- The paper introduces DPM, extending viewpoint-invariant point maps to achieve bi-invariance across time and space for unified dynamic scene understanding.
- The paper demonstrates significant improvements, reducing scene flow errors by up to 76% and lowering mean absolute relative depth errors by 17.5% in dynamic scenarios.
- The paper applies DPM to various tasks including motion segmentation, 3D object tracking, and camera pose recovery without iterative test-time optimization.
Dynamic Point Maps: Unified Representation for Dynamic 3D and 4D Vision
Introduction and Motivation
Dynamic 3D scene interpretation is an open challenge in visual geometry. While static scene reconstruction via multi-view geometry and learned representations such as point maps has matured, state-of-the-art vision systems lag behind in handling dynamic scenes, where the scene content itself varies over time. The paper "Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction" (2503.16318) addresses this limitation by extending viewpoint-invariant point maps, as instantiated in DUSt3R, to dynamic scenarios. The resulting formulation, Dynamic Point Maps (DPM), enables feed-forward, dense prediction of spatiotemporally invariant correspondences. This facilitates a unified system for both classical 3D tasks (e.g., camera and shape recovery) and 4D tasks (motion segmentation, scene flow, rigid tracking).

Figure 1: Diagram showing the extension from DUSt3R to DPM: each image yields two point maps corresponding to the timestamps of both images, mapped into the reference frame of I1; scene flow and dynamic correspondence are directly computable.
From Point Maps to Dynamic Point Maps
Limitations of Viewpoint Invariance in Dynamics
In static scenes, mapping pixels to 3D points in a fixed reference frame achieves viewpoint invariance. Consequently, pixel-wise correspondences, camera parameters, and scene structure become trivial to infer (as observed with DUSt3R). However, in dynamic environments, where objects and surfaces move or deform, viewpoint invariance alone is no longer sufficient: two pixels corresponding to the same scene point at t1 and t2 will not, in general, map to the same 3D position when only adjusting for viewpoint, as scene points follow their own trajectories.
DPM Design: Controlling for Viewpoint and Time
DPM augments conventional point maps by making them bi-invariant: invariant to both viewpoint and time. For any image pair (I1,t1,π1), (I2,t2,π2), the system predicts for every image pixel not only its (viewpoint-normalized) 3D position at its native timestamp, but also at the other timestamp from the same viewpoint (and reference pose frame). This yields four per-pixel predictions:
- P1(t1,π1) (self-time, self-view)
- P1(t2,π1) (other-time, self-view)
- P2(t1,π1) (self-time, other-view mapped to self-view)
- P2(t2,π1) (other-time, other-view mapped to self-view)
This minimal, symmetric set of maps enables invariant matching, dense scene flow retrieval, 4D scene reconstruction, temporal fusion, and direct downstream application to rigid/nonrigid tracking.
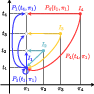
Figure 2: For four input images, DPM produces 8 point maps indexed by both viewpoint and time, shown here in a viewpoint-time schematic and as fused temporal point clouds.
Model Architecture and Supervision Paradigm
Network Instantiation
DPM is implemented by a straightforward extension of the existing transformer-based DUSt3R backbone. Each image now yields two regression heads instead of one: outputting per-pixel 3D coordinates (in the reference frame π1) at both time steps, as well as corresponding confidence maps. All regression is up to a global scale, as depth and structure-from-motion are only determined up to similarity from monocular or stereo cues.
Supervision Sources and Data Organization
Supervision of DPM training leverages a blend of (1) fully-dynamic synthetic datasets (Kubric MOVi-G/F, Waymo), which supply precise, ground-truth dynamic correspondences and complete 4D supervision; (2) partially-annotated datasets (PointOdyssey, Spring) for same-time maps; and (3) static scene datasets (ScanNet++, BlendedMVS, MegaDepth), which collapse time to a single configuration (see Appendix for detailed schedule and annotation strategy).
Loss and Optimization
The paper uses scale-invariant, per-point regression loss with confidence calibration, closely following the DUSt3R regime but extended to aggregate all four required point maps. Synthetic data yields all requisite supervision; in real data, the architecture falls back to reconstructing static scenes where all point maps coincide.
Empirical Results and Analysis
DPM matches or slightly surpasses prior approaches—including MonST3R—on benchmark depth datasets, especially under challenging camera egomotion and nonrigid scene dynamics. The representation yields approximately 17.5% lower mean absolute relative errors in aggressive multi-dataset scenarios.
Dynamic Reconstruction and Scene Flow
The decisive advantage of DPM surfaces in dynamic 3D tasks. Unlike prior methods that combine stereo/depth maps with 2D optical flow (e.g., MonST3R+RAFT, which is limited in the presence of occlusions or large displacements), DPM explicitly predicts cross-time 3D positions in a shared reference frame, making dense scene flow and object flow direct differences of predicted values. On strictly dynamic tests, DPM lowers mean 3D scene flow errors by up to 76% compared to MonST3R, and attains object-flow metrics previously only matched by RGBD-input systems—despite using only RGB signals.

