GaussGym: An open-source real-to-sim framework for learning locomotion from pixels
Abstract: We present a novel approach for photorealistic robot simulation that integrates 3D Gaussian Splatting as a drop-in renderer within vectorized physics simulators such as IsaacGym. This enables unprecedented speed -- exceeding 100,000 steps per second on consumer GPUs -- while maintaining high visual fidelity, which we showcase across diverse tasks. We additionally demonstrate its applicability in a sim-to-real robotics setting. Beyond depth-based sensing, our results highlight how rich visual semantics improve navigation and decision-making, such as avoiding undesirable regions. We further showcase the ease of incorporating thousands of environments from iPhone scans, large-scale scene datasets (e.g., GrandTour, ARKit), and outputs from generative video models like Veo, enabling rapid creation of realistic training worlds. This work bridges high-throughput simulation and high-fidelity perception, advancing scalable and generalizable robot learning. All code and data will be open-sourced for the community to build upon. Videos, code, and data available at https://escontrela.me/gauss_gym/.
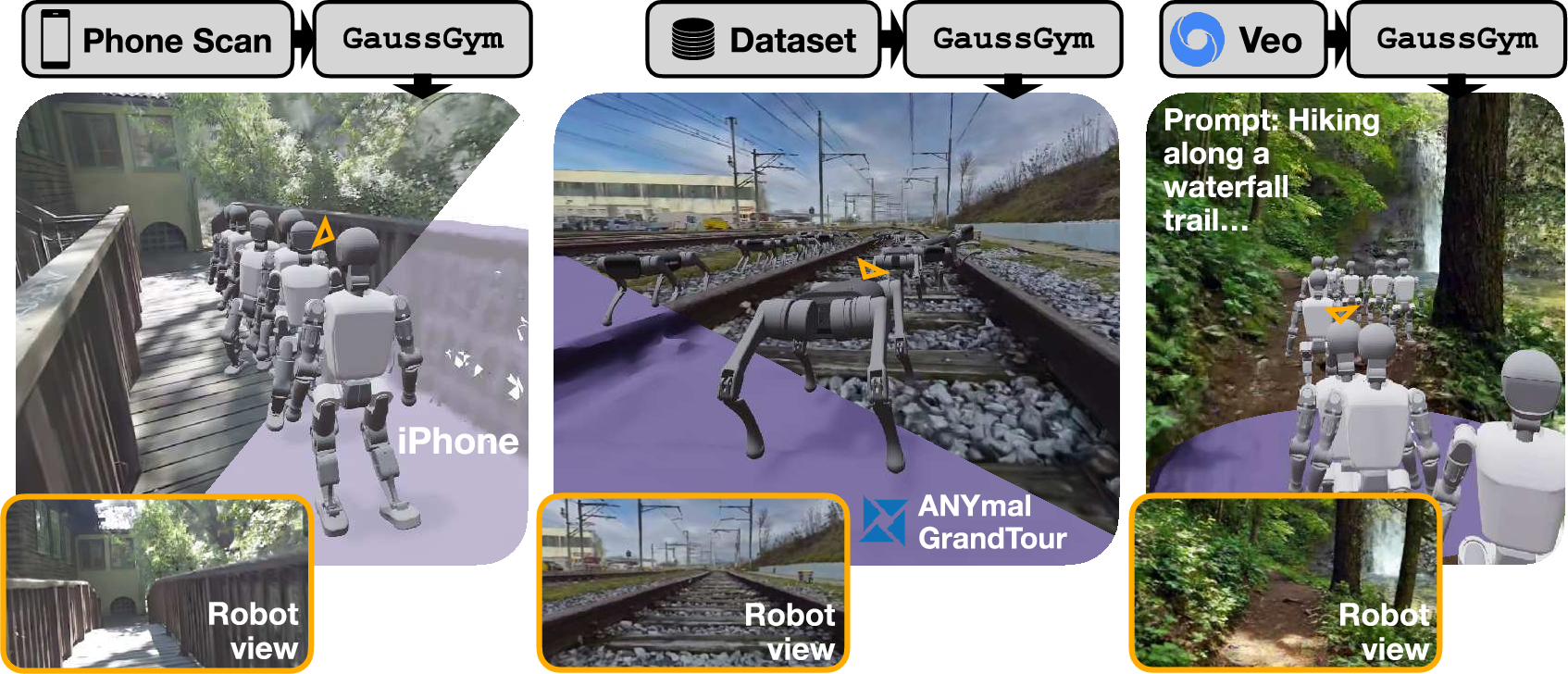





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GaussGym, a fast, free-to-use simulator that helps robots learn to move by looking at camera images (RGB pixels), not just depth sensors. It creates realistic 3D worlds from phone scans, public datasets, and even AI-generated videos, then runs physics and photorealistic graphics together so robots can practice walking, climbing, and navigating—at very high speed.
What questions were the researchers asking?
The authors wanted to know:
- Can we train robots to move using only camera images if the simulator looks realistic enough and runs fast enough?
- Can we easily turn real places (or even AI-made videos) into training worlds for robots?
- Do camera images help robots make smarter choices than depth-only sensing, like avoiding “bad” areas they shouldn’t step on?
- What tricks help close the gap between simulation and the real world (so a policy trained in sim works on a real robot)?
How did they do it?
To make this work, they combined several ideas so the worlds look real, the physics is correct, and everything runs extremely fast.
