- The paper introduces a novel approach leveraging LLM internal reasoning circuits for efficient data selection.
- It uses ablation studies to identify attention heads crucial for mathematical reasoning, significantly reducing required dataset sizes.
- Experimental results show up to a 1.4-point improvement in Pass@1 accuracy, demonstrating the effectiveness of reasoning-aware data selection.
CircuitSeer: Mining High-Quality Data by Probing Mathematical Reasoning Circuits in LLMs
Introduction
LLMs have demonstrated remarkable capabilities in various tasks, including mathematical reasoning. However, training these models efficiently requires robust data selection strategies to optimize computational resources without sacrificing performance. Existing methods often depend on external heuristics or costly computations for data selection, making them inefficient for large-scale applications. CircuitSeer offers an innovative approach by leveraging the internal reasoning circuits of LLMs to guide data selection. This method focuses on attention heads within Transformer models that are critical for reasoning processes, which are systematically identified and used to evaluate and select high-quality data subsets.
Methodology
CircuitSeer's methodology revolves around the identification and utilization of specific attention heads that form reasoning circuits in LLMs. The approach involves two main stages: detecting reasoning circuits and data selection.
Detecting Reasoning Circuits
The reasoning circuits are identified by evaluating the contribution of each attention head in the LLM during reasoning tasks. This evaluation involves ablation studies where the attention weights of each head are selectively scaled to determine its influence on the model's performance.
1
2
3
4
5
6
7
8
9
|
def detect_reasoning_heads(model, probe_data):
reasoning_heads = []
for head in model.attention_heads:
# Perform ablation
ablate(head, model)
loss_increase = evaluate_loss_increase(model, probe_data)
if loss_increase > threshold:
reasoning_heads.append(head)
return reasoning_heads |
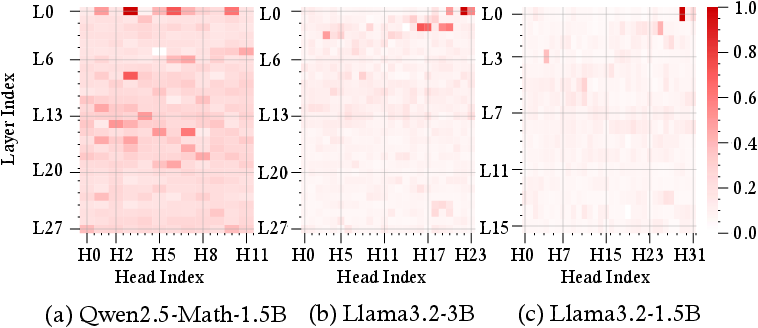
