- The paper formalizes world modeling by defining precise taxonomies and establishing standardized evaluation protocols for 3D and 4D representations.
- It analyzes three modalities—video streams, occupancy grids, and LiDAR point clouds—highlighting their methodologies, performance metrics, and limitations.
- The survey discusses applications in autonomous driving, robotics, and simulation while addressing challenges like long-horizon fidelity and computational efficiency.
Survey of 3D and 4D World Modeling: Taxonomy, Methods, and Evaluation
This essay provides a comprehensive technical summary and analysis of "3D and 4D World Modeling: A Survey" (2509.07996), focusing on the formalization, taxonomy, and benchmarking of world models that operate on native 3D and 4D representations. The survey addresses the fragmentation in the literature by establishing precise definitions, a hierarchical taxonomy, and standardized evaluation protocols for world modeling in autonomous driving, robotics, and simulation.
Motivation and Scope
The survey identifies a critical gap in the field: while generative modeling has advanced rapidly for 2D images and videos, real-world embodied AI systems require models that operate on native 3D and 4D data—such as RGB-D, occupancy grids, and LiDAR point clouds—to capture geometry, dynamics, and semantics in the physical world. The lack of a unified definition and taxonomy for "world models" has led to inconsistent claims and evaluation standards.
The work focuses on three primary modalities:
- Video streams (VideoGen): Multi-view or egocentric video sequences with geometric and temporal consistency.
- Occupancy grids (OccGen): Voxelized 3D/4D representations encoding spatial occupancy and semantics.
- LiDAR point clouds (LiDARGen): Raw or sequential point clouds capturing geometry and motion.
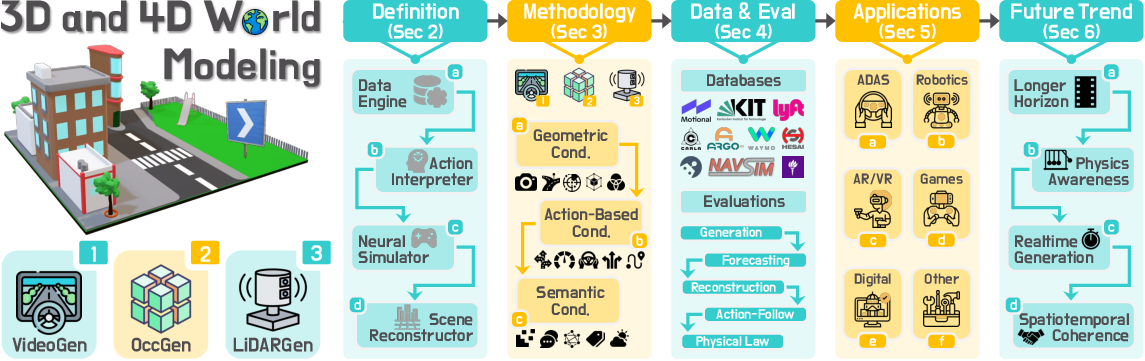
Figure 1: Outline of the survey, focusing on native 3D and 4D representations: video streams, occupancy grids, and LiDAR point clouds, guided by geometric, action-based, and semantic conditions.
The survey formalizes world modeling in 3D/4D as the task of generating or forecasting scene representations under geometric (Cgeo), action-based (Cact), and semantic (Csem) conditions. Two principal paradigms are defined:
- Generative world models: Synthesize plausible scenes from scratch or partial observations, conditioned on multimodal signals.
- Predictive world models: Forecast future scene evolution from historical observations and action conditions.