Building realistic worlds quickly
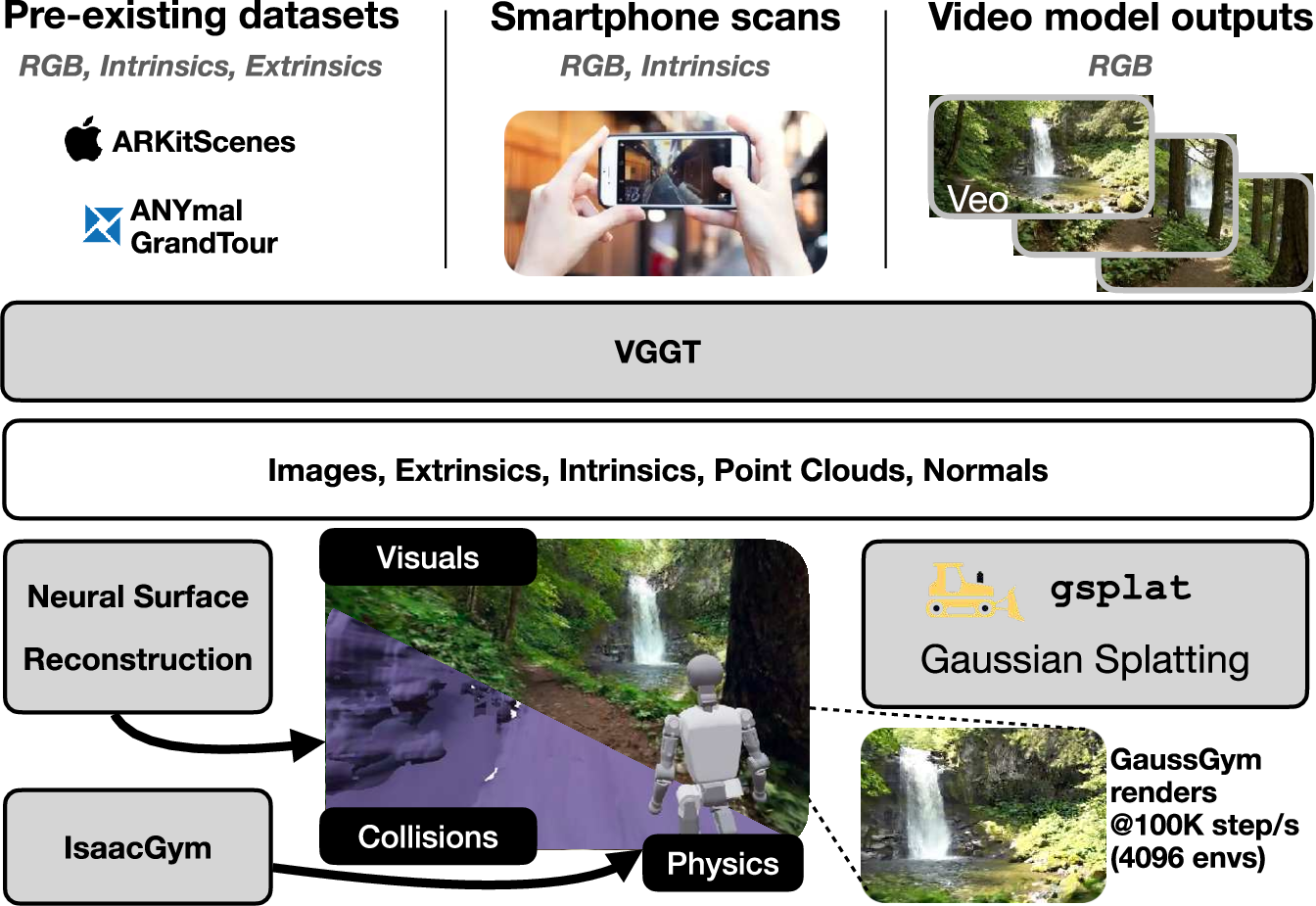
- 3D Gaussian Splatting: Imagine rebuilding a scene out of millions of tiny, soft “paint blobs” in 3D. When you look at them from a camera, these blobs can be drawn very quickly and still look photorealistic. This is much faster than traditional methods, and it naturally produces both color images and depth.
- “Renderer” just means the part that makes the images the robot sees. GaussGym drops this fast renderer into a popular physics simulator so visuals and physics stay in sync.
Bringing real places and AI-made videos into the sim
- They feed in many kinds of data: iPhone scans, existing 3D scene datasets, and even videos from generative models (like Veo).
- A tool called VGGT looks at the images and figures out:
- Camera details (where it was and how it was pointed),
- A dense 3D “point cloud” (lots of 3D dots that outline the scene),
- Surface directions (normals).
- From the point cloud, they:
- Initialize the 3D “blobs” (Gaussians) to get good-looking visuals fast,
- Reconstruct a solid surface mesh (using NKSR) to handle physical collisions.
Think of it like: videos in, a consistent 3D world out, where the robot can both “see” and “bump into” things realistically.
Training the robot’s “brain”
- The robot learns using reinforcement learning (RL): it tries actions, gets rewards (for moving well), and improves over time.
- The input is RGB camera images plus body info (like joint angles). A pre-trained vision model (DINOv2) turns images into useful features, and an LSTM (a memory-based neural net) helps the robot remember what it saw over time.
- Side task for better learning: While learning to move, the robot also learns to guess a coarse 3D map (like which spaces are occupied). This extra “homework” helps it understand the shape of the world from images, which speeds up and stabilizes learning.
Making it fast and realistic
- Vectorized simulation: They run thousands of robot environments in parallel on a single GPU, which massively speeds up training.
- Smart timing: Cameras render at realistic camera frame rates (slower than control), which saves time but keeps visuals accurate.
- Motion blur: They simulate blur by blending a few frames along the camera’s motion direction—this makes images look more like real footage, which helps transfer to real robots.
