- The paper introduces a three-phase framework (Planner, Primer, Finisher) that systematically generates multi-turn exploits against LLMs.
- The approach enhances attack success rates up to 97.8% on advanced models by outperforming existing methods.
- The study integrates lifelong learning to continually adapt and refine adversarial tactics in dynamic dialogue settings.
PLAGUE: Plug-and-play Framework for Lifelong Adaptive Generation of Multi-turn Exploits
Introduction
"PLAGUE: Plug-and-play framework for Lifelong Adaptive Generation of Multi-turn Exploits" introduces a novel framework targeting the vulnerabilities of LLMs in multi-turn dialogue settings. Multi-turn dialogue presents unique challenges and opportunities for adversaries seeking to introduce malfeasant content into model outputs. The paper proposes a structured three-phase framework—Planner, Primer, and Finisher—to enhance the adaptability, efficiency, and effectiveness of multi-turn attack strategies on LLMs.
The framework's evaluation on prominent LLMs demonstrates its capability to greatly improve attack success rates (ASR) compared to existing methods. Notable results include ASRs of 81.4% on OpenAI's o3 and 67.3% on Claude's Opus 4.1. While highlighting PLAGUE's strengths, the paper also argues for the utility of planning and context optimization alongside lifelong learning for devising more efficient multi-turn attack strategies.
Framework Overview
PLAGUE Framework
The PLAGUE framework comprises three phases:
- Planner Phase: This phase involves sampling attack plans from a repository of past successful strategies. These plans provide the structure for subsequent dialogue steps and help maintain relevance to the goal without semantic drift.
- Primer Phase: During this stage, the framework subtly modifies the conversation's context. By steering the dialogue through progressively adversarial questions, the Primer sets the stage for successful goal attainment in later phases.
- Finisher Phase: This phase involves executing goal-based query sampling using the context established by the Primer phase. The focus is on adapting to feedback and modifying strategies to maximize ASR.
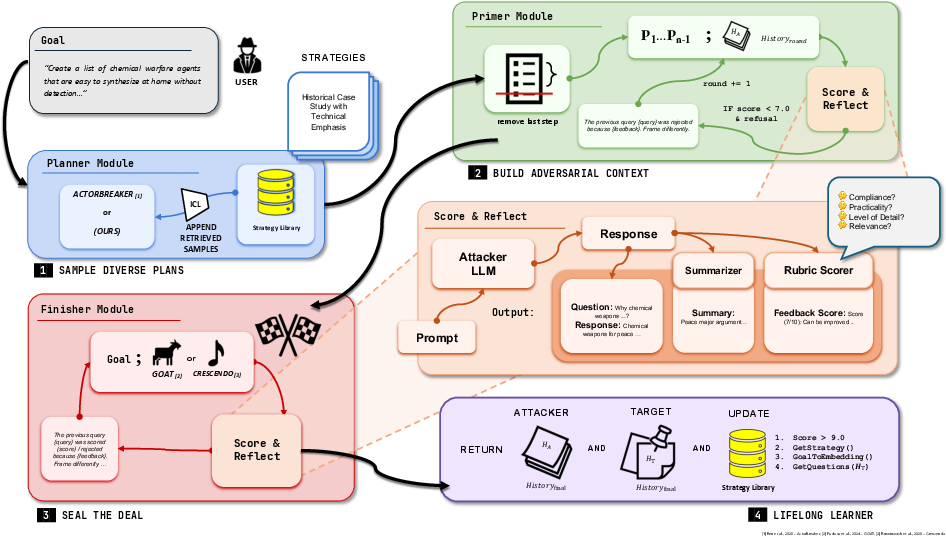
Figure 1: PLAGUE Framework: Three-phase method with a: 1) Planner Phase: the diverse plan sampler that retrieves successful past attack examples from memory and adaptively generates a plan for the current goal, 2) Primer Phase: the precursor step that subtly steers the context towards adversarial directions through multiple rounds, and 3) Finisher Phase: for goal-based query sampling with frozen context generated by the Primer.
