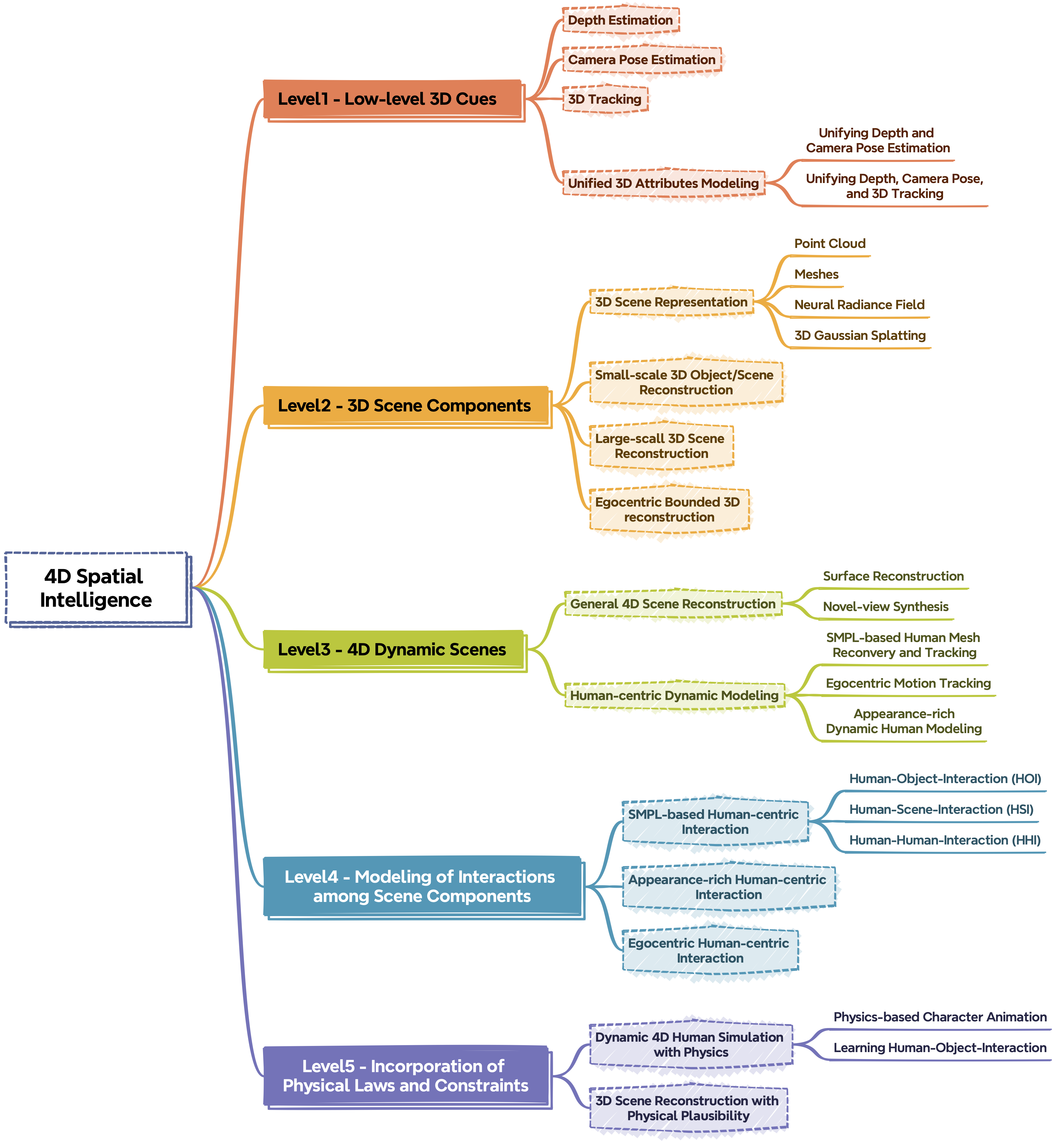
- The paper introduces a five-level hierarchical taxonomy for 4D spatial intelligence, mapping the progression from low-level 3D cues to physics-based reasoning.
- It reviews innovative methods including transformer-based and diffusion-driven architectures alongside unified frameworks for accurate dynamic scene reconstruction.
- The survey highlights challenges such as scalability, physical plausibility, and the integration of perception with control, setting the stage for future research.
