- The paper introduces the Thinker-Talker architecture and TMRoPE, enabling synchronized real-time text and speech generation.
- It employs specialized encoders for text, audio, images, and video to achieve state-of-the-art multimodal performance on the Omni-Bench suite.
- Training in three phases with extensive multimodal datasets underscores its capability for coherent, low-latency streaming responses.
Introduction
The "Qwen2.5-Omni Technical Report" delineates the development of Qwen2.5-Omni, an advanced multimodal model capable of integrating text, audio, images, and video inputs. The model is designed to deliver both real-time text and speech outputs, enhancing human-computer interaction through seamless integration of multimodal information. This document explores the architectural innovations, encoding strategies, and the performance benchmarks of Qwen2.5-Omni.
Model Architecture and Design
Thinker-Talker Architecture
The Qwen2.5-Omni employs the Thinker-Talker architecture (Figure 1), wherein the Thinker acts as a LLM responsible for text generation, and the Talker generates streaming speech. This separation facilitates the efficient handling of text and spoken outputs while maintaining synchronization via shared high-level representations.
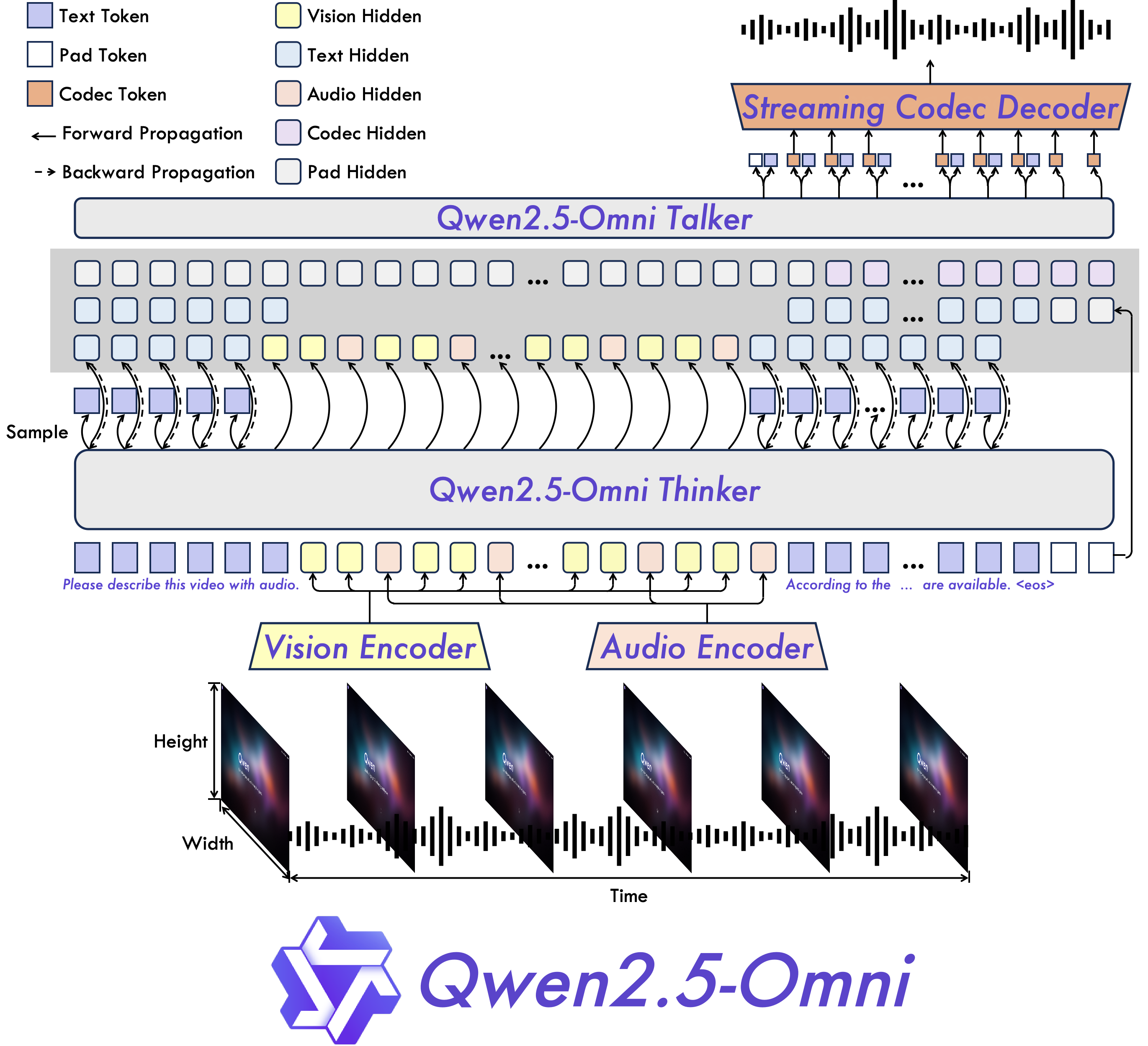
Figure 1: The overview of Qwen2.5-Omni. Qwen2.5-Omni adopts the Thinker-Talker architecture. Thinker is tasked with text generation, while Talker focuses on generating streaming speech tokens by receiving high-level representations directly from Thinker.