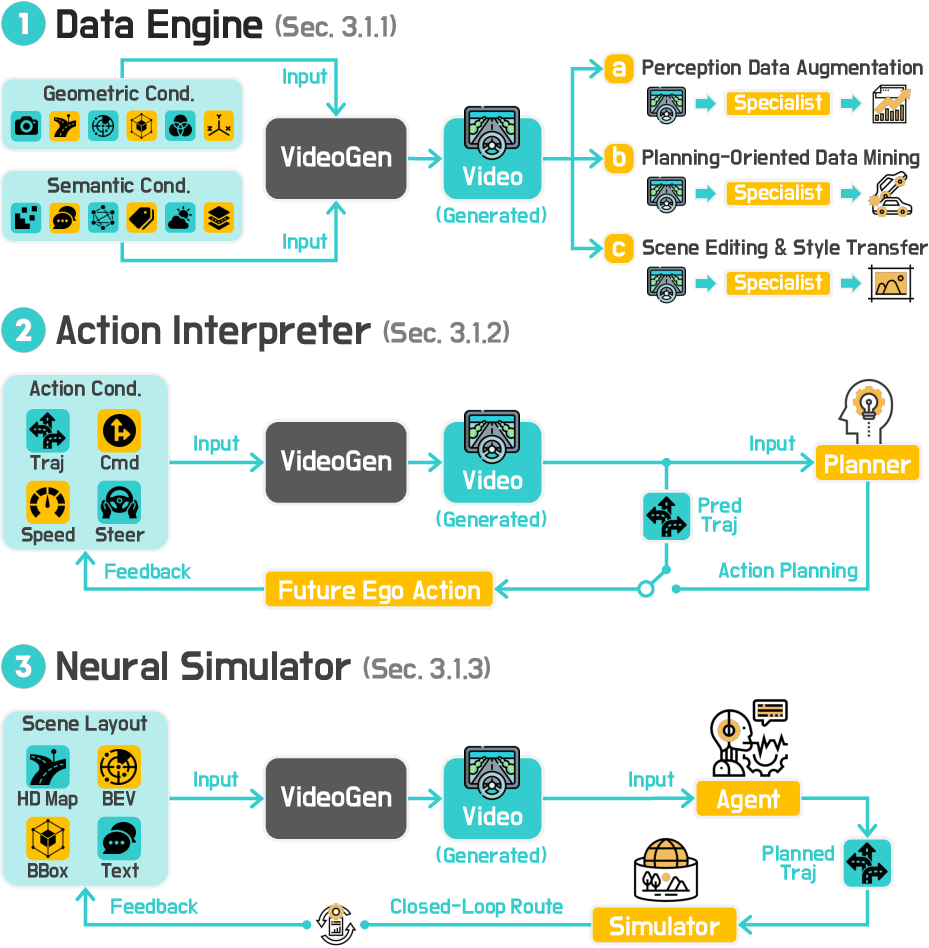
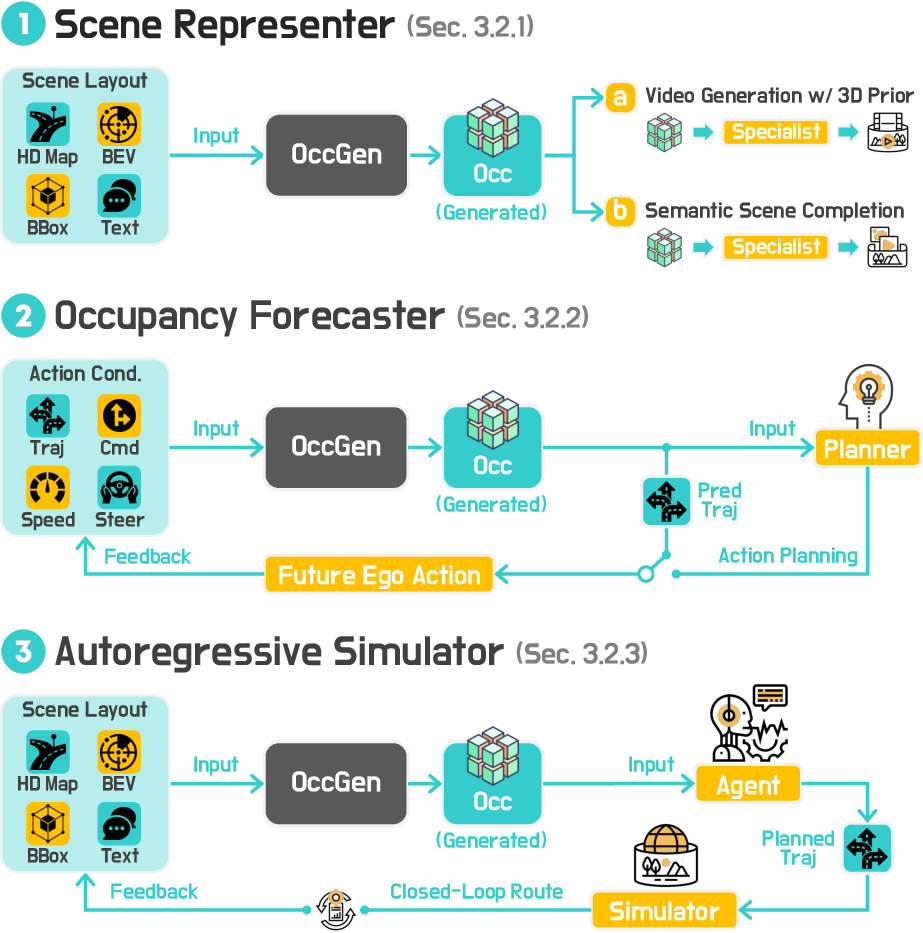
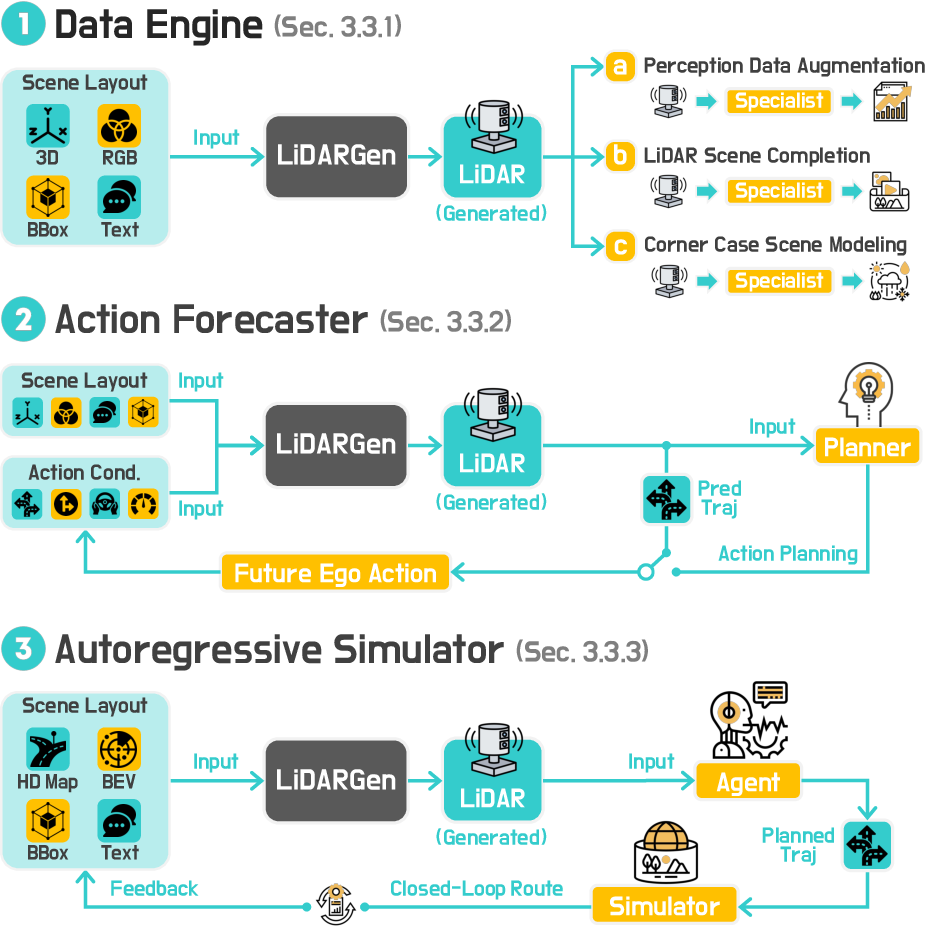
A hierarchical taxonomy is introduced, organizing methods by modality (VideoGen, OccGen, LiDARGen) and by four functional roles:
- Data Engines: Diverse scene synthesis for data augmentation and scenario creation.
