- The paper introduces ToRL, a novel framework that leverages reinforcement learning to optimally integrate computational tools with large language models.
- It employs a Tool Integrated Reasoning (TIR) rollout that iteratively generates and executes code, enhancing adaptive problem-solving and reasoning accuracy.
- Experiments on Olympic-level benchmarks demonstrate significant gains in accuracy, highlighting ToRL's potential to surpass traditional SFT methods.
Introduction
The paper presents ToRL (Tool-Integrated Reinforcement Learning), an innovative framework aimed at enhancing the reasoning capabilities of LLMs through the integration of computational tools. By shifting away from traditional Supervised Fine-Tuning (SFT) approaches, ToRL leverages reinforcement learning (RL) to discover optimal strategies for utilizing external tools during problem-solving. Experiments using the Qwen2.5-Math base models show significant accuracy improvements, indicating ToRL's potential in advancing reasoning tasks by autonomously exploiting computational tools.
The study highlights that, unlike SFT-based models, ToRL empowers models to adaptively integrate tool usage with open-ended exploration. This is achieved by scaling RL directly from base models, fostering emergent behaviors such as strategic tool invocation and adaptive reasoning without explicit instruction.
Methodology
ToRL enhances the RL framework by incorporating Tool Integrated Reasoning (TIR), which allows models to iteratively generate reasoning paths informed by computational feedback from external code execution. This section details how ToRL diverges from traditional RL by embedding a code interpreter within the RL environment. This setup supports reasoning paths that include both natural language and computational code, allowing the model to adjust its responses dynamically based on execution feedback.
TIR Rollout Framework
In the TIR rollout framework, when a LLM generates code, it interacts with a code interpreter to execute the code and append the results to its reasoning trajectory. This iterative process continues until a final response is formulated, facilitating an interactive problem-solving approach that blends analytical reasoning with computational verification.
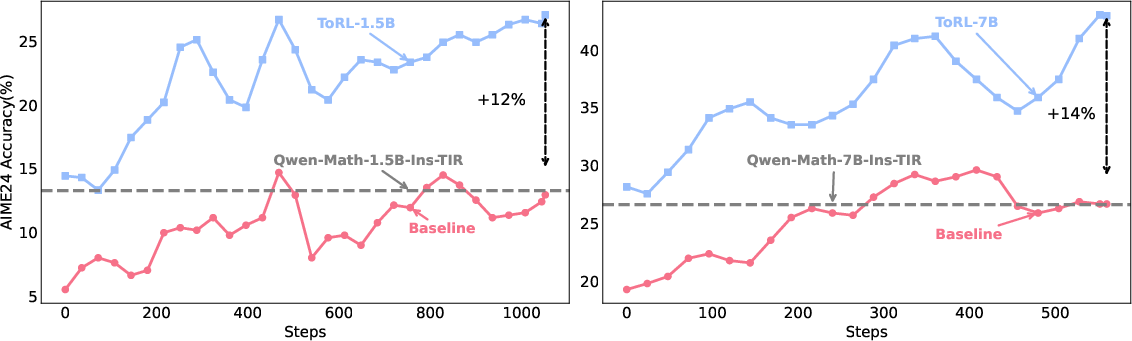
Figure 1: Top Figure: Performance comparison of ToRL versus baseline models. Both plots show AIME24 Accuracy (\%) against training steps across 1.5B and 7B models.
Experimental Setup
Experiments conducted on Olympic-level mathematical benchmarks demonstrate ToRL's performance improvements across various scales and versions of Qwen2.5-Math models. By circumventing the limitations of SFT, ToRL-7B achieves significant advances in accuracy, particularly on complex reasoning benchmarks such as AIME24 and OlympiadBench.
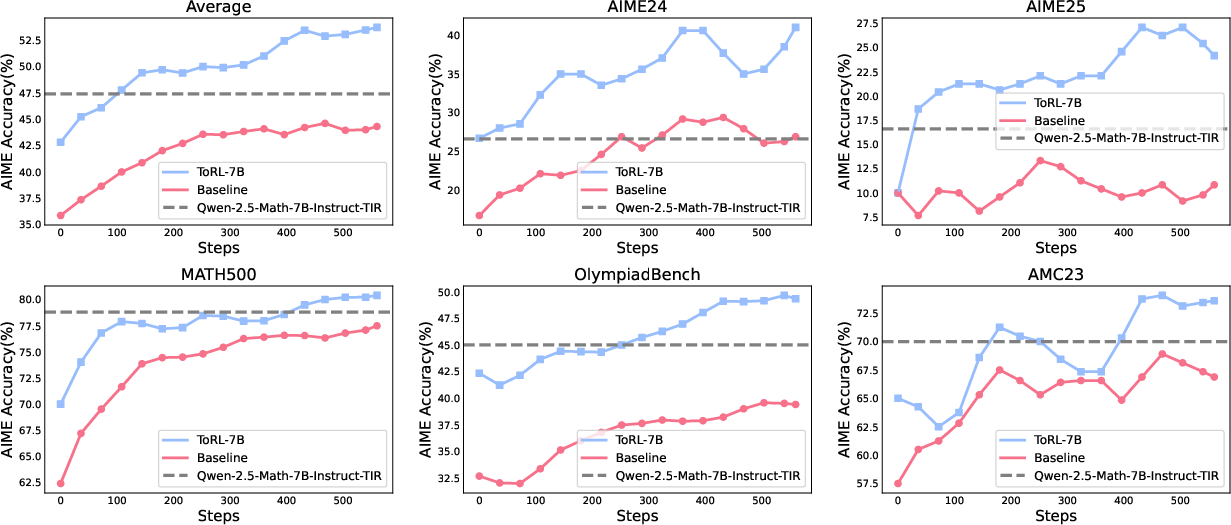
Figure 2: Performance comparison across mathematical benchmarks. The plots show accuracy (\%) against training steps for the 7B model evaluated on different benchmarks.
The experimentation involved varying the frequency of tool calls (C), assessing both the impact of tool call limits on training efficiency and the role of execution feedback in refining computational reasoning. Results suggested a notable performance enhancement at the expense of training speed when increasing C, underscoring critical trade-offs in RL design choices.
Analysis
Throughout the training, the model exhibited an increased propensity for generating syntactically correct and effectively executable code over time. This self-regulation suggests that models can autonomously refine their computational strategies without explicit feedback mechanisms integrated beyond basic RL rewards.
The study reports that the ToRL framework facilitates diverse cognitive behaviors including adaptive reasoning, self-regulatory adjustments, and verification of reasoning through executable code, positioning ToRL as a promising approach for integrating LLMs with computational tools for complex problem-solving.
Conclusion
ToRL proposes a robust alternative to SFT by enabling tool integration through RL from base models, allowing models to self-discern optimal tool usage strategies. The emergent cognitive behaviors and substantial performance improvements outlined in the study indicate promising directions for future research in tool-augmented LLMs, pushing the boundaries of autonomous problem-solving capabilities within LLMs. Open-source implementations pave the way for broader adoption and further exploration into scaling tool-integrated RL methodologies.