Positional Encoding with TMRoPE
To synchronize multimodal inputs, the Qwen2.5-Omni applies a novel Time-aligned Multimodal Rotary Position Embedding (TMRoPE) (Figure 2). This encoding scheme effectively integrates temporal information across audio and video modalities, ensuring accurate synchronization within the model.

Figure 2: An illustration of Time-aligned Multimodal RoPE~(TMRoPE).
Data Processing and Encoding
The model processes multimodal inputs through various encoders: a tokenizer for text, a ViT-based vision encoder for images and video, and an audio encoder converting waveforms into mel-spectrograms. This structured approach ensures comprehensive perception across modalities by leveraging specialized encoders for each type of data.
Streaming Architecture
A distinct feature of the Qwen2.5-Omni model is its capability for real-time processing. Both audio and video encoders use a block-wise processing approach, facilitating low-latency streaming and coherent synthesis of speech and text outputs. The sliding window attention mechanism within the Talker (Figure 3) supports this by minimizing initial response delays, enabling near-immediate feedback.
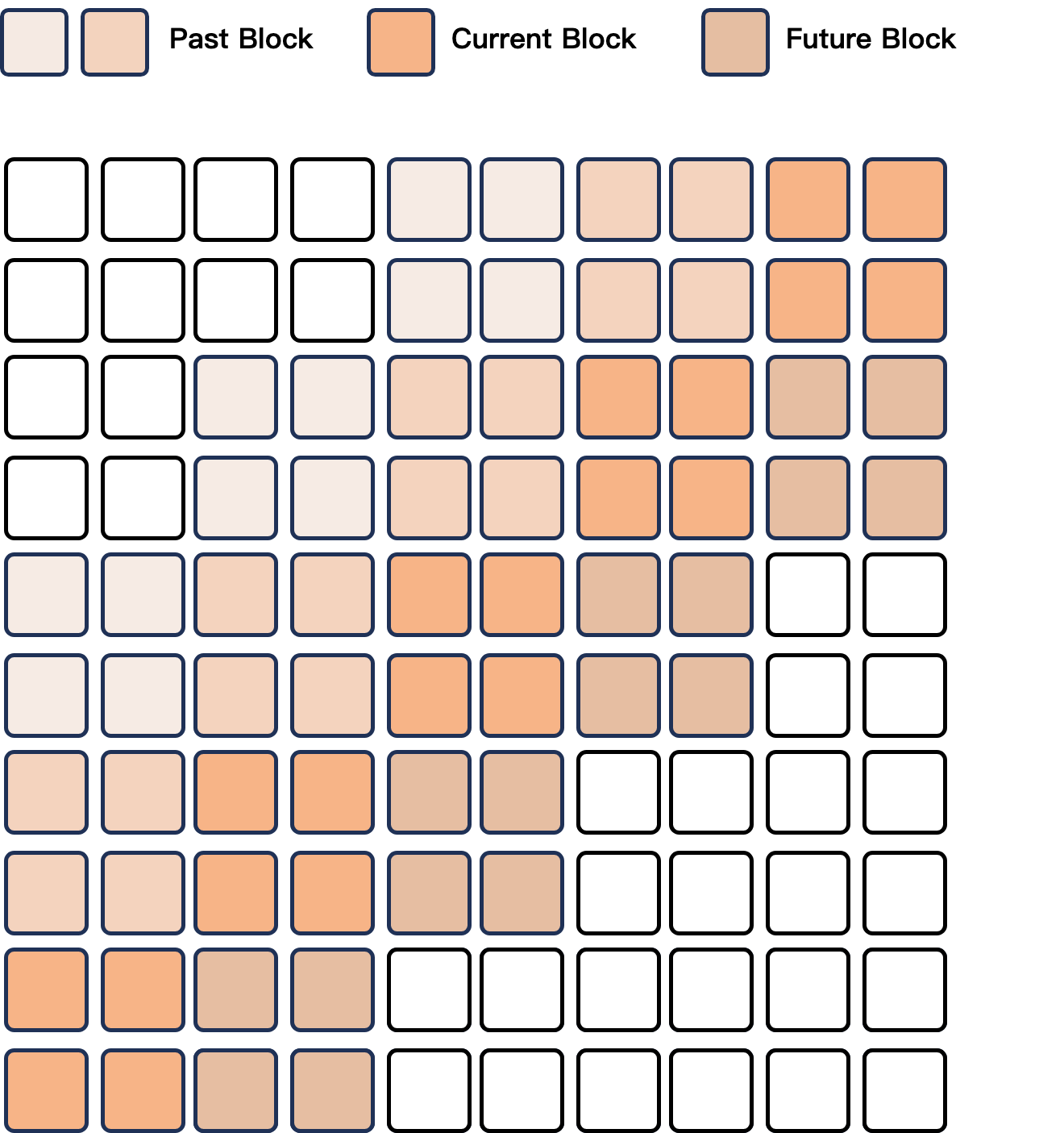
Figure 3: An illustration of sliding window block attention mechanism in DiT for codec to wav generation.
Training Methodology