- Performance: Over 100,000 simulation steps per second across 4,096 environments at 640×480 resolution on a consumer GPU (RTX 4090).
What did they find?
Here are the key results from their experiments:
- Very fast and photorealistic simulation: GaussGym renders realistic scenes at high speed while keeping physics accurate. This makes training from images practical, not painfully slow.
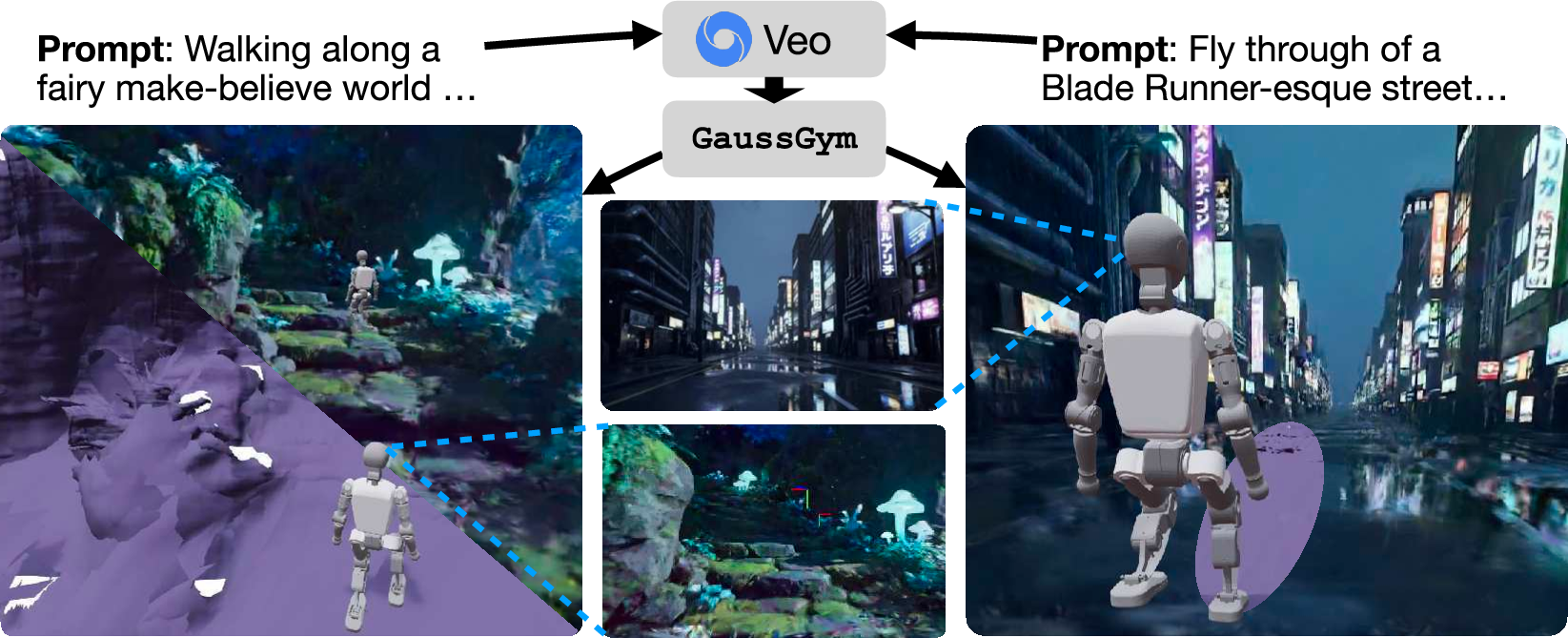
- Learning from pixels works: Robots learned to walk and navigate using only RGB images in many different, realistic-looking worlds, including ones generated by AI video models.
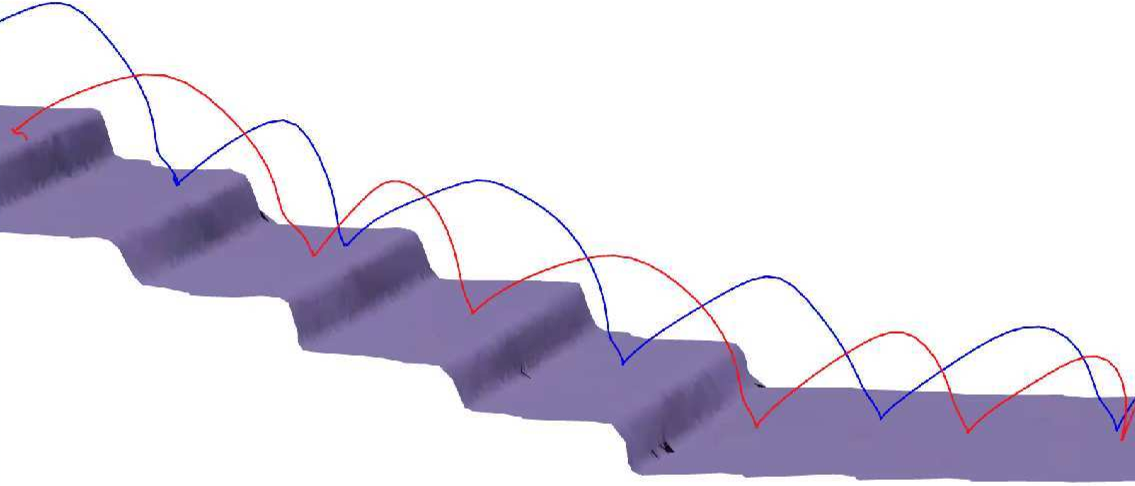
- Helpful side task: Asking the policy to also predict a rough 3D map (occupancy) from images improved learning and performance (for example, on stair climbing).