Reconstructing 4D Spatial Intelligence: A Hierarchical Survey
This essay provides a comprehensive technical summary and analysis of "Reconstructing 4D Spatial Intelligence: A Survey" (2507.21045), which systematically categorizes the field of 4D scene reconstruction from video into five progressive levels. The survey offers a hierarchical taxonomy, spanning from low-level geometric cues to physically grounded dynamic scene understanding, and critically examines the state-of-the-art, open challenges, and future research directions.
Hierarchical Taxonomy of 4D Spatial Intelligence
The survey introduces a five-level hierarchy for 4D spatial intelligence, each representing an increasing degree of scene understanding and modeling complexity:
This taxonomy enables a structured analysis of the field, clarifying the dependencies and progression from geometric perception to high-level, physically plausible world modeling.
Level 1: Low-Level 3D Cues
Level 1 encompasses the estimation of depth, camera pose, and 3D tracking from video, forming the geometric foundation for all higher-level tasks. The field has evolved from optimization-heavy, modular pipelines (SfM, MVS, BA) to integrated, transformer-based, and diffusion-driven architectures.
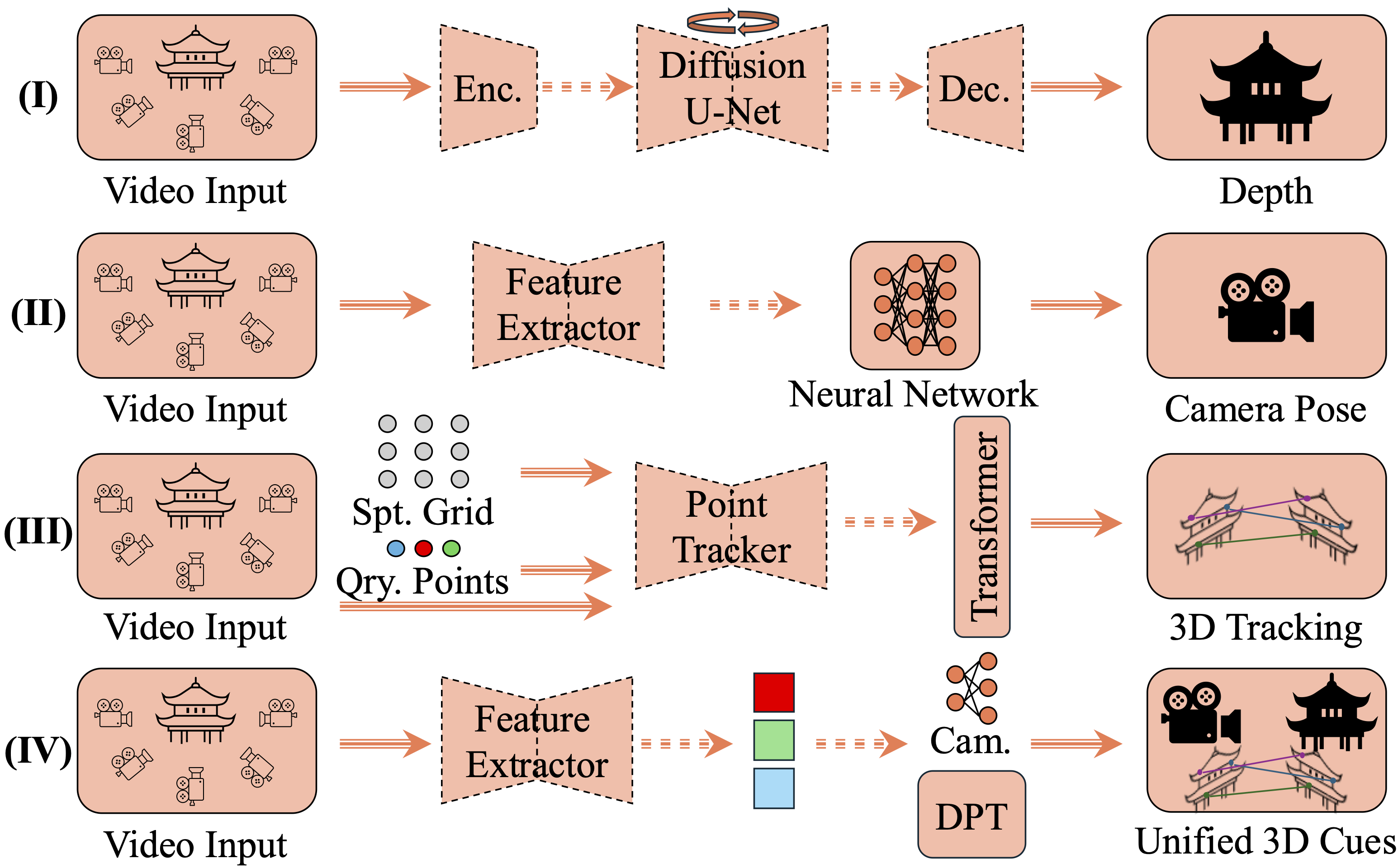
Figure 2: Paradigms for reconstructing low-level cues from video, including diffusion-based depth, neural pose estimation, and transformer-based unified models.
