Studio” built on SoulX-Podcast codebase; script import; speaker token assignment; paralinguistic token insertion; dialect tokens; batch synthesis; QC via UTMOS and cpSIM.
- Assumptions/dependencies: GPU resources for long-form synthesis; rights/consent for any voice cloning; watermarking and disclosure for synthetic audio; DGP for cross-dialect style priming.
- Bold use case: Audiobook dramatization (multi-character narration)
- Sector: publishing, education, media
- Description: Convert novels and textbooks into expressive dramatized audio featuring multiple characters and controllable nonverbal cues (e.g., laughter, sighs).
- Tools/products/workflows: TTS pipeline with per-character speaker tokens; per-scene paralinguistic labels; dialect toggles for regional editions; batch render for chapters.
- Assumptions/dependencies: Text rights; character voice branding; editorial QC; paralinguistic accuracy ~0.82 may need manual spot checks for subtle cues.
- Bold use case: Multi-dialect localization for ads and corporate content
- Sector: marketing, enterprise communications
- Description: Create consistent brand voice across Mandarin plus Sichuanese/Henanese/Cantonese variants without re-recording, using cross-dialect cloning.
- Tools/products/workflows: DGP priming sentence before each localized script; speaker identity retained via zero-shot cloning; corpus-level QC using SIM and cpSIM.
- Assumptions/dependencies: Dialect coverage currently limited to three Chinese dialects; ASR-based CER evaluation varies by dialect; local compliance for synthetic voice disclosures.
- Bold use case: Customer service role-play training
- Sector: BPO/customer support, finance, telecom
- Description: Generate realistic multi-turn call scenarios with dialectal variation, prosodic realism, and controlled paralinguistics (e.g., coughing, sighs) to simulate difficult interactions.
- Tools/products/workflows: Dialogue scenario generator with speaker labels and dialect tokens; playback and assessment modules; cpSIM-based coherence checks.
- Assumptions/dependencies: Latency not critical for offline training; ensure ethical use (no impersonation); privacy-safe synthetic data only.
- Bold use case: Game and interactive narrative voice assets
- Sector: gaming, entertainment
- Description: Create multi-speaker cutscenes and NPC conversations with expressive cues and dialectal flavor; generate sound libraries for laughter, sighs, coughs, and throat clearing.
- Tools/products/workflows: Asset generator with paralinguistic token catalog; scene-level multi-speaker sequencing via interleaved token organization; integration with existing audio middleware.
- Assumptions/dependencies: Final mixing and FX may be required; runtime generation may need optimization for latency.
- Bold use case: Expressive screen readers and accessibility audio
- Sector: accessibility, education
- Description: Produce more natural read-aloud content with controllable prosody and subtle nonverbal cues to maintain listener engagement; offer dialect variants for inclusivity.
- Tools/products/workflows: Screen-reader plugin with prosody and paralinguistics toggles; dialect selection for regional users.
- Assumptions/dependencies: Content appropriateness of nonverbal cues; real-time performance constraints for long documents.
- Bold use case: Language learning materials with dialect exposure
- Sector: education
- Description: Generate lesson dialogues in target dialects, emphasizing regional pronunciation/prosody with DGP priming; include expressive cues for conversational realism.
- Tools/products/workflows: Curriculum builder that inserts dialect tokens and priming sentences; comprehension checks; CER/WER-based intelligibility metrics for quality control.
- Assumptions/dependencies: Pedagogical validation and instructor oversight; expand dialect coverage for broader use.
- Bold use case: Pre-visualization for dubbing and ADR
- Sector: film/TV production
- Description: Generate temporary dialogue tracks to guide pacing and performance before studio recordings; enable quick dialect variants for test screenings.
- Tools/products/workflows: Rapid TTS of multi-speaker scenes; paralinguistic cues for emotional beats; import to editing timelines; final ADR replaces temp tracks.
- Assumptions/dependencies: Not final broadcast quality in all cases; legal compliance for any cloned voices; watermarking for temp assets.
- Bold use case: Meeting/Workshop simulations for corporate training
- Sector: enterprise L&D
- Description: Synthetic multi-speaker simulations of negotiations, performance reviews, incident response drills—configurable tone and paralinguistics to convey stress/empathy.
- Tools/products/workflows: Scenario templates; speaker token assignment per role; prosody controls; cpSIM used for coherence across turns.
- Assumptions/dependencies: Ethical design (no targeted impersonation); content accuracy; offline generation preferred.
- Bold use case: ASR/TTS research data augmentation
- Sector: academia/industry research
- Description: Generate large-scale synthetic conversational corpora with diverse speakers and dialects to improve robustness of ASR/TTS models.
- Tools/products/workflows: Use the SoulX-Podcast dialog generation; annotate via built-in pipeline (VAD, diarization, DNSMOS filtering, dual-ASR transcription); paralinguistic mining to diversify labels.
