Evaluation of Vision-LLMs in Surveillance Video
Abstract: The widespread use of cameras in our society has created an overwhelming amount of video data, far exceeding the capacity for human monitoring. This presents a critical challenge for public safety and security, as the timely detection of anomalous or criminal events is crucial for effective response and prevention. The ability for an embodied agent to recognize unexpected events is fundamentally tied to its capacity for spatial reasoning. This paper investigates the spatial reasoning of vision-LLMs (VLMs) by framing anomalous action recognition as a zero-shot, language-grounded task, addressing the embodied perception challenge of interpreting dynamic 3D scenes from sparse 2D video. Specifically, we investigate whether small, pre-trained vision--LLMs can act as spatially-grounded, zero-shot anomaly detectors by converting video into text descriptions and scoring labels via textual entailment. We evaluate four open models on UCF-Crime and RWF-2000 under prompting and privacy-preserving conditions. Few-shot exemplars can improve accuracy for some models, but may increase false positives, and privacy filters -- especially full-body GAN transforms -- introduce inconsistencies that degrade accuracy. These results chart where current vision--LLMs succeed (simple, spatially salient events) and where they falter (noisy spatial cues, identity obfuscation). Looking forward, we outline concrete paths to strengthen spatial grounding without task-specific training: structure-aware prompts, lightweight spatial memory across clips, scene-graph or 3D-pose priors during description, and privacy methods that preserve action-relevant geometry. This positions zero-shot, language-grounded pipelines as adaptable building blocks for embodied, real-world video understanding. Our implementation for evaluating VLMs is publicly available at: https://github.com/pascalbenschopTU/VLLM_AnomalyRecognition



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a big question: Can small AI models that “look” at videos and “talk” about them (called vision–LLMs, or VLMs) spot unusual or criminal events in security camera footage without any extra training? The authors test these AIs on real surveillance datasets and also check how privacy tools (like blurring faces) affect what the AIs can recognize.
What questions did the researchers ask?
- Can current vision–LLMs recognize rare, unusual actions (like fighting or theft) in videos they’ve never been trained on, just by using smart instructions (prompts) and a few examples?
- If we hide people’s identities with privacy filters (face blur or swapping faces/bodies), does the AI still recognize the actions correctly?
How did they do it?
Turning video into words
Instead of training a special model for each crime (which needs lots of labeled data), the team uses a “zero-shot” approach—meaning no extra training. They:
- Feed a short video clip into a vision–LLM.
- Ask the model for a short description of what’s happening (for example: “Two people shove and swing fists near a car.”).
Think of it like having the AI write a quick caption for each video.
Matching words to action labels
Next, they check whether the caption fits one of the target action labels (like “Fighting,” “Robbery,” or “Normal”). They use a language tool (an NLI classifier) that answers: “Does this description support the label?” The label with the strongest match is picked.
Example: If the caption says “Two people throw punches,” it should strongly match “Fighting.”
Prompts and “few-shot” examples
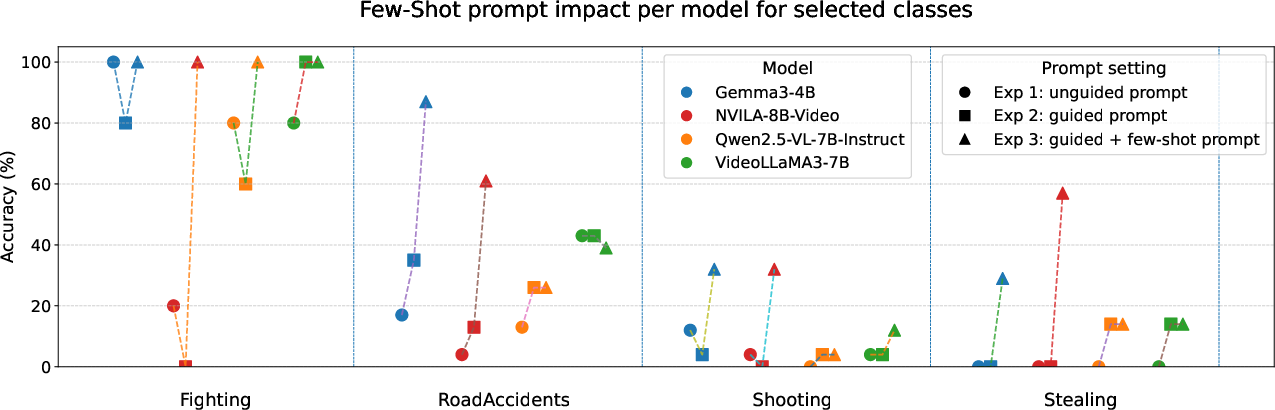
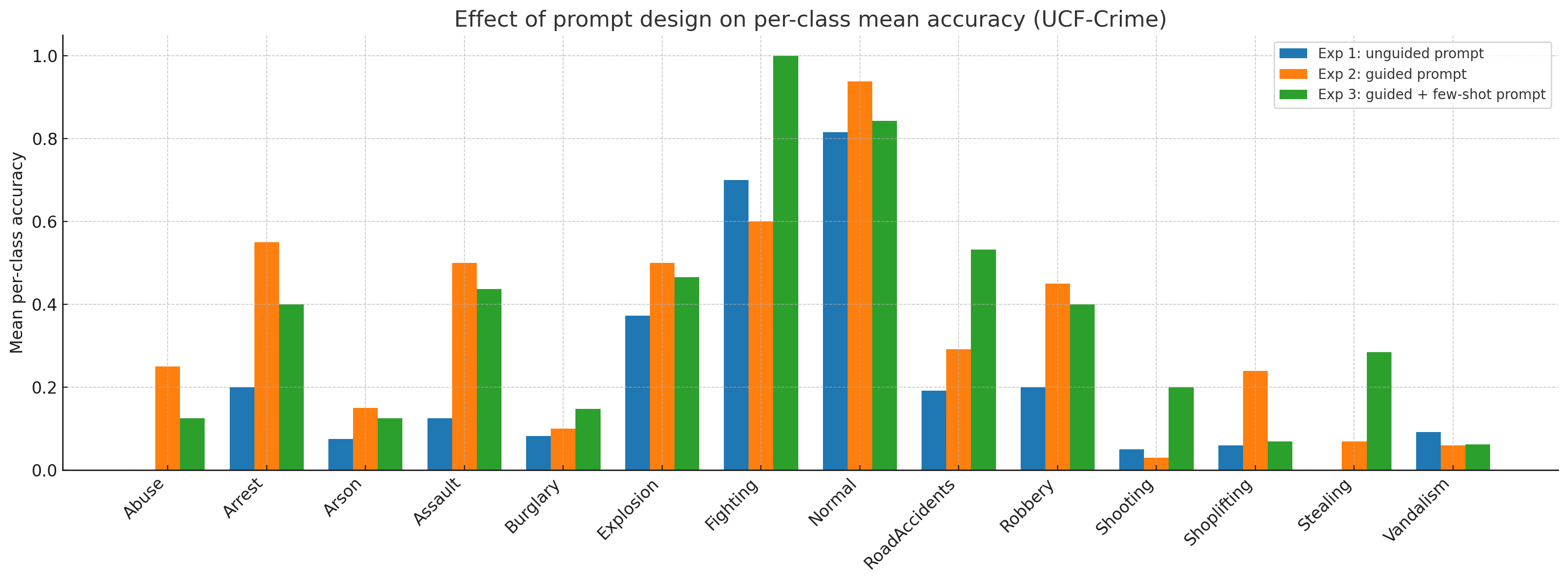
- Prompts are the instructions they give the AI (unguided vs guided). Guided prompts list the possible classes and ask the AI to choose one.