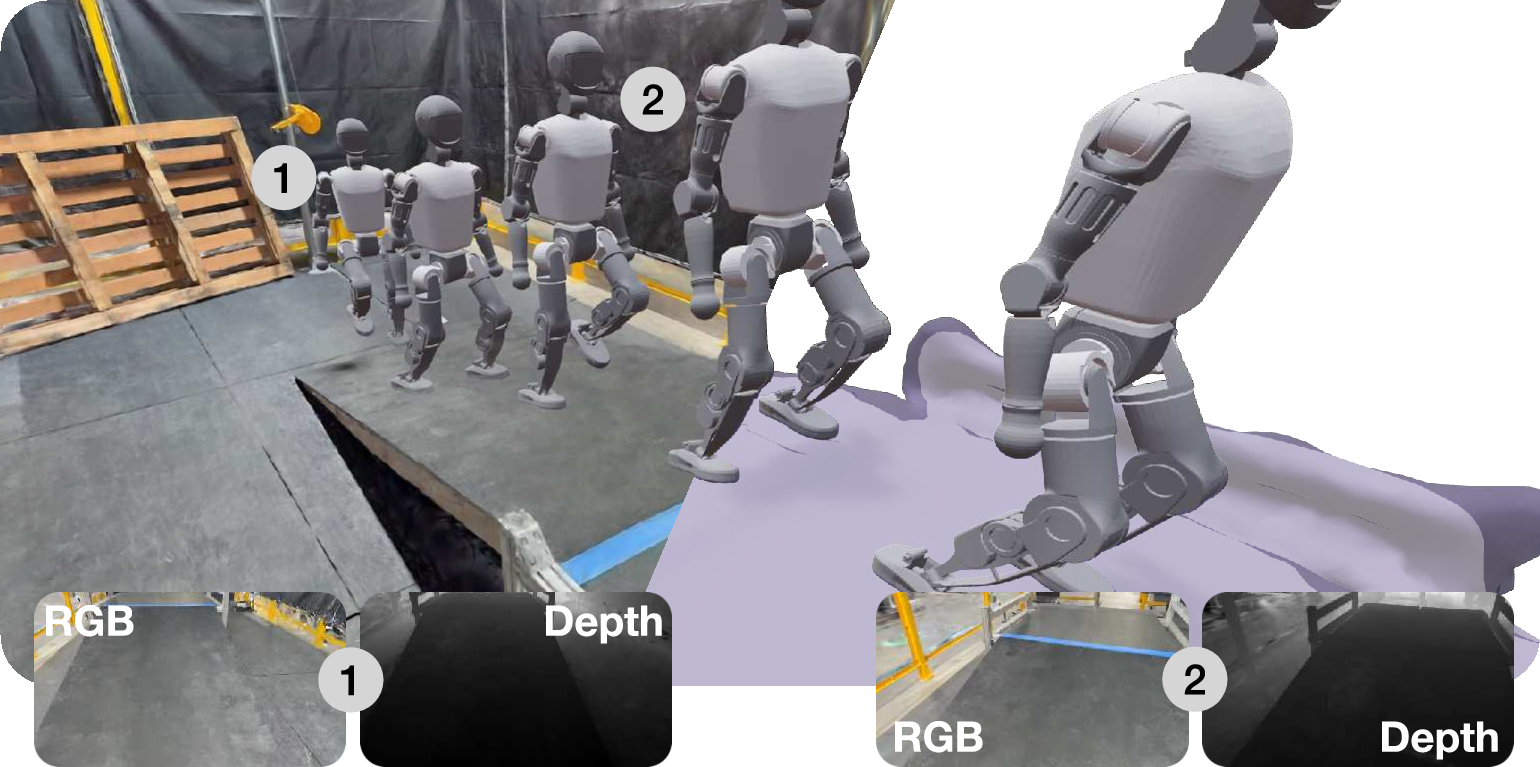
- Sim-to-real transfer: A stair-climbing policy trained in GaussGym transferred to a real quadruped robot (Unitree A1) without extra fine-tuning, showing the approach can work outside the simulator.
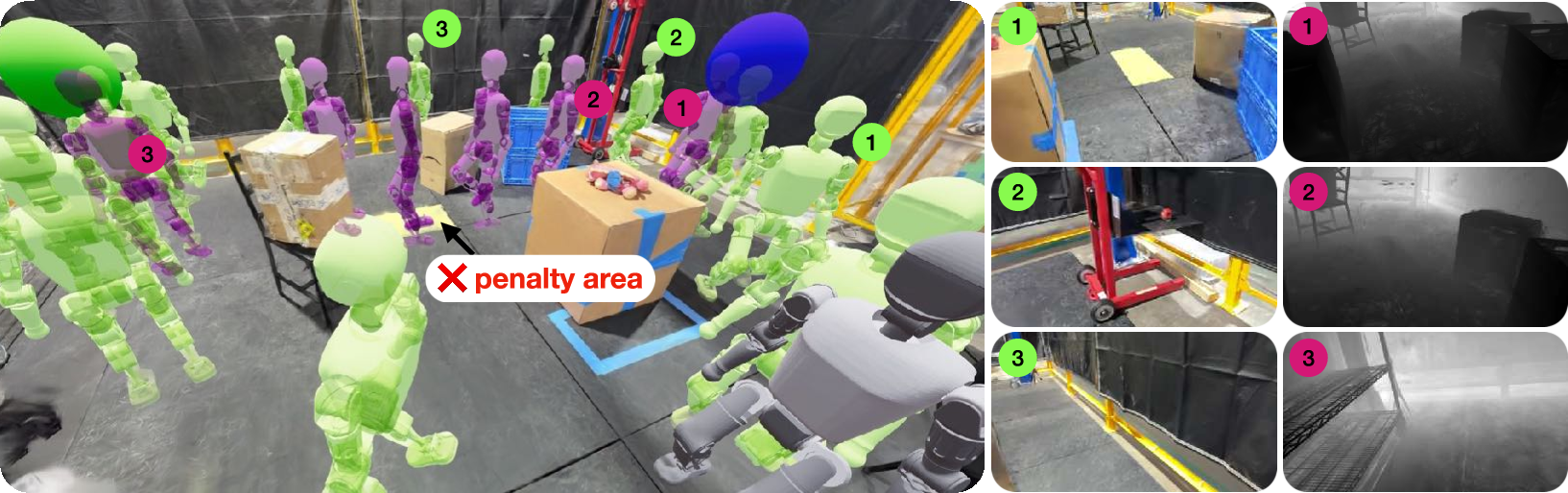
- Seeing beats depth-only in some tasks: In a navigation test, the RGB policy learned to avoid a yellow “penalty” floor area—even though a depth-only policy could not detect it. This shows camera images carry semantic clues (like colors and textures) that pure geometry (depth) misses.