- Assumptions/dependencies: Synthetic-vs-real domain gap; labeling fidelity; rigorous train/test separation to avoid leakage.
- Bold use case: Large-scale dialogue data processing workflow reuse
- Sector: data engineering, speech tech
- Description: Apply the paper’s pipeline—UVR-MDX separation, VAD segmentation, Sortformer diarization, DNSMOS filtering, dual-ASR transcription, speaker-purity clustering—to clean and structure noisy conversational corpora.
- Tools/products/workflows: Modular pipeline as a productized “speech data curation” toolkit; plug-and-play in-house data processing.
- Assumptions/dependencies: Access to models/APIs (Whisper, Paraformer, Parakeet, Gemini-like verifier); compute; license compliance for datasets.
- Bold use case: Prosody A/B testing for marketing scripts
- Sector: marketing/advertising
- Description: Systematically vary prosody and paralinguistic cues to test listener engagement, recall, and perceived brand warmth across dialects.
- Tools/products/workflows: Controlled synthesis experiments; measurement via UTMOS, intelligibility (CER/WER), and human preference studies.
- Assumptions/dependencies: Experimental design and IRB-like oversight for user studies; ensure disclosure of synthetic audio.
Long-Term Applications
The following applications require further research, scaling, robustness, latency optimization, expanded language/dialect coverage, or additional safeguards before widespread deployment.
- Bold use case: Real-time, multi-speaker streaming TTS for live events
- Sector: media/live production, social audio
- Description: On-the-fly generation of multi-party dialogues with low latency and stable prosody.
- Dependencies: Streaming-capable acoustic modeling and vocoders; efficient token prediction; network QoS; hardware acceleration.
- Bold use case: Fully interactive, multi-dialect conversational agents
- Sector: software/virtual assistants, education
- Description: Agents handling multi-user group conversations in mixed dialects, with turn-taking, memory, and adaptive prosody.
- Dependencies: Robust ASR in dialects; dialogue management; safety/alignment; low-latency TTS; evaluation frameworks for multi-party coherency.
- Bold use case: Clinically validated therapeutic simulators and companions
- Sector: healthcare
- Description: Empathetic voice agents with controlled paralinguistics for therapy training or guided self-help.
- Dependencies: Clinical trials for efficacy/safety; bias/fairness audits; crisis-handling policies; regulatory approval.
- Bold use case: Broadcast-grade auto-dubbing across languages and dialects
- Sector: media/localization
- Description: End-to-end pipeline from translation/adaptation to expressive, dialect-accurate dubbing with lip-sync.
- Dependencies: High-accuracy translation/adaptation; phoneme-level alignment; lip-sync models; rights management and watermarked synthesis.
- Bold use case: Voice interfaces for social robots with natural multi-party skills
- Sector: robotics
- Description: Robots participating in group conversations, handling interruptions, nonverbal cues, and dialect differences.
- Dependencies: Robust speech perception; turn-taking policies; embedded hardware acceleration; safety in public spaces.
- Bold use case: Regulatory and standards ecosystem for synthetic speech
- Sector: public policy, compliance
- Description: Watermarking standards, consent protocols, impersonation safeguards, and mandatory disclosure frameworks for synthetic audio.
- Dependencies: Cross-industry consensus; technical watermark robustness; enforcement mechanisms; international harmonization.
- Bold use case: Inclusive expansion to more dialects/languages
- Sector: global education/media/accessibility
- Description: Support additional Chinese dialects and other languages to broaden reach and reduce language inequities.
- Dependencies: Curated datasets; dialect-specific ASR; community partnerships; continuous evaluation for fairness.
- Bold use case: Standardized paralinguistic generation and detection benchmarks
- Sector: academia/industry research
- Description: Shared datasets and metrics for paralinguistic fidelity, subtle event detection (e.g., breathing, coughing), and listener impact.
- Dependencies: Open benchmarks; evaluator agreement; psychoacoustic studies to validate perceptual relevance.
- Bold use case: Enterprise-grade content governance and audit trails
- Sector: finance, regulated industries
- Description: End-to-end synthetic audio lifecycle management: consent capture, watermarking, provenance tracking, and compliance reporting.
- Dependencies: Integration with IAM/GRC systems; audit dashboards; tamper-evident logging.
- Bold use case: Meeting reenactment and narrative summarization
- Sector: enterprise collaboration
- Description: Turn meeting notes into synthesized, dramatized reenactments for training or recap, preserving speaker style and dynamics.
- Dependencies: Speaker enrollment (consent), accurate diarization from original recordings, narrative QA.