- Action Interpreters: Action-conditioned forecasting for planning and behavior prediction.
- Neural Simulators: Closed-loop simulation with policy-in-the-loop for interactive environments.
- Scene Reconstructors: Completion and retargeting from partial 3D/4D observations.
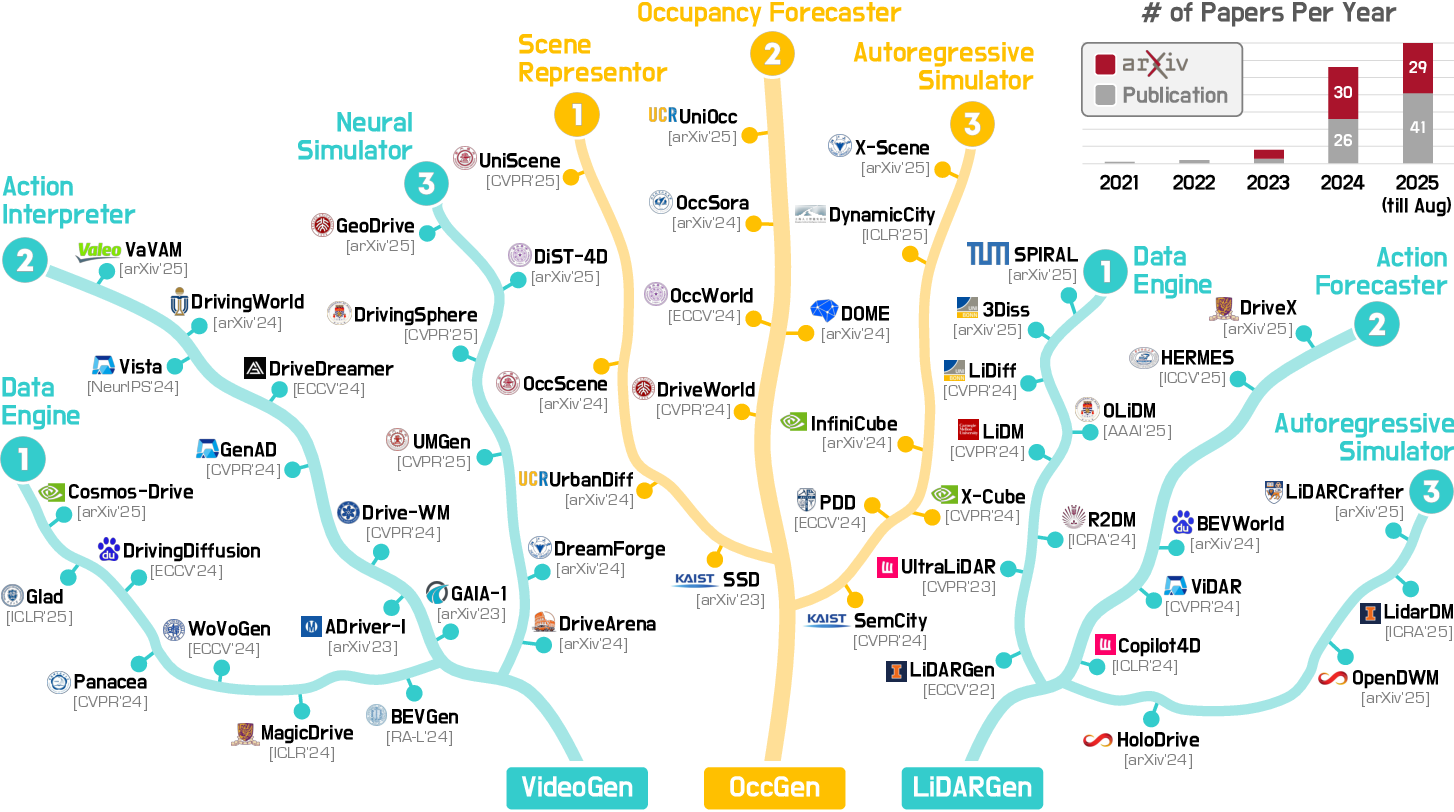
Figure 2: Summary of representative VideoGen, OccGen, and LiDARGen models from the literature.