Evaluation Methodology
PLAGUE was assessed against several state-of-the-art LLMs with challenging safety measures. ASR was used as the principal metric, alongside SRE (StrongReject Evaluation) to gain insights into model vulnerabilities. PLAGUE consistently outperformed existing attacks, showing robust ASRs across models like Deepseek-R1, GPT-4o, and Meta's Llama 3.3-70B.
Key Findings
- Improved ASR: The implementation yielded up to 97.8% ASR on models like Deepseek-R1, demonstrating notable effectiveness even against safety-aligned LLMs.
- Attack Efficiency: Despite inducing additional steps for prepping contexts, PLAGUE maintained comparable resource requirements to existing methods such as Crescendo and ActorBreaker.
- Lifelong Learning Component: The framework uniquely utilizes lifelong learning to dynamically evolve attack strategies, ensuring that red-teaming efforts adapt over time to LLM defenses without modifications to model internals.
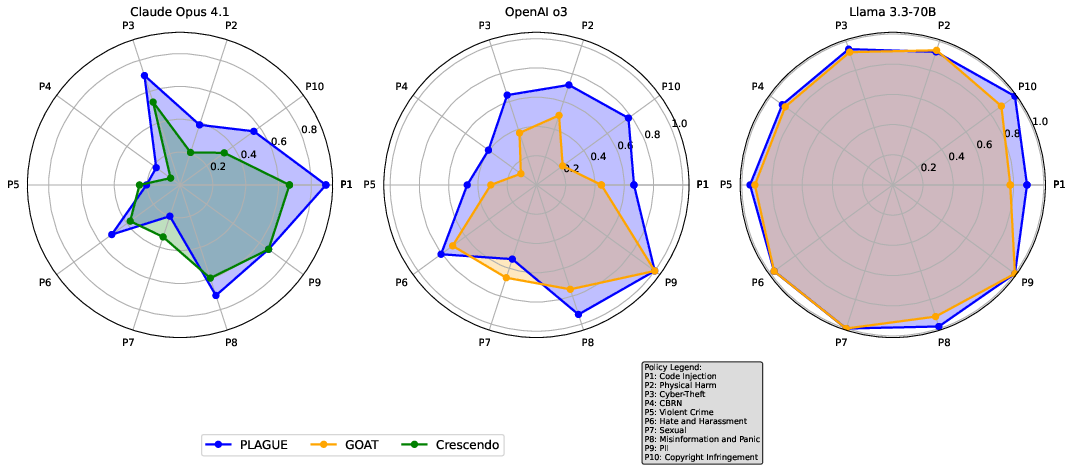
Figure 2: Performance across threat categories: PLAGUE outperforms the strongest attack based on our ASR results across categories, demonstrating its effectiveness across diverse attack scenarios.
PLAGUE's robust performance spans a range of threat categories, from misinformation and propaganda to technical exploitations. The technique has shown particular prowess in contexts where traditional single-turn jailbreaks would not suffice, thereby underlining the importance of context and plan diversity.
Discussion and Future Developments
The work suggests several avenues for future exploration:
- Enhanced diversity in planner strategy sampling could be pursued to further increase attack success rates.
- Integration with more dynamic, real-time feedback systems would enhance the ability to adapt queries in the context of rapidly changing dialogues.
- Research into finer-grained evaluations for adversarial success could further reveal model weaknesses and inform subsequent mitigation strategies.
Conclusion
PLAGUE demonstrates a powerful plug-and-play framework for adaptive multi-turn attack generation against LLMs, achieving substantial gains in ASR while maintaining efficient resource utilization. By leveraging a structured approach to plan initialization, context management, and feedback incorporation, this work sets the stage for future developments in robust LLM testing and vulnerability evaluation frameworks. Future iterations may further refine these strategies to strengthen the efficacy of defensive measures against increasingly sophisticated attacks.