- “Few-shot prompting” means showing the AI a handful of labeled examples first (like a picture and label for “Shooting” or “Stealing”) to set the pattern. This sometimes helps the AI make better choices.
Privacy filters
Because surveillance often needs to protect people’s identities, they tested three privacy methods:
- Blur faces.
- Replace faces with AI-generated faces (a “GAN,” which is a kind of image-generation tool).
- Replace the full body with an AI-generated version.
These methods hide identity, but they can also change visual details the AI uses to understand actions—especially if the replacements flicker or look inconsistent across frames.
What they tested on
- Datasets: UCF-Crime (13 types of unusual activities plus “Normal”) and RWF-2000 (videos labeled “Fighting” or “Normal”).
- Models: Four small, open-source vision–LLMs (4–8 billion parameters).
- Metrics: Mainly Top-1 accuracy (how often the top guess is correct) and false positives (how often the model raises an alarm on normal videos).
What did they find?
- Few-shot examples can help—but can also backfire:
- Showing a few labeled examples before testing sometimes boosted accuracy for certain models (especially Gemma-3 and NVILA).
- However, it also often increased false alarms, meaning the AI was more likely to call a normal video “suspicious.”
- Privacy filters reduce accuracy:
- Blurred or AI-replaced faces caused small to moderate drops in accuracy.
- Full-body AI replacement (GAN full-body) hurt the most, likely because it made people look inconsistent from frame to frame, which confuses motion and action cues.
- In many cases, false alarms went up when privacy filters were used.
- Works better for obvious actions:
- The models were more reliable on easy-to-spot events with clear movement and space cues (like fighting).
- They struggled when the scene was noisy, the cues were subtle, or when identity-hiding changed the look or motion too much.
- Models aren’t all the same:
- Different models reacted differently to prompts and privacy filters. For example, one model showed fewer false alarms with certain GAN filters, while others got worse.
Why this matters: In real life, too many false alarms waste operators’ time, and any privacy protection should not break the system’s ability to spot danger.
Why this research matters and what could come next
This study shows that small, off-the-shelf vision–LLMs can be a helpful starting point for understanding surveillance video without extra training. That’s useful when you have tons of cameras and limited labeled data. But there are trade-offs:
- Few-shot prompting can raise accuracy but also raise false alarms.
- Stronger privacy protections (especially full-body replacements) currently make recognition harder.
The authors suggest practical ways to improve without retraining:
- Better, structure-aware prompts that guide the AI to focus on who is where and doing what.
- A simple memory across video clips so the AI tracks actions over time, not just frame by frame.
- Using extra hints like scene graphs or 3D body poses to keep the action’s geometry clear.
- Privacy tools that hide identity but keep the motion and body layout consistent.
In short, this approach is promising for straightforward cases and could help human operators keep up with massive video streams. With smarter prompts, light-weight memory, and improved privacy methods that keep action cues intact, these zero-shot, language-grounded systems could become more reliable building blocks for real-world, privacy-aware video understanding. The team also shared their evaluation code, which helps others test and improve these ideas.
Collections
Sign up for free to add this paper to one or more collections.