Methodological Landscape
VideoGen: Video-Based World Modeling
VideoGen models are categorized as data engines, action interpreters, and neural simulators. Recent advances leverage diffusion models, autoregressive transformers, and hybrid architectures for high-fidelity, controllable, and temporally consistent video generation. Notable trends include:
OccGen: Occupancy-Based World Modeling
OccGen models exploit voxelized 3D/4D representations for robust geometry-centric modeling. Key directions include:
LiDARGen: LiDAR-Based World Modeling
LiDARGen models address the challenges of sparse, high-dimensional point cloud data. Advances include:
Datasets and Benchmarking
The survey standardizes the evaluation landscape by cataloging datasets and defining metrics for generation, forecasting, planning, reconstruction, and downstream tasks. Key datasets include nuScenes, Waymo Open, SemanticKITTI, and Occ3D-nuScenes, each providing multimodal annotations and conditions.
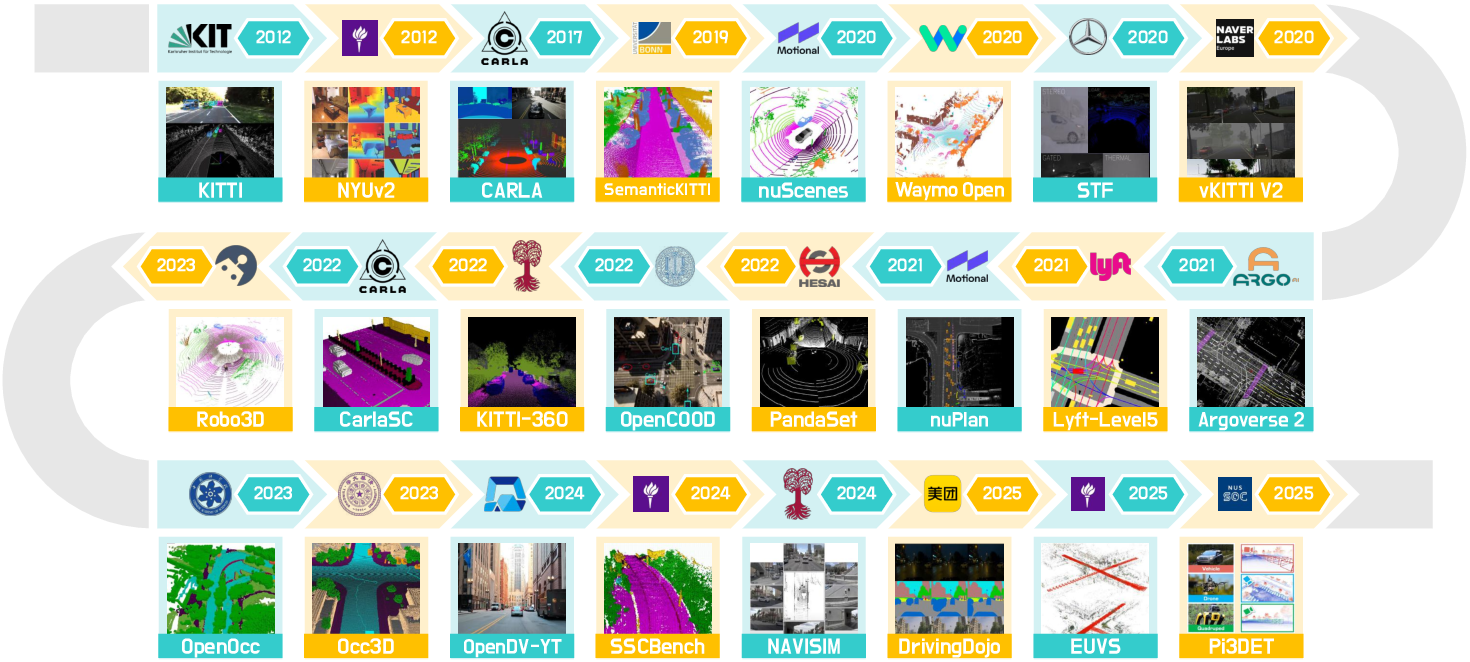
Figure 6: Summary of datasets and benchmarks for VideoGen, OccGen, and LiDARGen models.
