- The paper presents a novel framework that reframes stepwise reward modeling as a reasoning task, using generative judges to provide explicit chain-of-thought analyses before final judgments.
- It employs self-segmentation, Monte-Carlo Q-value estimation, and online RL training to achieve state-of-the-art performance on ProcessBench.
- Practical applications include inference-time search for self-correction and stepwise data selection for fine-tuning, outperforming traditional discriminative methods.
StepWiser: Stepwise Generative Judges for Wiser Reasoning
Introduction and Motivation
The paper introduces StepWiser, a framework for stepwise generative reward modeling in multi-step reasoning tasks, particularly mathematical problem solving with LLMs. The motivation is to address two major limitations of existing Process Reward Models (PRMs): (1) their black-box, classifier-based nature, which lacks interpretability and fails to provide explicit rationales for judgments; and (2) their reliance on supervised fine-tuning (SFT) with static datasets, which restricts generalization to novel reasoning patterns. StepWiser reframes stepwise reward modeling as a reasoning task, training a generative judge to reason about the policy model's intermediate steps and output explicit chain-of-thought (CoT) analyses before delivering verdicts. The judge is trained via reinforcement learning (RL) using dense, stepwise signals derived from Monte-Carlo rollouts.
Methodology: Stepwise Generative Judge Training
StepWiser consists of three core components:
- Self-Segmentation of Reasoning Trajectories: The policy model is fine-tuned to segment its CoT into coherent, logically complete chunks (chunks-of-thought), using SFT data generated by LLMs prompted with explicit segmentation rules. This produces more informative steps and reduces the number of segments per trajectory, improving both annotation efficiency and evaluation accuracy.
- Stepwise Data Annotation via Monte-Carlo Q-Value Estimation: For each chunk, Monte-Carlo rollouts are used to estimate the expected final reward (Q-value) starting from that point. Binary labels are assigned to each chunk using absolute or relative Q-value thresholds, including Abs-Q (absolute threshold), Rel-Ratio (relative improvement), and Rel-Effective (advantage-based reward). Relative signals are shown to be more effective for learning.
- Online RL Training of the Generative Judge: The judge model is trained to generate CoT analyses and final judgments for each chunk, using GRPO as the RL optimizer. The reward is 1 if the judgment matches the Monte-Carlo label, 0 otherwise. Prompt dataset balancing is employed to mitigate class imbalance and stabilize training.
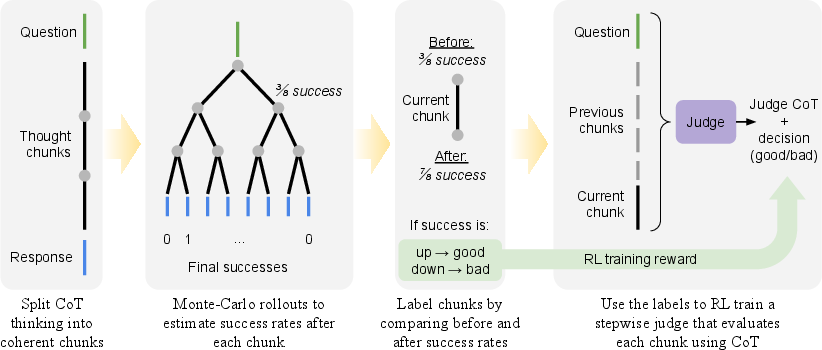
Figure 1: Overview of the StepWiser training method, including self-segmentation, Monte-Carlo Q-value rollouts, and RL training of the generative judge.
Experimental Results and Ablations
StepWiser is evaluated on ProcessBench, a benchmark for stepwise error detection in mathematical reasoning. The RL-trained generative judge consistently outperforms SFT-trained discriminative judges and trajectory-level RL baselines across all metrics and model scales. For example, with Qwen2.5-7B-chunk and Rel-Effective labeling, StepWiser achieves an average ProcessBench score of 61.9, compared to 39.7 for the discriminative baseline and 43.9 for trajectory-level RL models. Majority voting at inference time yields modest further improvements.
Ablation studies demonstrate that both the generative CoT reasoning and online RL training are critical for optimal performance. Removing either component results in substantial drops in accuracy and F1 scores. Prompt dataset balancing is also essential to prevent model collapse due to class bias.
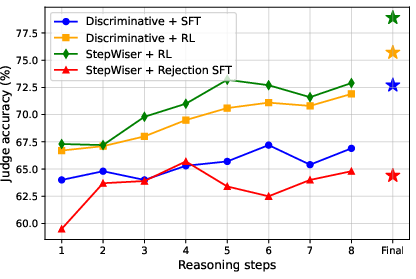
Figure 2: Ablation results showing the impact of generative CoT reasoning and RL training on stepwise judge accuracy.
