- The paper establishes that retrain equivalence in machine unlearning is unachievable due to inherent path-dependent training effects.
- It utilizes overparameterized linear regression models to mathematically demonstrate exponential divergence caused by training order variations.
- Empirical evaluations on LLMs reveal that sequential data exposure, especially the recency effect, significantly hinders local unlearning accuracy.
On the Impossibility of Retrain Equivalence in Machine Unlearning
Introduction
The paper "On the Impossibility of Retrain Equivalence in Machine Unlearning" addresses the challenging problem of machine unlearning, specifically targeting the notion of Retrain Equivalence (RE). This concept refers to a model's ability to yield identical behavior to one retrained from scratch on a subset of data that excludes the "forget set." The study extends traditional assumptions centered on i.i.d. datasets, which modern multi-stage training methodologies challenge. Through theoretical foundations and empirical evidence using LLMs, the paper elucidates why achieving RE is fundamentally infeasible in local unlearning algorithms absent path dependency consideration.
Theoretical Insights
At the core of the research is the realization that multi-stage training significantly impacts unlearning algorithms. In staged training, models encounter diverse datasets sequentially, which means subsequent model behavior, when subjected to unlearning tasks, is inextricably linked with the specific sequence of prior training data exposure. The work mathematically demonstrates path-dependent divergence using overparameterized linear regression models. These models, trained on identical datasets but differing in order, exhibit exponential divergence in predictions after the same local unlearning rule is applied. Thus, it is theoretically impossible for a path-oblivious, local unlearning algorithm to universally achieve RE.
Figure 1: History dependence of gradient ascent unlearning. Each panel demonstrates the distinctive unlearning process due to the order of dataset exposure in the training sequence.
Experimental Evaluation
The empirical section demonstrates practical implications by analyzing the unlearning behavior of LLMs from the Llama and Qwen model families. These models were fine-tuned with varying dataset sequences and subjected to identical unlearning protocols using gradient ascent and variations such as NPO and SimNPO. The experiments consistently affirmed path dependence, with substantial variances in accuracy degradation post-unlearning, evidencing the theoretical predictions that compensation for model behavior can not be path-oblivious.
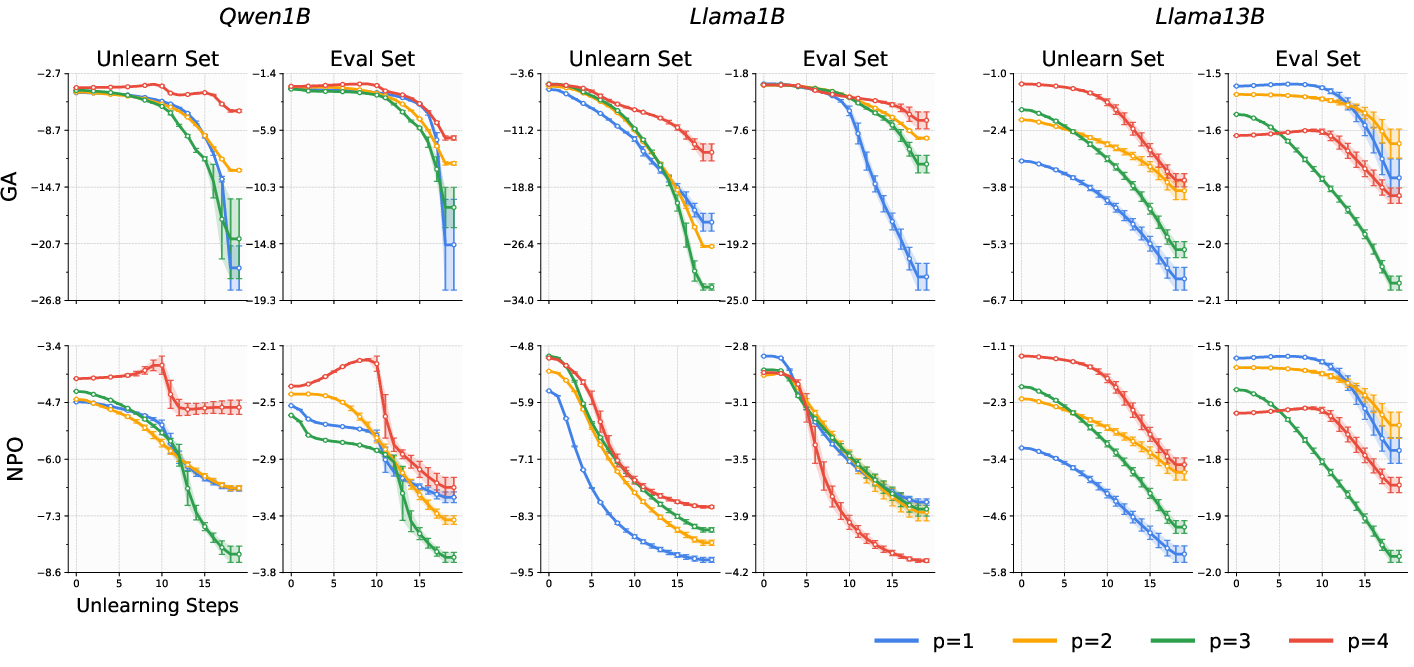
Figure 2: Change in forget quality and retained utility in three models, showcasing path-dependent IEEE divergences during unlearning.