Why does this matter?
- Faster progress on vision-based robotics: Training robots to “see” and move based on camera images is closer to how humans and animals operate. GaussGym makes this feasible by combining speed with realistic visuals.
- Scalable world creation: You can train in thousands of real or AI-made scenes—caves, disaster zones, alien-like terrains—without needing to physically visit them. That means safer, cheaper, and more diverse training.
- Better decisions from semantics: RGB lets robots recognize meaningful visual cues (like crosswalks or puddles), which depth alone can’t provide. That opens doors to more complex tasks and safer navigation.
- A shared, open platform: Because it’s open-source with code and data, the community can build on it—improving sim-to-real transfer, adding richer physics (like slippery surfaces), and exploring new tasks.
In short, GaussGym bridges the gap between fast, large-scale simulation and high-quality, realistic vision. It’s a step toward robots that learn from what they see and carry those skills from virtual worlds into the real one.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
Simulation fidelity and rendering
- Quantify the visual fidelity of 3D Gaussian Splatting in GaussGym (e.g., PSNR, SSIM, LPIPS) and correlate it with downstream RL performance and sim-to-real transfer.
- Measure and reduce alignment error between splat-rendered visuals and collision meshes (NKSR): define metrics for mesh–splat co-registration, test on thin structures, and evaluate impact on contact accuracy (e.g., foot placement).
- Extend the renderer to handle materials that 3DGS struggles with (specular, transparent, reflective surfaces) or integrate PBR meshes; assess how material realism affects perception-driven policies.
- Replace the current motion-blur approximation with a more complete camera model (rolling shutter, exposure, lens distortion, sensor noise, HDR), validate against real camera data, and study its effect on sim-to-real transfer.
- Evaluate robustness to lighting variation: introduce dynamic illumination, shadows, and appearance randomization during training and quantify transfer gains.
Data generation and scaling
- Establish a reliable metric-scale estimation pipeline for generative video scenes (e.g., object priors, text constraints, or learned scale estimators) and quantify errors; evaluate how scale misestimation impacts locomotion success.
- Systematically assess the reliability of VGGT outputs across diverse inputs (smartphone scans, ARKit, GrandTour, Veo), documenting failure modes, success rates, and required manual interventions.
- Provide end-to-end profiling of the scene ingestion pipeline at scale (compute time, memory footprint, storage, failure rates) for 2,500+ scenes; identify bottlenecks and optimization opportunities.
- Develop automatic filters and quality metrics for video-model–generated environments (multi-view consistency, temporal coherence, texture realism) and study their effect on policy learning.
- Create standardized benchmarks with ground-truth semantics and physics (e.g., friction labels, deformability) to evaluate perception-driven locomotion across captured and generated scenes.
Physics realism and appearance-to-physics coupling
- Replace uniform physical parameters (e.g., friction) with appearance-conditioned physics: learn or estimate surface properties (friction, compliance, stiffness) from RGB, and quantify gains in transfer.
- Introduce and validate physics for non-rigid phenomena (fluids, deformables, granular media like sand/mud) and dynamic objects; measure the impact on navigation and footfall planning.
- Define procedures to validate collision mesh watertightness, small obstacle fidelity, and contact stability; evaluate how mesh defects degrade locomotion.
Policy learning and generalization
- Compare the proposed LSTM+DINO approach to efficient transformer variants and hybrid temporal encoders under on-robot constraints (latency, compute, energy); report quantitative trade-offs.
- Test multi-modal input policies (RGB+depth/LiDAR/IMU) against RGB-only; run ablations on sensor fusion strategies and quantify improvements in generalization and safety.
- Replace or augment the voxel reconstruction auxiliary loss with self-supervised geometry objectives that are available in real deployments (e.g., monocular depth, optical flow); evaluate benefits for transfer without ground-truth meshes.
- Quantify required memory horizon for geometry inference (e.g., LSTM sequence length) and its impact on stability and sample efficiency.
- Provide training-time and sample-efficiency comparisons versus depth-only baselines across multiple tasks and scene diversities; report compute-to-performance curves.
Sim-to-real transfer and sensing
- Model and inject realistic sensor and system delays into simulation (camera latency, time synchronization, rolling shutter), then measure transfer gains; analyze failure cases related to latency.
- Evaluate generalization to truly unseen environments and assets in the real world (novel stair geometries, outdoor terrains, varying textures and lighting) with quantitative success metrics and error analyses.