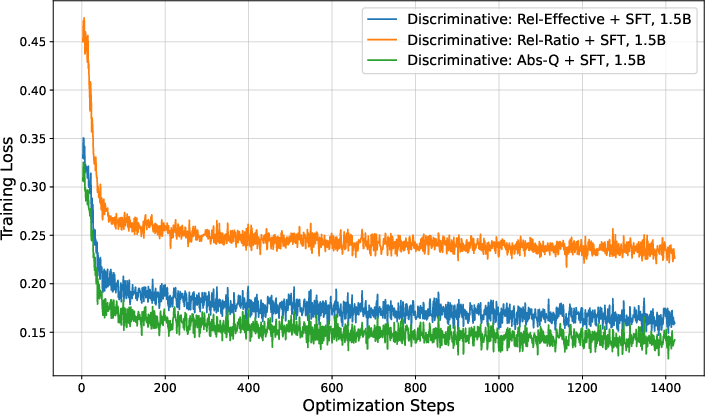
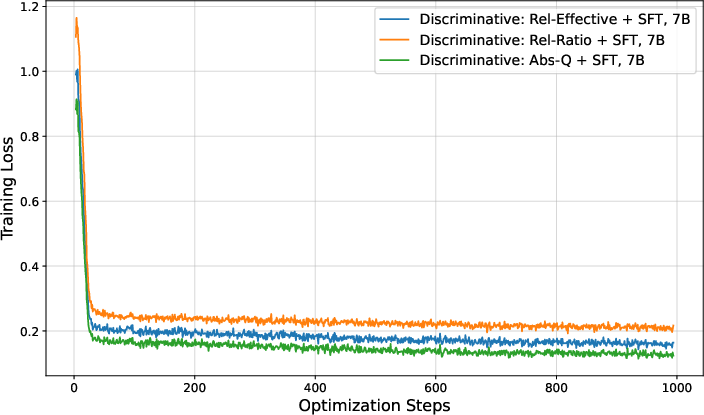
Figure 3: Training loss curves for discriminative stepwise judges under different learning signals, illustrating rapid saturation and limited expressivity.
Practical Applications: Inference-Time Search and Data Selection
StepWiser is applied to two practical tasks:
- Inference-Time Search via Chunk-Reset Reasoning: The policy model generates solutions chunk-by-chunk, with the StepWiser judge evaluating each chunk. Flawed chunks are rejected and regenerated, enabling self-correction and improved solution quality. This approach scales sequential compute without increasing generation length.
- Training Data Selection via Stepwise Rejection Sampling: StepWiser is used to select high-quality reasoning trajectories for fine-tuning, outperforming outcome-based and discriminative selection methods. Models fine-tuned on StepWiser-selected data achieve the highest test accuracy.
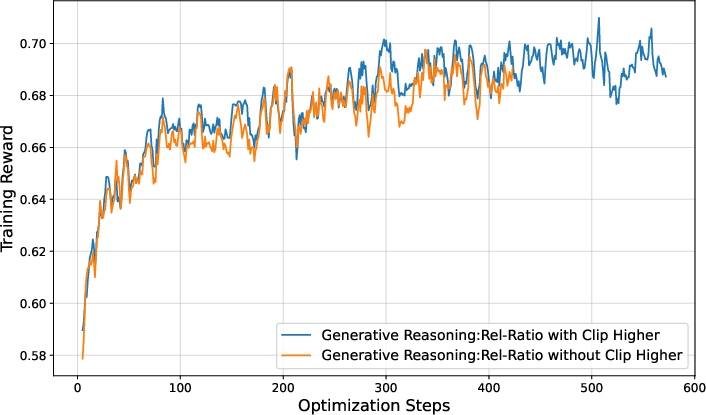
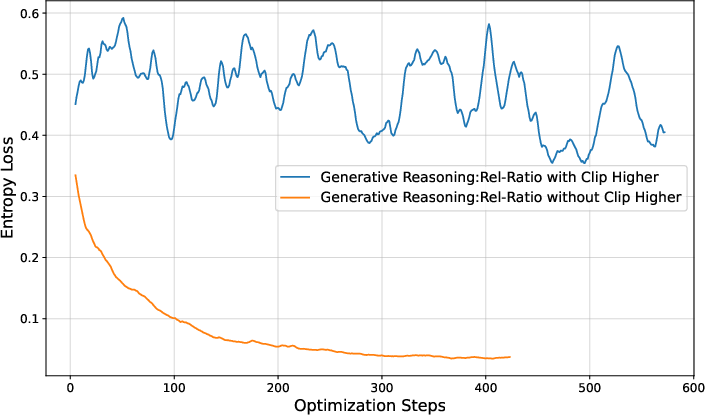
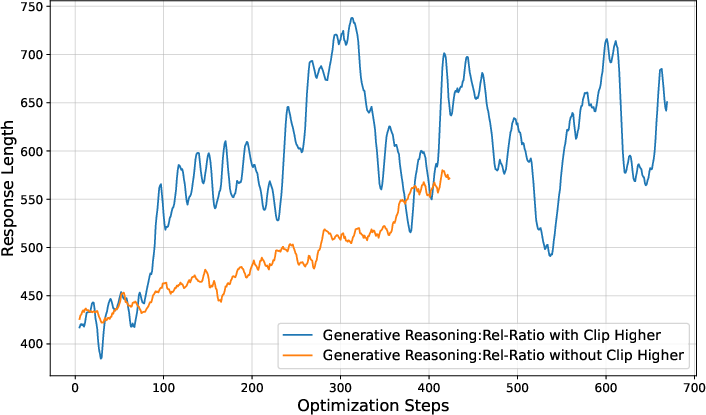
Figure 4: Training reward, entropy loss, and response length with and without the clip higher technique, demonstrating improved exploration and stability.