Path Dependency and the Recency Effect
A novel phenomenon identified is the "recency effect," where unlearning proceeds most sluggishly when the forget set is the final exposure in the training sequence. This effect suggests that models optimize parameters profoundly during their last-exposed dataset segment, causing subsequent unlearning to misalign with previous learning stages.
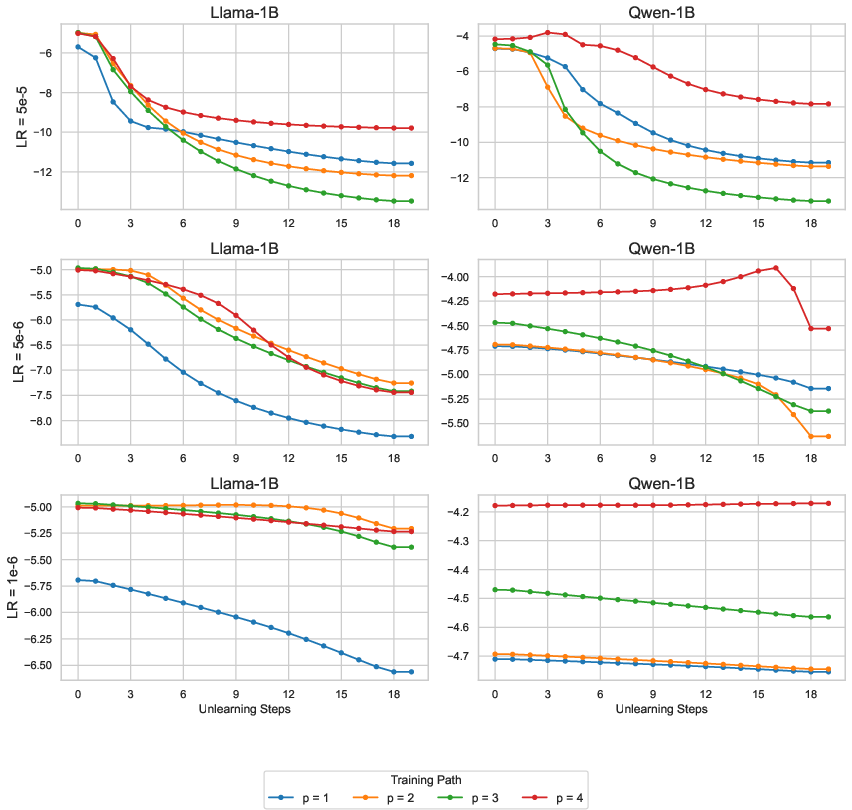
Figure 3: The recency effect persists across different learning rates, indicating a standard neural network property when subjected to unlearning algorithms.
Implications and Future Directions
This work illuminates the inherent conflict between achieving RE and the path dependency imposed by staged training in modern LLM architectures. Important implications include the call for reevaluating unlearning objectives beyond simple metrics that overlook these complexities. The research intertwines theoretical limitations with practical challenges, urging significant rethinking in deploying machine unlearning algorithms, especially in regulatory contexts where data erasure and model updates impart legal and ethical obligations.
Conclusion
In summary, the paper decisively unravels the impracticality of achieving Retrain Equivalence in machine unlearning through local algorithms lacking historical consideration. This finding has profound implications for designing and evaluating unlearning methods, advocating for nuanced approaches that transcend current evaluative measures restricted by singular retrain baseline ideals. By bridging theoretical insights with empirical evidence, the study sets a platform for future explorations into robust and contextually aware unlearning algorithms.