Key advances:
- Depth Estimation: Transition from self-supervised warping and cost-volume methods to large-scale pretrained video diffusion models (e.g., DepthCrafter, ChronoDepth, DepthAnyVideo), achieving strong temporal consistency and generalization.
- Camera Pose Estimation: Hybridization of geometric and learning-based VO/VSLAM, with recent reinforcement learning approaches for adaptive decision-making and reduced manual tuning.
- 3D Tracking: Shift from per-video optimization (OmniMotion, OmniTrackFast) to scalable, feed-forward architectures (SpatialTracker, SceneTracker, DELTA, TAPIP3D).
- Unified Modeling: Emergence of end-to-end frameworks (DUSt3R, MonST3R, Align3R, VGGT, Spann3R, Pi3) that jointly estimate depth, pose, and tracking, reducing inconsistencies and improving temporal coherence.
Trade-offs: Optimization-based methods offer high accuracy but poor scalability; feed-forward and transformer-based models provide efficiency and generalization but may underperform in highly dynamic or occluded scenes.
Level 2: 3D Scene Components
Level 2 targets the reconstruction of discrete scene elements (objects, humans, buildings) and their spatial arrangement, leveraging advances in 3D representations.
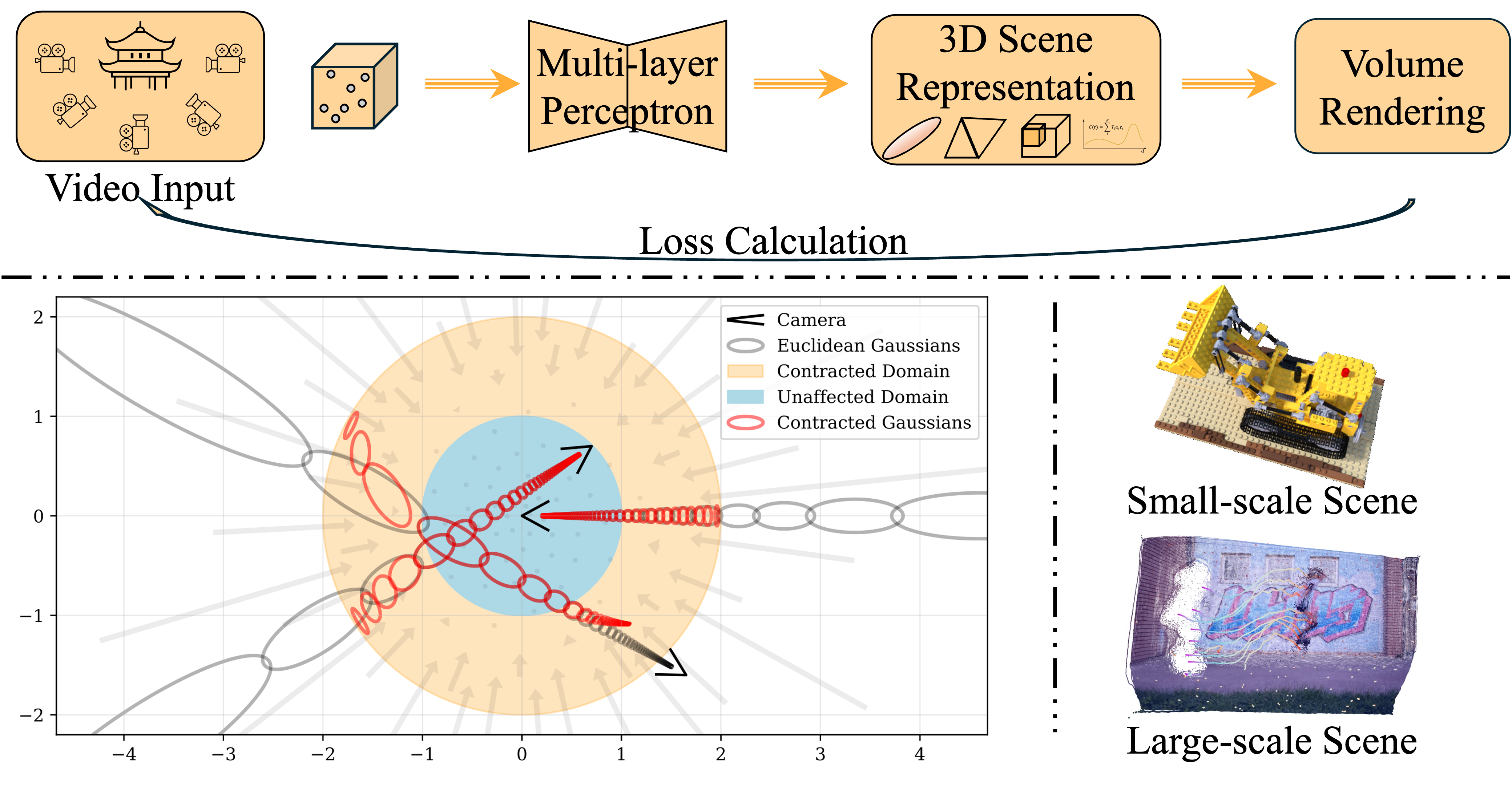
Figure 3: Paradigms for reconstructing 3D scene components, with architectures for small- and large-scale scenes.