Analysis of Labeling Strategies and Scaling
Relative progress-based signals (Rel-Ratio, Rel-Effective) consistently yield better judges than absolute Q-value thresholds. Self-segmentation fine-tuning reduces the number of reasoning steps per trajectory, improving annotation efficiency and RL training quality. The framework is robust across model scales and generalizes to diverse mathematical benchmarks.
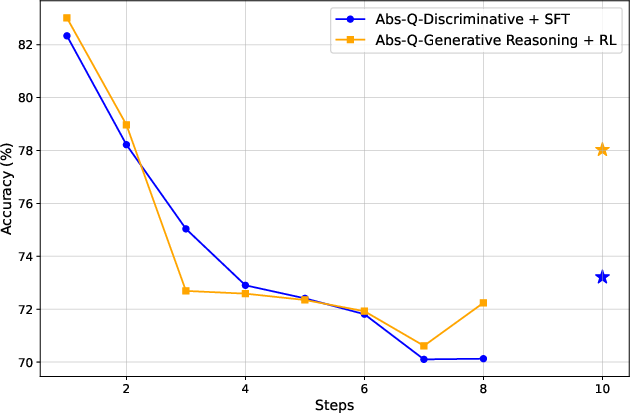
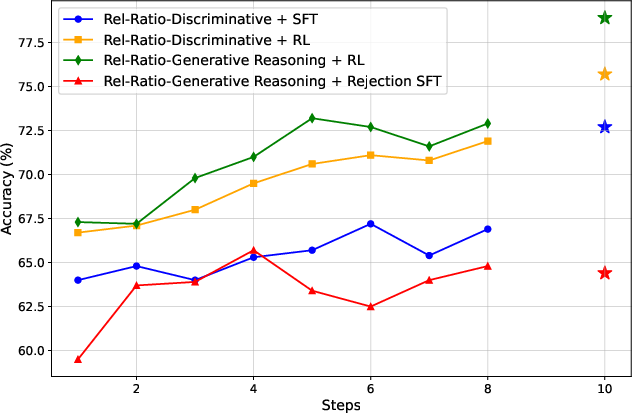
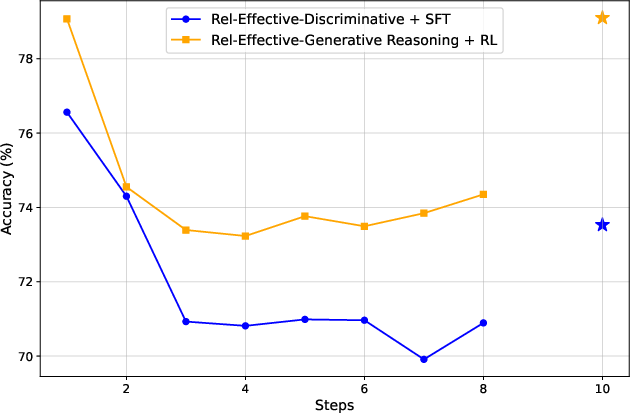
Figure 5: Test stepwise accuracy of different judges for Abs-Q, Rel-Ratio, and Rel-Effective signals, with final answer recognition accuracy highlighted.
Theoretical and Practical Implications
StepWiser demonstrates that explicit reasoning about reasoning, combined with dense, stepwise RL signals, leads to superior reward modeling for multi-step tasks. The generative judge architecture provides interpretability and transparency, addressing the limitations of black-box classifiers. The approach is compatible with standard RL pipelines and can be integrated with advanced engineering strategies (ensembles, human verification) for further improvements.
The results suggest that future developments in AI reasoning should focus on meta-reasoning architectures, dense process supervision, and scalable RL training. The framework is extensible to other domains requiring stepwise validation, such as code synthesis, scientific discovery, and tool-augmented agents.
Conclusion
StepWiser establishes a new paradigm for process reward modeling by training generative judges to reason about intermediate steps via RL. The combination of self-segmentation, Monte-Carlo Q-value annotation, and online RL yields state-of-the-art performance in stepwise error detection and practical downstream tasks. The findings highlight the importance of explicit meta-reasoning and dense supervision for advancing the reliability and generalization of LLM-based reasoning systems.