Evaluation metrics are organized as follows:
- Generation quality: FID, FVD, FRD, FPD, JSD, MMD, spatial/temporal/subject consistency, controllability, and human preference.
- Forecasting quality: IoU, Chamfer distance, L1/L2 errors, temporal consistency.
- Planning quality: ADE, FDE, collision rate, closed-loop success metrics.
- Reconstruction quality: PSNR, SSIM, LPIPS, view consistency.
- Downstream tasks: mAP, NDS, mIoU, tracking, occupancy prediction, VQA.
Quantitative and Qualitative Analysis
The survey provides extensive benchmarking of state-of-the-art models:
- VideoGen: Recent models achieve FID ∼4–7 and FVD <60 on nuScenes, with explicit geometry and temporal modeling yielding the best results. However, a significant gap remains to real data in downstream detection and planning.
- OccGen: Triplane-VAE and structured latent models achieve >90% mIoU for occupancy reconstruction. Structured priors and temporal modeling are critical for long-horizon forecasting.
- LiDARGen: Modern diffusion and flow-based models achieve low FRD/FPD/JSD, with WeatherGen and R2DM leading in fidelity. Temporal coherence remains a challenge for long sequences.
Qualitative results highlight persistent issues:
- VideoGen: Fine-grained details, physical plausibility, and long-tail category fidelity are lacking.
- OccGen: Geometric consistency is strong, but rare structures and small objects are underrepresented.
- LiDARGen: Balancing global scene structure, point sparsity, and object completeness is nontrivial.

Figure 7: Qualitative comparisons of state-of-the-art VideoGen models on nuScenes.
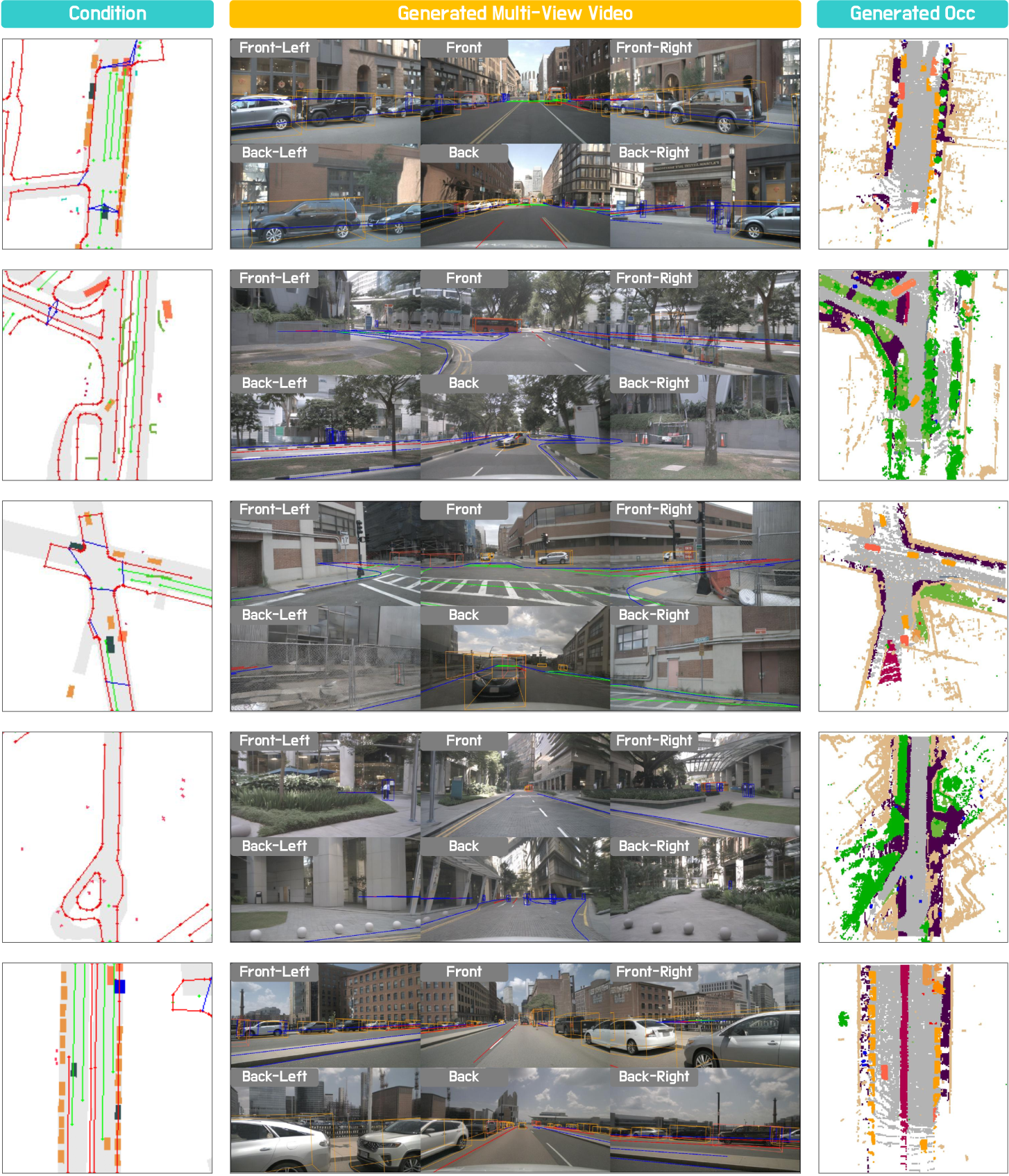
Figure 8: Qualitative examples of OccGen models on nuScenes.

Figure 9: Qualitative comparisons of state-of-the-art LiDARGen models on nuScenes.