- Study robustness to camera viewpoint changes (e.g., head-mounted vs chest-mounted), FOV differences, occlusions by robot limbs, and calibration errors; develop adaptive policies or calibration-aware training.
- Investigate domain randomization and domain adaptation strategies beyond motion blur (appearance perturbations, feature alignment) and quantify their effect on zero-shot transfer.
- Establish safety evaluation protocols for deploying pixel-only policies: define fail-safes, anomaly detection, and fallback behaviors; measure real-world safety outcomes.
Semantics, rewards, and tasks
- Automate the construction of semantic cost/reward functions (e.g., via LLMs, segmentation, or scene graphs) and evaluate how semantic shaping improves policy behavior in social contexts (sidewalks, crosswalks).
- Expand beyond stair climbing and sparse goal tracking to long-horizon, socially compliant navigation with moving obstacles (people, vehicles); quantify semantic reasoning and adherence to norms.
- Assess the limits of RGB semantic reasoning by varying visual cues (colors, textures) and introducing distractors; evaluate invariance and failure modes.
Systems, scalability, and reproducibility
- Report multi-GPU scaling characteristics, memory usage, bandwidth constraints, and reproducibility across different hardware (consumer vs datacenter GPUs); provide guidelines for balancing resolution, number of environments, and training stability.
- Document end-to-end robot-side inference latency, CPU/GPU utilization, and energy consumption for the proposed policy; verify feasibility at high control rates (>100 Hz).
- Provide standardized procedures and metrics for scene curation, dataset coverage, and bias analysis (indoor/outdoor, materials, lighting, texture diversity), enabling fair cross-paper comparisons.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s released tools and methods, given the specified assumptions and dependencies.
- Sector: Robotics (legged locomotion)
- Use case: Train RGB-based locomotion policies (e.g., stair climbing, slope traversal) for quadrupeds and humanoids that leverage visual semantics rather than depth-only inputs.
- Tools/workflows: GaussGym + IsaacGym; scene capture via smartphone; processing with VGGT and NKSR; training with the DINO-based LSTM encoder and auxiliary voxel reconstruction head; zero-shot deployment to robots like Unitree A1.
- Assumptions/dependencies: Static scenes; uniform friction in assets; camera latency on hardware; GPU availability (e.g., RTX 4090) for high-throughput training.
- Sector: Robotics (navigation)
- Use case: Train semantic-aware navigation policies that avoid visually indicated “no-go” regions (e.g., hazard colors, signage) invisible to depth-only policies.
- Tools/workflows: GaussGym semantic region setup; penalty-cost shaping; RGB policy training; evaluation in cluttered obstacle fields.
- Assumptions/dependencies: Reliable mapping between visual cues and training rewards; consistent scene lighting and textures to maintain semantic recognizability.
- Sector: Industrial operations (digital twins)
- Use case: Rapid photorealistic digital twins of warehouses, plants, and job sites from smartphone scans for pre-deployment route testing and controller tuning.
- Tools/workflows: iPhone/ARKit capture → VGGT → NKSR mesh + 3DGS asset alignment → GaussGym simulation of physics + synchronized RGB.
- Assumptions/dependencies: Accurate pose/intrinsic estimation; good SLAM coverage; predominantly static layouts; adequate collision mesh fidelity.
- Sector: Academia (benchmarks and reproducibility)
- Use case: A standardized platform to benchmark visual sim-to-real locomotion and navigation, compare architectures (e.g., voxel auxiliary head), and modalities (RGB vs depth).
- Tools/workflows: Public release of GaussGym code/data; large-scale vectorized training and ablations; standardized rewards/observations.
- Assumptions/dependencies: Access to modern GPUs; consistent evaluation protocols; adherence to dataset licenses (ARKitScenes, GrandTour).
- Sector: Software/simulation (renderer integration)
- Use case: Drop-in replacement of raytracing with 3D Gaussian Splatting to boost visual fidelity and FPS in vectorized physics simulators.
- Tools/workflows: PyTorch-based multi-threaded splat kernels; synchronized RGB/depth outputs; decoupled camera/control rates; motion-blur rendering.
- Assumptions/dependencies: Scenes reconstructed as 3DGS; static photorealistic assets; simulator compatibility with the rendering pipeline.
- Sector: Robotics operations (pre-deployment validation)
- Use case: Site-specific traverse risk assessment and foot-placement validation before rolling robots into customer environments.
- Tools/workflows: Scan → reconstruct → train/test policies in the digital twin; analyze failure cases and adjust control parameters or gaits.
- Assumptions/dependencies: Contact physics approximations (rigid bodies); limited modeling of fluids/deformables; potential friction mismatch.
- Sector: Education (visuomotor RL)
- Use case: Teaching end-to-end learning from pixels with hands-on labs (stair climbing, obstacle avoidance) using high-throughput photorealistic simulation.
- Tools/workflows: GaussGym scenes; simple reward shaping; DINO-based encoders; small-scale runs for lower compute budgets.
- Assumptions/dependencies: Classroom access to GPUs or scaled-down env counts; curated scenes to fit course timelines.
- Sector: Safety assurance (policy auditing)
- Use case: Evaluate whether RGB policies adhere to visual rules (e.g., avoiding hazard markings) pre-deployment as part of safety checks.
- Tools/workflows: Semantic patches and penalties; scenario libraries with visually indicated constraints; quantitative policy audit reports.
- Assumptions/dependencies: Repeatable visual semantics; domain-consistent textures; appropriate pass/fail thresholds.
- Sector: Data engineering (scene ingestion)
- Use case: Convert public datasets (ARKitScenes, GrandTour) into training worlds to improve robustness via diverse, photorealistic environments.