Representations:
- Point Clouds/Surfels: Efficient, explicit geometry; limited for photorealistic rendering.
- Meshes: Flexible, efficient, but require differentiable rendering for integration with learning-based pipelines.
- Neural Radiance Fields (NeRF): Implicit, continuous volumetric fields enabling high-fidelity view synthesis; extended with SDFs for sharper surfaces.
- 3D Gaussian Splatting (3DGS): Explicit, primitive-based, supporting real-time rendering and efficient training.
Small-scale Reconstruction: Progression from SfM/MVS + surface fusion to NeRF/3DGS-based implicit surface extraction (NeuS, VolSDF, Neuralangelo, SuGaR, QuickSplat). Feed-forward methods (SparseNeuS, SuRF, LaRa) enable real-time, generalizable reconstruction but are memory-intensive.
Large-scale Reconstruction: Partitioned and hierarchical architectures (Block-NeRF, Mega-NeRF, CityGS, LODGE) enable city-scale modeling. Mixture-of-experts and LoD strategies address scalability and memory constraints. Online, end-to-end systems (NeuralRecon, TransformerFusion, VisFusion) support real-time applications.
Limitations: No single representation is optimal across all scales and tasks; fine-scale geometry recovery in unbounded or textureless regions remains challenging.
Level 3: 4D Dynamic Scenes
Level 3 introduces temporal modeling, enabling the reconstruction of dynamic scenes and motion.