Figure 1: Heatmaps of attention-head importance during probe reasoning dataset across four models: (a) Qwen2.5-Math-1.5B, (b) Llama3.2-3B, (c) Llama3.2-1B-Instruct. Brighter cells indicate higher contribution to reasoning.
Data Selection
Once reasoning heads are identified, they are used to score potential training samples based on how much they activate these heads. Samples that engage these reasoning circuits more are assumed to be of higher reasoning quality and are thus prioritized for selection.
1
2
3
4
5
6
7
8
9
|
def score_samples_with_heads(samples, reasoning_heads):
sample_scores = {}
for sample in samples:
score = 0
# Calculate attention distribution using reasoning heads
for head in reasoning_heads:
score += calculate_attention_score(sample, head)
sample_scores[sample] = score
return sample_scores |
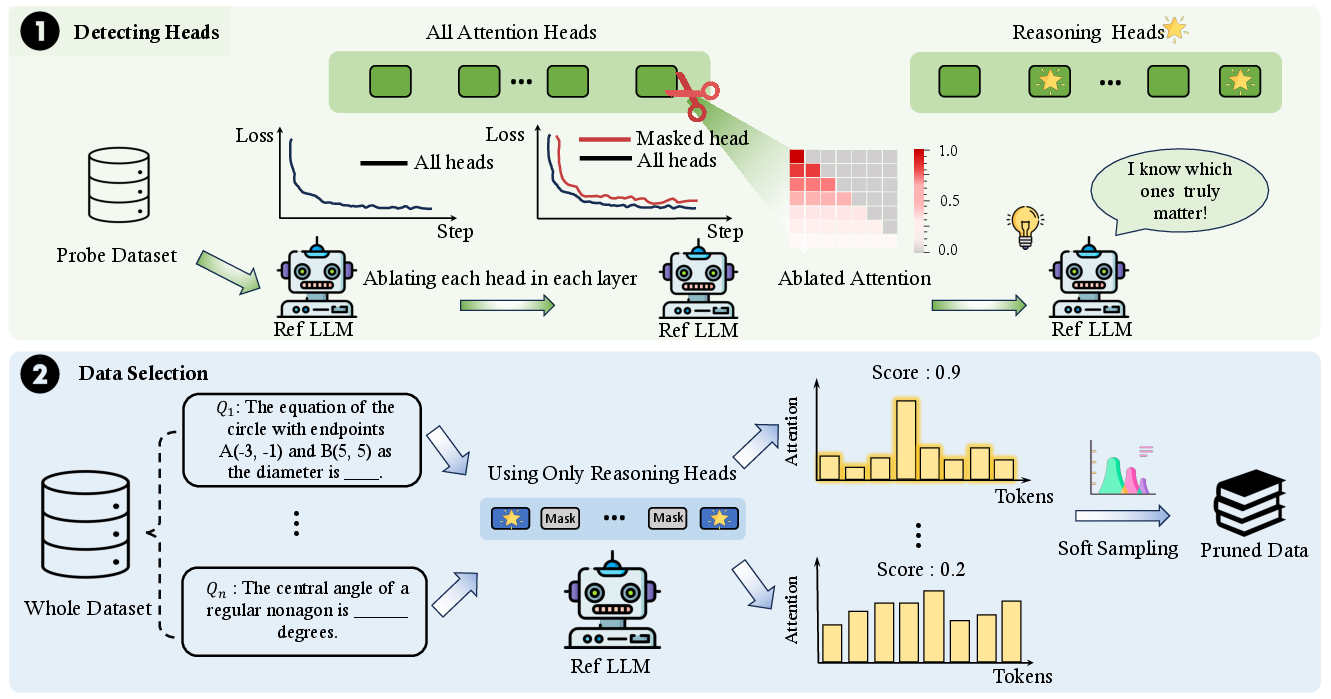
Figure 2: Overview of the CircuitSeer pipeline for reasoning-aware data selection.
Experiments and Results
CircuitSeer was rigorously evaluated across multiple datasets and models, including Qwen2.5-Math and Llama variants. The experiments demonstrate CircuitSeer's ability to outperform traditional data selection techniques by achieving higher performance with less data.
In controlled experiments, models fine-tuned using CircuitSeer-selected subsets achieved up to a 1.4-point improvement in Pass@1 accuracy compared to training on the full dataset. This result indicates that CircuitSeer's method of prioritizing reasoning-intensive data is effective in improving the model's reasoning capabilities with reduced dataset sizes.
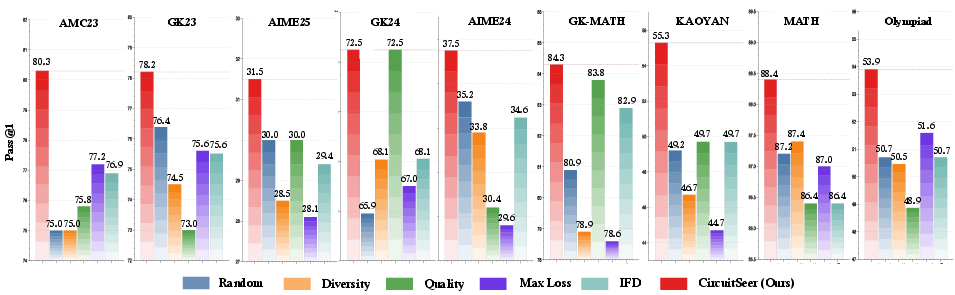
Figure 3: Pass@1 Performance comparison of CircuitSeer against baseline methods across 9 benchmark datasets on Qwen2.5-Math-7B-Base.
Implications and Future Work
CircuitSeer bridges the gap between mechanistic interpretability and practical data selection by providing a principled approach that uses a model's own architecture to inform data decisions. This marks a shift from opaque, externally generated heuristics to transparent, mechanism-driven selection strategies. Future work could extend CircuitSeer's methodology to other domains requiring intricate reasoning, enhancing more applications of LLMs with efficient data utilization.
