- The paper presents an evaluation of LLMs' legal citation automation performance through rigorous zero-shot and in-context testing.
- It introduces a novel dataset of 866 Bluebook formatting tasks to assess citation generation accuracy and procedural adherence.
- Results show that even advanced models achieve only 69%-77% accuracy, highlighting limitations in handling complex legal rules.
Automating Legal Procedure with LLMs
Introduction
The paper "Bye-bye, Bluebook? Automating Legal Procedure with LLMs" (2505.02763) investigates the feasibility of automating legal citation compliance using LLMs, focusing specifically on the complex rules of The Bluebook. This citation system represents a significant procedural challenge in the legal profession, burdening law students and practitioners with intricate formatting rules crucial for legal documentation. The study evaluates the proficiency of leading LLMs from OpenAI, Anthropic, Google, Meta, and DeepSeek in generating Bluebook-compliant citations, both in zero-shot and in-context learning scenarios, highlighting potential limitations and areas for improvement.
Dataset and Methodology
The research constructs a novel dataset of 866 Bluebook formatting tasks, divided into case law, enacted law, and miscellaneous citation challenges. The case law tasks include caption masking to evaluate LLMs' ability to correctly format citations, whereas enacted law tasks employ open prompts for complete citation generation. This approach allows for detailed assessment of the models' procedural accuracy beyond mere information retrieval.
Evaluations are conducted across five flagship LLMs, assessing zero-shot capabilities and exploring the impact of in-context learning with Bluebook rules for Google's Gemini 2.5 Flash, recognized for its long-context reasoning prowess. Strict adherence to citation format is measured, focusing on semantic and stylistic precision.
Results and Discussion
Zero-shot evaluations demonstrate marginally acceptable performance, with accuracy ranging from 69% to 74% among the models. Notably, the strongest results are observed in case law reporter formatting and parenthetical indicators, underscoring models' strengths in predictable citation structures.

Figure 1: Structure of a Bluebook-compliant citation to case law.
However, performance falters in more personalized tasks like party name abbreviation and subsequent history inclusion, revealing gaps in the models' contextual understanding and rule application capabilities.
In-Context Learning
Despite expectations for improved performance through exposure to procedural rules, in-context learning raises accuracy to only 77%, indicating the complexity of the Bluebook cannot be easily navigated by even advanced models like Gemini 2.5 Flash.
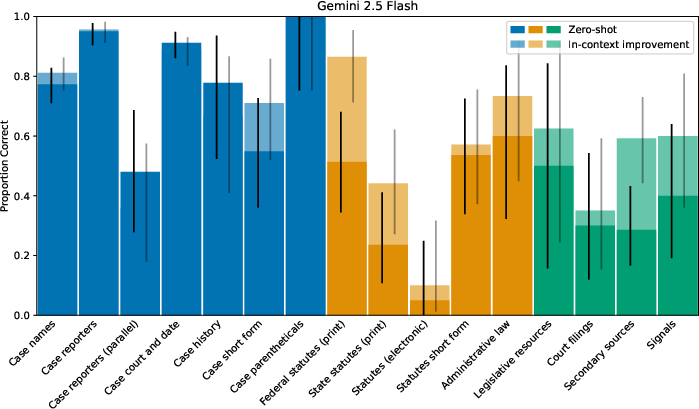
Figure 2: In-context Gemini 2.5 Flash results.
These findings suggest limitations in LLMs' ability to internalize and apply extended procedural rules, with practical implications for their current use in high-stakes legal environments.
Procedural Implications
The paper identifies key procedural characteristics of citation rules such as universality, intricacy, and inflexibility, explaining the challenges LLMs face in adapting to these rigors. As such, the data indicates that full automation of legal procedural tasks using LLMs remains distant, necessitating further refinement of training protocols or model architectures to handle procedural nuances effectively.
Limitations and Future Work
Several limitations constrain the study's scope, including the reliance on the Indigo Book for in-context learning evaluations, potential variability in model updates, and the narrow focus on the Bluepages style. These factors necessitate cautious interpretation of results, highlighting the need for ongoing research into enhanced fine-tuning or new LLM methodologies better suited for complex rule-following applications.
Future research should prioritize expanding procedural evaluation to encompass broader legal systems and document types, exploring few-shot prompting and specialized models tailored to legal compliance standards.
Conclusion
This study provides critical insights into the limitations of LLMs in faithfully conforming to complex procedural requirements of legal practice. While LLMs exhibit potential, achieving reliable automation of legal citation compliance and procedural rule adherence necessitates considerable advancements in model capabilities and learning strategies. As the legal profession continues to explore AI integration, nuanced understanding and application of procedural rules remain essential, underscoring the importance of rigorous empirical research in guiding technological interventions.