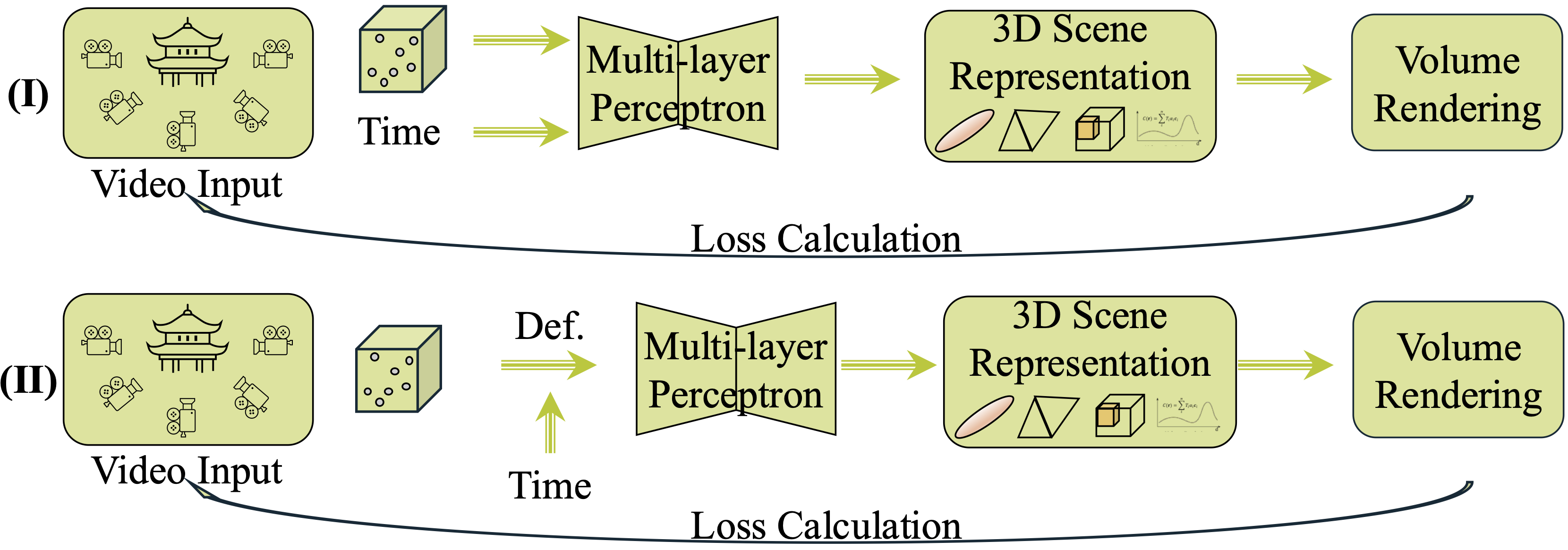
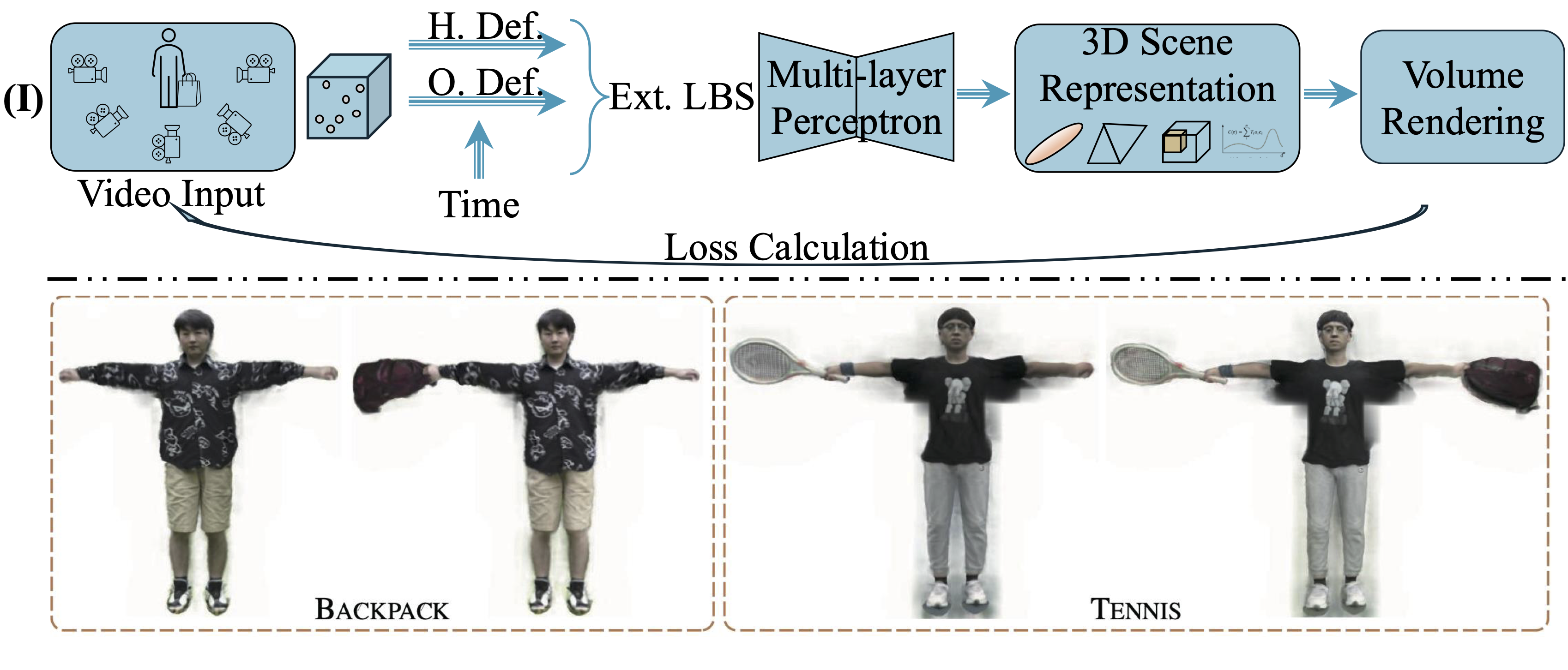
Figure 4: Paradigms for reconstructing dynamic scenes, via explicit time encoding or canonical space deformation.