The training of Qwen2.5-Omni was conducted in three phases, initially isolating the encoders by freezing LLM parameters, then expanding to comprehensive multimodal datasets, and finally stretching sequence handling capacity. Fine-tuning stages employed extensive datasets comprising multimodal combinations, with instruction-following datasets formatted in ChatML enhancing conversational abilities.
Empirical Results
Benchmarks reveal that Qwen2.5-Omni excels in multimodal tasks, particularly on the Omni-Bench suite, achieving state-of-the-art performance. Its proficiency in processing mixed modalities, such as audio-video synchronization in real-time, highlights the model's advanced capabilities in coherent speech instruction following and text-audio integration tasks.
Conclusion
The Qwen2.5-Omni model represents a significant step forward in multimodal AI, offering an integrative approach to processing diverse data types. By employing advanced architectural designs and encoding mechanisms, such as the Thinker-Talker architecture and TMRoPE, the model proficiently manages real-time text and speech generation across multiple input modalities. This technical advancement demonstrates potential for broad applications in interactive systems, positioning Qwen2.5-Omni as a versatile tool in the development of more intuitive AI interfaces. Future work will explore the expansion of Qwen2.5-Omni’s capabilities in generating other multimodal outputs, including visual and musical data, to further bridge the gap towards embodied artificial intelligence.