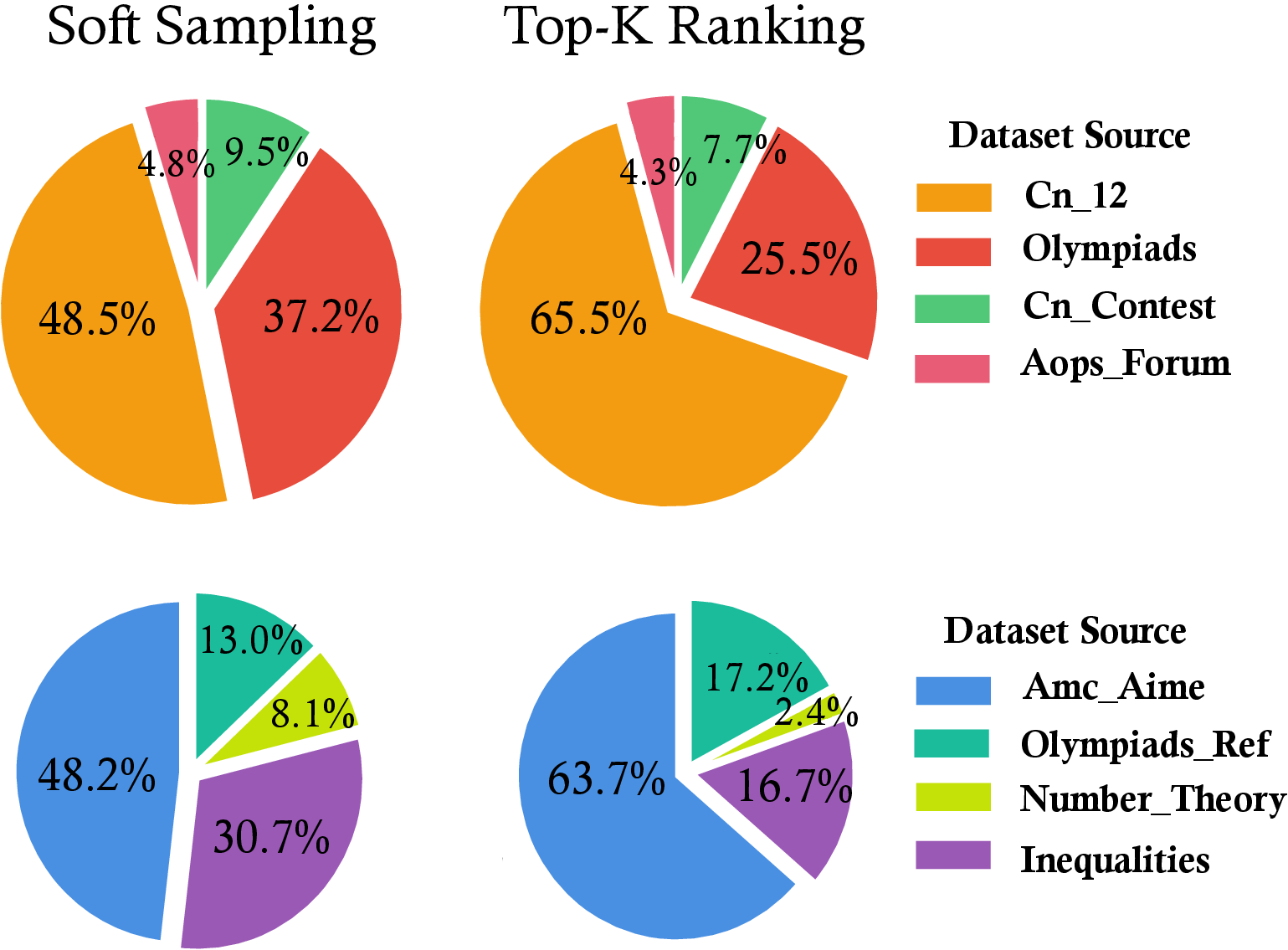
Figure 4: Comparison of the source data distribution for subsets selected by Soft Sampling versus the Top-k Selection baseline.
Conclusion
CircuitSeer exemplifies the potential of leveraging internal model mechanisms for efficient data selection in LLMs. By focusing on reasoning-specific attention circuits, it paves the way for more effective and computationally feasible training strategies, ensuring that high-quality data drives the continued improvement of AI systems' reasoning abilities. With its principled approach, CircuitSeer establishes a new standard for the intersection of model interpretability and training efficiency.
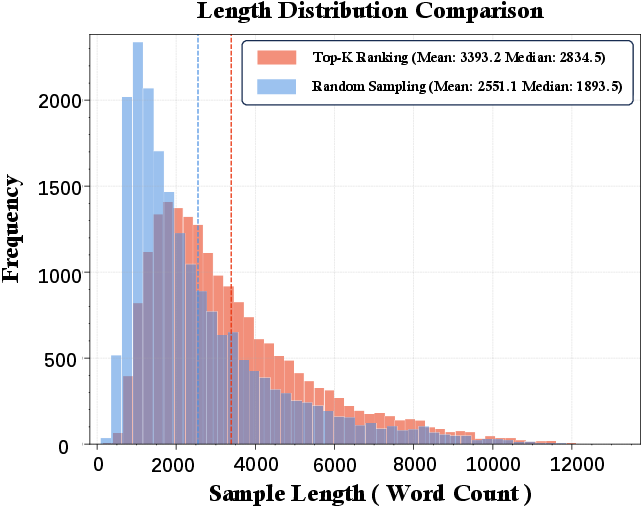
Figure 5: Comparison of the example length distribution between subsets selected by Top-K ranking and Random sampling.