Applications
3D/4D world models are deployed in:
- Autonomous driving: Simulation, closed-loop evaluation, and rare scenario synthesis.
- Robotics: Embodied navigation, manipulation, and scalable simulation.
- Video games/XR: Procedural world generation, interactive rendering, and adaptive environments.
- Digital twins: City-scale reconstruction, event replay, and scene editing.
- Emerging domains: Scientific modeling, healthcare, industrial simulation, and disaster response.
Challenges and Future Directions
The survey identifies several open challenges:
- Standardized benchmarking: The lack of unified datasets and protocols impedes fair comparison and progress.
- Long-horizon fidelity: Error accumulation and loss of consistency over long sequences remain unsolved.
- Physical realism and controllability: Current models often violate physical constraints and lack fine-grained editing.
- Computational efficiency: High resource requirements limit scalability and real-time deployment.
- Cross-modal coherence: Ensuring alignment across visual, geometric, and semantic modalities is a persistent challenge.
Conclusion
This survey establishes a rigorous foundation for 3D and 4D world modeling, providing precise definitions, a hierarchical taxonomy, and standardized evaluation. By shifting the focus from 2D visual realism to geometry-grounded, physically consistent modeling, the field is positioned to advance robust, controllable, and generalizable world models for embodied AI. Future progress will depend on open benchmarks, reproducible codebases, and large-scale datasets tailored for 3D/4D modalities, as well as advances in unified generative-predictive architectures and cross-modal reasoning.