General 4D Scene Reconstruction:
- Canonical Space + Deformation: NeRFies, HyperNeRF, D-NeRF, and 3DGS-based methods learn deformation fields to model non-rigid motion.
- Explicit Time Encoding: Time as an input to the radiance field (Neural Scene Flow Fields, Dynamic NeRF, 4D Gaussian Splatting), supporting continuous temporal modeling.
- Feed-forward Approaches: MonoNeRF, FlowIBR, and recent transformer-based models enable real-time, generalizable 4D reconstruction.
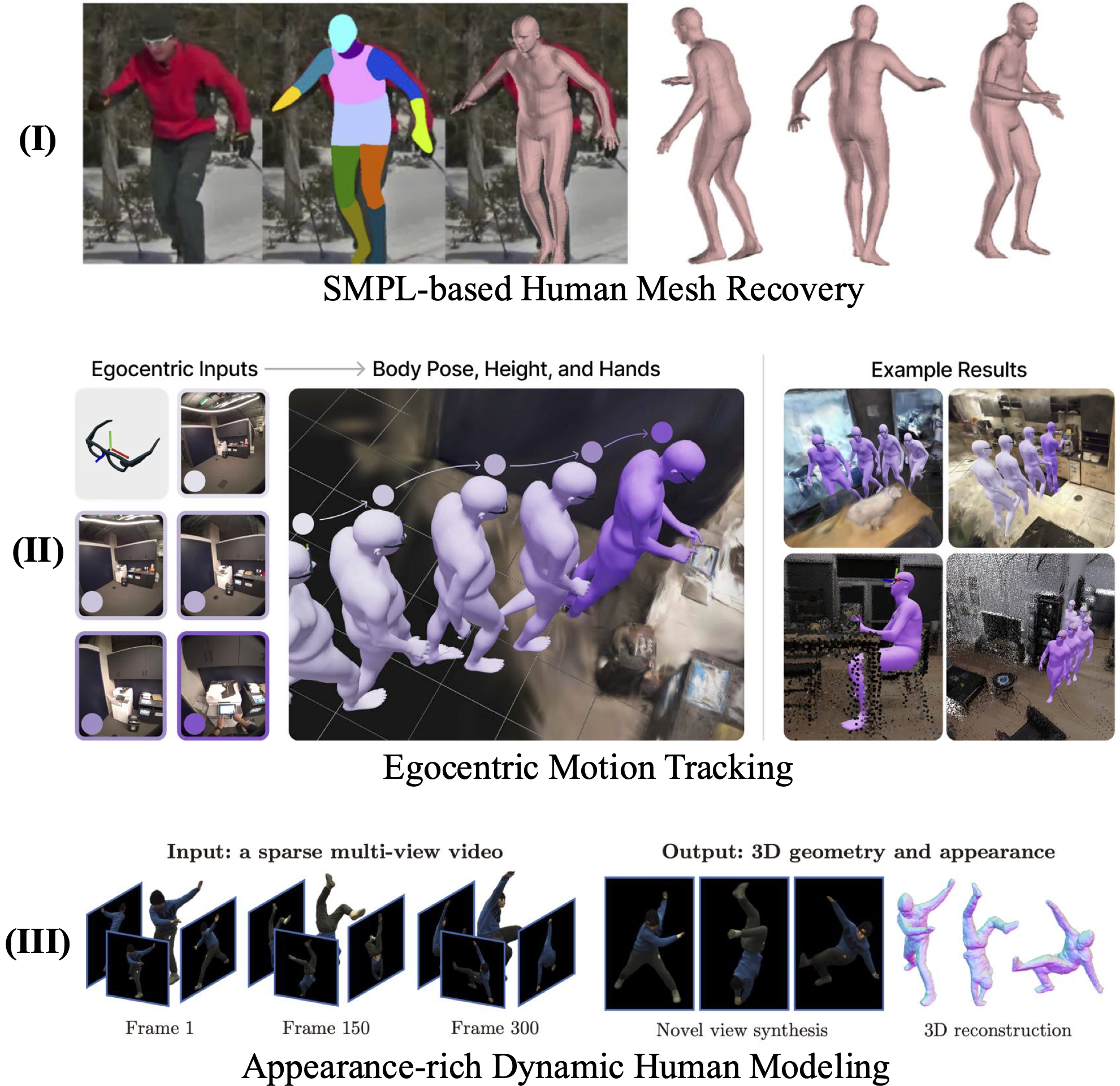
Human-Centric Dynamic Modeling:
Challenges: Trade-offs between speed, generalization, and quality; complex dynamics (fluids, topological changes) and egocentric reconstruction remain unsolved.