- Tools/workflows: VGGT for camera/point clouds; NKSR for meshes; 3DGS init from point clouds; automatic alignment in gravity-aligned frames.
- Assumptions/dependencies: Dataset licensing and attributions; scene variability; scalable data preprocessing pipelines.
- Sector: Embedded software (on-robot inference)
- Use case: Deploy compact LSTM-based visuomotor policies with precomputed DINO embeddings for faster inference on constrained compute.
- Tools/workflows: Decoupled camera/control frequencies; quantization/pruning; reduced-resolution rendering if needed.
- Assumptions/dependencies: Latency budgets; synchronization between camera and control loops; robustness to onboard sensor noise.
Long-Term Applications
These applications are promising but require additional research, scaling, or new capabilities (e.g., better generative models, dynamic scene physics).
- Sector: Robotics/Software (cloud simulation services)
- Use case: GaussGym-as-a-Service for enterprise-scale dataset creation and policy training across thousands of photorealistic worlds.
- Tools/products: Managed distributed multi-GPU training; asset ingestion pipelines; compliance-ready experiment tracking.
- Assumptions/dependencies: Scalable orchestration; data privacy/security; cost controls; standardized evaluation suites.
- Sector: Generative AI (text-to-world curricula)
- Use case: Automatically generate training curricula by integrating temporally consistent, controllable world models (e.g., Genie 3) to cover edge cases.
- Tools/products: Prompt-to-world pipelines; camera path scripting; semantic goal auto-generation; curriculum schedulers.
- Assumptions/dependencies: Stable multi-view consistency; controllable camera geometry; realistic physics proxies for generated assets.
- Sector: Robotics (generalized sim-to-real transfer)
- Use case: Robust transfer across unseen terrains, dynamic obstacles, and varying material properties for field deployment.
- Tools/products: Domain randomization over visuals and physics; friction/compliance estimation; dynamic scene modeling.
- Assumptions/dependencies: Enhanced physics (deformables, fluids); better sensing latency compensation; richer contact models.
- Sector: Healthcare (exoskeletons and rehab robotics)
- Use case: Train pixel-driven controllers and evaluate safety across patient-specific, photorealistic home/clinic environments.
- Tools/products: Patient-scanned digital twins; physiologically grounded simulation; clinical validation frameworks.
- Assumptions/dependencies: Accurate human–robot interaction models; regulatory approvals; rigorous safety testing.
- Sector: Public policy (standards and certification)
- Use case: Define and test requirements for semantic safety compliance (e.g., obeying crosswalks, avoiding hazard signage) before public deployment.
- Tools/products: Standardized GaussGym test batteries; visual-semantic metrics; certification procedures.
- Assumptions/dependencies: Regulator buy-in; consensus on semantic cues; repeatability across lighting/appearance variations.
- Sector: Autonomous driving/drones
- Use case: Photorealistic visual policy training in large-scale 3DGS-rendered environments (indoor micro-UAVs, campus carts).
- Tools/products: City-scale splat scenes; aerial dynamics integration; scenario libraries for navigation/avoidance.
- Assumptions/dependencies: Adequate physics for non-contact motion (aero/vehicle dynamics); dynamic agents; weather/lighting models.
- Sector: Energy/mining/disaster response
- Use case: Prepare robots for rare and hard-to-capture terrains (caves, offshore, post-disaster) synthesized via video models and curated datasets.
- Tools/products: Hazard-rich scene banks; risk-aware curricula; transferability checks to rugged hardware.
- Assumptions/dependencies: Reliable generative assets; handling severe domain shifts; ruggedization.
- Sector: Material property inference (look-and-feel coupling)
- Use case: Predict friction/compliance from RGB to set simulation parameters or adjust control online for safer footing.
- Tools/products: Visual-to-physics estimators; policy conditioning on inferred material properties.
- Assumptions/dependencies: Ground-truth contact property datasets; validated mappings from appearance to physics; sensor fusion.
- Sector: Tooling (LLM-driven reward and cost shaping)
- Use case: Automate task specification and semantic constraints via LLMs to reduce manual reward engineering.
- Tools/products: Prompt-to-reward compilers; interpretable constraint graphs; safety guardrails.
- Assumptions/dependencies: Trustworthy mappings; human-in-the-loop validation; prevention of reward hacking.
- Sector: Multi-agent systems (fleet training)
- Use case: Train coordinated fleets to share semantic cues and navigate collaboratively in photorealistic environments.
- Tools/products: Scalable vectorization beyond 4,096 envs; communication and coordination policies; shared map modules.
- Assumptions/dependencies: Distributed training stability; inter-robot communication models; scene diversity and curriculum design.
Glossary
- Affordances: Action possibilities offered by the environment that an agent can exploit for interaction or navigation. "Many such obstacles and environment affordances are only detectable through visual observations"
- Alpha-blending: A compositing technique that blends multiple images using their transparency (alpha) values to produce effects like motion blur. "alpha-blending them into a single image"
- Asymmetric actor-critic: A reinforcement learning setup where the actor and critic receive different observations (e.g., the critic can use privileged information) to improve training. "We specifically choose to use an asymmetric actor-critic framework to learn from visual input"
- Collision mesh: A geometric mesh used by physics simulators to detect and handle collisions. "used to estimate the scene collision mesh."