- Bold use case: Video avatars with expressive, dialectal speech
- Sector: creator tools, education
- Description: Lip-synced avatars that speak in the user’s dialect with matching prosody and paralinguistics for lectures and tutorials.
- Dependencies: High-fidelity viseme alignment; latency reduction; robust phonetic modeling per dialect.
- Bold use case: Embedded watermarking at the vocoder level
- Sector: software, policy/compliance
- Description: Imperceptible, resilient watermarks in synthesized waveforms to detect misuse and ensure traceability.
- Dependencies: Novel watermark designs; adversarial robustness; standards adoption; evaluation across codecs and platforms.
Glossary
- Acoustic features: Numerical representations of audio characteristics (e.g., spectrum, pitch) used by models for synthesis or analysis. "which are then converted into acoustic features through flow matching"
- Acoustic tokens: Discrete units representing encoded audio content used by token-based generative models. "directly predicting acoustic tokens spanning multiple codebooks according to specific patterns"
- Autoregressive (AR): A modeling approach that predicts the next token conditioned on previously generated tokens. "tokens from the first layer are predicted by an autoregressive (AR) LLM"
- CER (Character Error Rate): A metric for transcription accuracy, computed as the percentage of character-level errors. "Character Error Rate (CER)"
- Codebook: A set of prototype vectors used in quantization/tokenization to map continuous signals to discrete tokens. "whose text codebook is extended"
- Context regularization: A training mechanism that reduces reliance on long acoustic histories to improve coherence over long sequences. "we introduce a context regularization mechanism that progressively drops historical speech tokens while retaining their textual context."
- cpSIM: A metric for cross-speaker consistency, typically derived from speaker embeddings across turns. "cross-speaker consistency (cpSIM)"
- Curriculum learning: A training strategy that orders data or tasks from easy to hard to improve model learning. "we adopt a curriculum learning strategy."
- Dialect-Guided Prompting (DGP): An inference technique that prepends dialect-typical text to guide dialectal style in generation. "we propose Dialect-Guided Prompting (DGP) inference strategy."
- DNSMOS: A neural estimator of perceptual speech quality, approximating human Mean Opinion Scores. "perceptual quality estimated by DNSMOS"
- Finite Scalar Quantization: A quantization scheme that maps continuous scalar values to a finite set of levels. "Finite Scalar Quantization"
- Flow matching: A generative modeling technique that learns continuous transformations between distributions for synthesis. "acoustic features via flow matching"
- LLM: A model trained on large corpora to generate and understand text or tokens across modalities. "Specifically, an LLM first predicts semantic tokens"
- Non-autoregressive (NAR): A modeling approach that generates tokens in parallel or without conditioning on previous outputs. "generated using a non-autoregressive (NAR) model."
- Paralinguistic: Nonverbal vocal signals (e.g., laughter, sighs) conveying emotion or intent, controllable in synthesis. "paralinguistic cues (e.g., laughter, sighs) are treated as textual tokens"
- Prosody: The rhythm, stress, and intonation patterns of speech affecting naturalness and expressiveness. "contextually adaptive prosody"
- Residual Vector Quantization (RVQ): A multi-stage quantization method that successively encodes residual errors to improve fidelity. "residual vector quantization (RVQ)"
- Semantic tokens: Discrete units representing linguistic/semantic content that guide acoustic generation. "predicts semantic tokens"
- Signal-to-noise ratio (SNR): A measure of audio quality comparing signal strength to background noise level. "including signal-to-noise ratio (SNR)"
- Sortformer: A transformer-based architecture tailored for efficient sorting/assignment tasks, used here for diarization. "Sortformer-based diarization model"
- Speaker diarization: The process of segmenting audio and assigning speaker labels to identify “who spoke when.” "conventional speaker diarization"
- Speaker embeddings: Vector representations capturing speaker identity used for clustering, verification, or similarity. "extract speaker embeddings with WavLM-large"
- Speaker timbre: The distinctive spectral quality of a speaker’s voice that conveys identity. "stable speaker timbre"
- UTMOS: An automatic metric predicting Mean Opinion Score for perceived speech quality. "maintaining competitive UTMOS scores"
- Vector Quantization (VQ): A method that maps vectors from continuous space to discrete codebook entries. "Vector Quantization (VQ)"
- Vocoder: A model that converts intermediate acoustic features into time-domain waveform audio. "synthesized into waveform audio via a vocoder"
- Voice Activity Detection (VAD): An algorithm that detects speech segments by distinguishing speech from silence/noise. "Voice Activity Detection (VAD)"
- WER (Word Error Rate): A metric for transcription accuracy, computed as the percentage of word-level errors. "Word Error Rate (WER)"
- Zero-shot voice cloning: Generating a new voice from a short prompt without task-specific fine-tuning. "zero-shot voice cloning performance"
Collections
Sign up for free to add this paper to one or more collections.