Level 4: Interactions Among Scene Components
Level 4 focuses on modeling interactions, particularly human-centric, within reconstructed scenes.

Figure 6: Examples of SMPL-based human-centric interaction modeling.
SMPL-based Interaction:
- Human-Object Interaction (HOI): From optimization with contact priors to generative and diffusion-based models for geometry-agnostic, category-agnostic interaction reconstruction.
- Human-Scene Interaction (HSI): Integration of synthetic and real-world datasets, disentangled representations (SitComs3D, JOSH, ODHSR), and physics-based constraints for context-aware modeling.
- Human-Human Interaction (HHI): Multi-person pose estimation with geometric and physical priors, generative models (diffusion, VQ-VAE), and physics simulators for plausible contact.
Appearance-Rich Interaction:
Egocentric Interaction: Focus on hand-object and full-body interactions from first-person video, leveraging multi-modal data (IMU, gaze) and large-scale benchmarks (Ego-Exo4D, Nymeria).
Limitations: Generalization to diverse object categories, temporal coherence, and physical plausibility remain open; large-scale, high-quality datasets are lacking.
Level 5: Incorporation of Physical Laws and Constraints
Level 5 integrates physical reasoning, enabling simulation-ready, physically plausible 4D reconstructions.
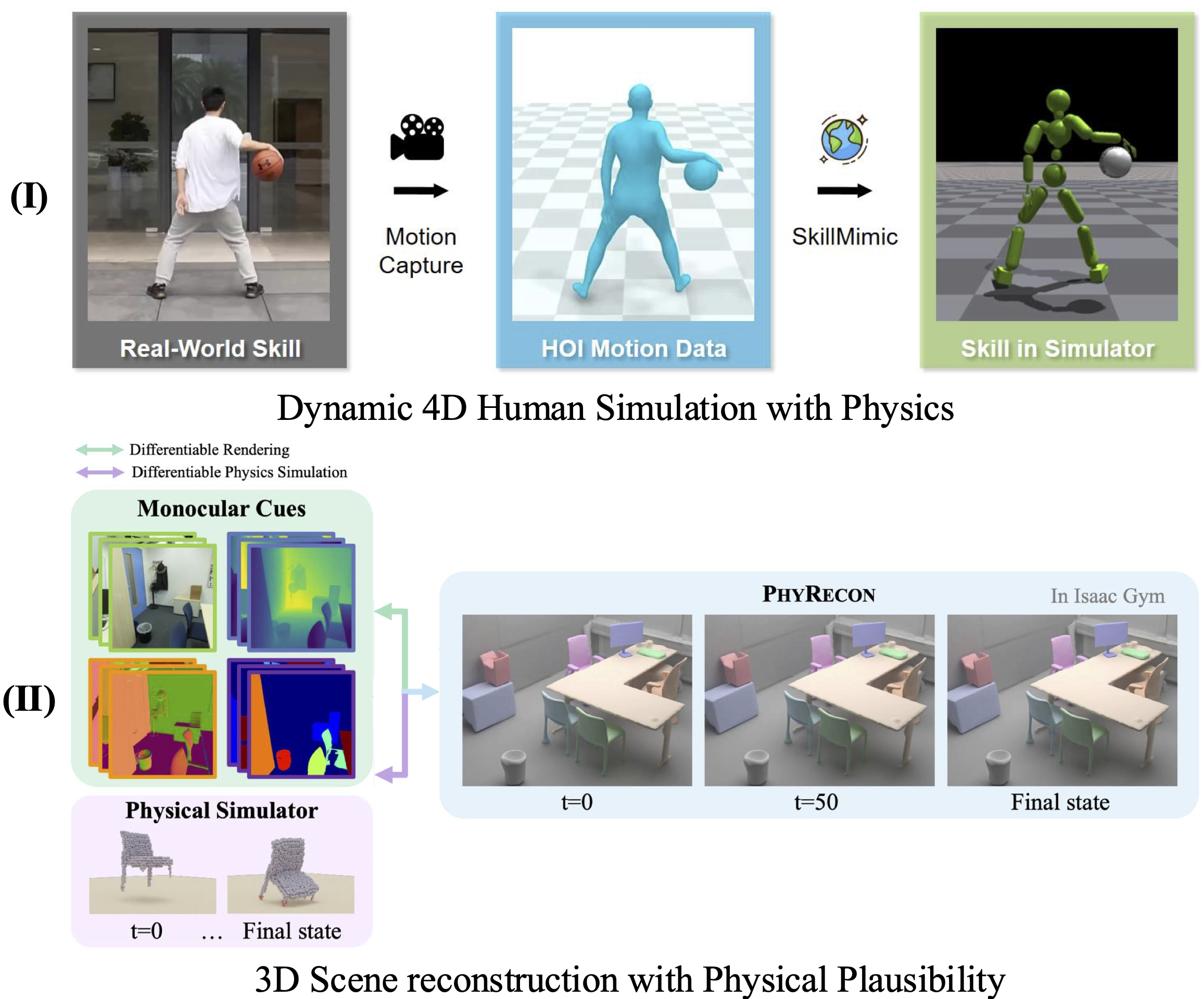
Figure 8: Methods for inferring physically grounded 3D spatial understanding from videos, including human motion policy learning and physically plausible scene reconstruction.
Dynamic Human Simulation:
- Physics-Based Animation: RL and imitation learning (DeepMimic, AMP, ASE, CLoSD) for motion policy learning; hierarchical control for complex behaviors.
- Text-Driven Control: Diffusion and multimodal models for high-level, language-conditioned behavior, though expressiveness lags behind kinematic methods.
- HOI Simulation: Contact-aware rewards and interaction graphs for stable, realistic multi-body coordination.
Physically Plausible Scene Reconstruction:
- PhysicsNeRF, PBR-NeRF, CAST, PhyRecon: Explicit physics guidance (depth-ranking, support, non-penetration), differentiable simulators, and regularization for stable, simulation-ready geometry.
- Specialized Methods: Reflection-aware NeRFs, physically grounded augmentations, and scene-level correction for improved realism.
Challenges: Sample inefficiency, computational cost, and generalization in RL-based animation; enforcing physical plausibility from incomplete or sparse data; integration of perception and control.
Open Challenges and Future Directions
The survey identifies persistent challenges at each level:
- Level 1: Occlusion, dynamic motion, non-Lambertian surfaces, automation, and generalization.
- Level 2: Representation trade-offs, fine-scale geometry in unbounded/textureless regions, egocentric degradation.
- Level 3: Speed-generalization-quality trade-offs, complex dynamics, egocentric occlusion.
- Level 4: Generalization across object categories, temporal coherence, physical plausibility, dataset limitations.
- Level 5: RL sample inefficiency, policy generalization, physical plausibility from sparse data, perception-control integration.
Future research directions:
- Joint world models integrating geometry, motion, semantics, and uncertainty.
- Hierarchical, scalable, and hybrid implicit-explicit representations.
- Physics-informed priors and differentiable physics engines for end-to-end optimization.
- Multimodal learning (video, IMU, audio, text) for robust egocentric and interaction modeling.
- Real-time, interactive simulation and embodied reasoning for AR/VR/robotics.
Conclusion
This survey establishes a rigorous hierarchical framework for 4D spatial intelligence, providing a comprehensive review of methods, representations, and challenges across five levels. The field is rapidly advancing, with strong trends toward unified, scalable, and physically grounded models. However, significant open problems remain in generalization, physical realism, and integration of perception and control. The taxonomy and analysis presented in this work will serve as a foundation for future research, guiding the development of more robust, interactive, and intelligent 4D scene understanding systems.