- ControlNet diffusion model: A diffusion model variant conditioned on structured inputs (e.g., depth, masks) to control image generation. "it employs a ControlNet diffusion model to generate visual training data from depth maps and semantic masks"
- Differentiable collision representation: A scene encoding that allows gradients to be computed through collision queries, enabling optimization and learning. "as a differentiable collision representation"
- Differentiable rendering: Rendering processes whose outputs are differentiable with respect to scene parameters, enabling gradient-based optimization for reconstruction or learning. "builds on advances in 3D reconstruction and differentiable rendering"
- DinoV2: A self-supervised vision transformer whose embeddings capture rich visual features for downstream tasks. "proprioceptive measurements are concatenated with DinoV2 \citep{oquab2023dinov2} embeddings extracted from the raw RGB frame."
- Egocentric observations: Sensor measurements captured from the agent’s own viewpoint, typically head- or body-mounted cameras and sensors. "including physical delays (e.g., image latency) and the reliance on egocentric observations."
- Elevation map: A 2D grid representation encoding terrain height at each cell, used for geometric navigation. "restricted to geometric (e.g., depth, elevation maps) and proprioceptive inputs."
- Extrinsics: Camera pose parameters (position and orientation) relative to a world or reference frame. "to obtain extrinsics, intrinsics, and point clouds with normals."
- Gaussian splats: Oriented 3D Gaussian primitives used to represent and render radiance fields efficiently. "Gaussian splats are initialized directly from VGGT point clouds"
- Gaussian Splatting (3DGS): A scene representation that uses collections of oriented 3D Gaussians rasterized to produce photorealistic views at high speed. "Implicit learned scene representations, such as 3D Gaussian Splatting (3DGS)"
- Generative video models: Models that synthesize video from text or other inputs, often exhibiting multi-view consistency. "even outputs from generative video models like Veo"
- GPU-accelerated simulators: Simulation frameworks that leverage GPUs for parallel physics and rendering, enabling high throughput. "the advent of GPU-accelerated simulators has democratized RL training by leveraging consumer-grade hardware for simulation."
- Gravity-aligned reference frame: A coordinate frame whose vertical axis is aligned with the direction of gravity. "formatted into a common gravity-aligned reference frame before processing."
- Heightmap: An image representing surface heights, commonly used to describe terrain geometry. "rather than rely on provided heightmaps or depth images."
- Intrinsics: Camera internal parameters (e.g., focal length, principal point) defining how 3D points project to the image. "to obtain extrinsics, intrinsics, and point clouds with normals."
- LSTM: Long Short-Term Memory network, a recurrent model that captures temporal dependencies via gated memory cells. "An LSTM encoder fuses proprioception with DinoV2 RGB features."
- Motion blur: Image blur caused by relative motion during exposure, often simulated for realism in rendering. "simulate motion blur: rendering a small set of frames offset along the camera’s velocity direction"
- Neural Kernel Surface Reconstruction (NKSR): A neural method that reconstructs high-quality surfaces from point clouds using kernel-based learning. "a Neural Kernel Surface Reconstruction (NKSR)~\citep{huang2023nksr} is used to produce high-quality meshes"
- Neural Radiance Field (NeRF): A neural volumetric representation that encodes scene radiance and density for photorealistic novel view synthesis. "Neural Radiance Fields (NeRFs)~\citep{mildenhall2020nerf} are an attractive representation for high quality scene reconstruction from posed images"
- Occupancy: A volumetric estimate indicating whether space is filled or free, often predicted as a dense grid. "a dense volumetric prediction of occupancy and terrain heights."
- Photorealistic rendering: Image synthesis that closely matches the appearance of real-world photographs. "accurate physics, and photorealistic rendering."
- Point cloud: A set of 3D points representing sampled geometry of a scene or object. "dense point clouds, and normals."
- Proprioception: Internal sensing of a robot’s state (e.g., joint positions, velocities), used for control and perception. "An LSTM encoder fuses proprioception with DinoV2 RGB features."
- Rasterization: A rendering technique that converts geometric primitives into pixels on a grid, typically faster than raytracing. "Unlike traditional raytracing or rasterization pipelines"
- Raytracing: A rendering technique that simulates light paths (rays) to generate images with high physical accuracy. "Unlike traditional raytracing or rasterization pipelines"
- Recurrent encoder: A sequence-processing network that encodes time-varying inputs into latent representations. "At the core of our framework is a recurrent encoder that fuses visual and proprioceptive streams over time."
- Sim-to-real: Transferring policies or models trained in simulation to real-world systems without or with minimal adaptation. "sim-to-real~\citep{hwangbo2019learning} reinforcement learning (RL)"
- SLAM: Simultaneous Localization and Mapping; algorithms that estimate a map and the agent’s pose within it from sensor data. "fully sensorized SLAM captures"
- Transposed convolution: A learnable upsampling operation used to increase spatial resolution of feature maps. "processed by a 3D transposed convolutional network."
- Unified Robot Description Format (URDF): An XML-based format for specifying a robot’s kinematics, geometry, and actuation. "predict an object's Unified Robot Description Format (URDF), including its actuation, from a single image"
- Vectorized physics simulators: Simulators that run many environments in parallel batches on accelerators for high throughput. "within vectorized physics simulators such as IsaacGym."
- Visually Grounded Geometry Transformer (VGGT): A model that estimates camera parameters and dense geometry (point clouds, normals) from images. "Visually Grounded Geometry Transformer (VGGT) ~\citep{wang2025vggt}, which estimates camera intrinsics, extrinsics, dense point clouds, and normals."
- Voxel: A volumetric pixel representing a value in a 3D grid, used for occupancy or geometry prediction. "Voxel prediction head: The latent vector is unflattened into a coarse 3D grid"
- Zero-shot transfer: Deploying a model to a new domain or real hardware without additional fine-tuning. "initial zero-shot transfer of visual locomotion policies trained in GaussGym to real-world stair climbing"
Collections
Sign up for free to add this paper to one or more collections.