Figure 3: Qualitative comparison of scene flow estimations; MonST3R (left) is prone to artifacts, direction errors, and fails to resolve disocclusions (red boxes); DPM (right) yields temporally and spatially accurate flow.
Downstream Applications
- Motion Segmentation: DPM enables segmentation of dynamic regions as the per-pixel difference of Pi(t1,π1) and Pi(t2,π1). Unlike per-frame or optical-flow-based approaches, camera motion and scene motion are properly decoupled and only scene motion is measured.

Figure 4: DPM-driven motion segmentation successfully isolates dynamic objects despite camera egomotion.
- 3D Object Tracking: By extracting masks for salient objects, DPM supports direct estimation of 3D bounding box trajectories using Procrustes alignment of predicted object-centric point clouds between time steps.

Figure 5: DPM enables bounding box tracking by aligning masked dynamic point clouds between frames.
- Correspondence and Temporal Fusion: Spatiotemporal invariance permits straightforward pixel-to-pixel correspondences across frames and fusing predicted point clouds of different time steps, essential for occlusion-aware aggregation and long-term tracking.
- Camera Tracking and Motion Estimation: Camera poses can be recovered via Procrustes fits between globally aligned static scene points, directly ignoring dynamic regions using predicted confidence.
Practical and Theoretical Implications
The DPM framework demonstrates that, by unifying spatiotemporal invariance in the point map formulation, a single (RGB-only) neural model can be applied to static and dynamic scene reconstruction, multi-frame correspondence, 3D/4D scene flow, and object/camera tracking—without iterative test-time optimization or dependency on 2D flow or warping intermediates.
Empirical results present strong, consistent improvement on both synthetic and in-the-wild data, attesting to the scalability and generality of the DPM formalism. The architecture streamlines pipelines for dynamic multi-view perception, mitigating overheads for downstream reasoning and opening the door to feed-forward, multi-task 3D foundation models that jointly predict geometry, flow, and correspondence.
Future Directions
Future research can pursue:
- Integration into Video-Foundation Models: Extending DPM beyond pairs to long sequences as a space-time equivariant primitive for large-scale 4D models.
- Unsupervised and Weakly-supervised Training: Relaxing or generalizing the current reliance on full synthetic annotation.
- Unified 4D Representations: Fusing DPM with radiance field or volumetric generative models to couple geometry and appearance in a dynamic context.
- Real-time, Online 4D Perception: Leveraging the feed-forward property for high-frequency, scalable real-world tracking and robotics.
Conclusion
Dynamic Point Maps offer a tractable and extensible representation for dynamic 3D reconstruction, reducing core geometric and motion analysis tasks to direct regression in a feed-forward DNN. By satisfying both viewpoint and temporal invariance, DPM bridges traditional geometry pipelines and modern deep learning, delivering robust performance across a spectrum of complex tasks in dynamic visual environments.

