Agentic Design of Compositional Machines
Abstract: The design of complex machines stands as both a marker of human intelligence and a foundation of engineering practice. Given recent advances in LLMs, we ask whether they, too, can learn to create. We approach this question through the lens of compositional machine design: a task in which machines are assembled from standardized components to meet functional demands like locomotion or manipulation in a simulated physical environment. To support this investigation, we introduce BesiegeField, a testbed built on the machine-building game Besiege, which enables part-based construction, physical simulation and reward-driven evaluation. Using BesiegeField, we benchmark state-of-the-art LLMs with agentic workflows and identify key capabilities required for success, including spatial reasoning, strategic assembly, and instruction-following. As current open-source models fall short, we explore reinforcement learning (RL) as a path to improvement: we curate a cold-start dataset, conduct RL finetuning experiments, and highlight open challenges at the intersection of language, machine design, and physical reasoning.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-Language Summary: Agentic Design of Compositional Machines
What is this paper about?
This paper asks a big, fun question: can AI not just talk, but actually design working machines from parts—like building a car or a catapult out of LEGO—so that they move and do useful things? To study this, the authors built a test world called BesiegeField (based on the game Besiege) where an AI can assemble parts, run a physics simulation, and get a score for how well its machine works. Then they tested different LLMs and training methods to see how good they are at this kind of “creative engineering.”
What questions did the researchers ask?
- Can LLMs design working machines by choosing and arranging parts in 3D space?
- What skills do LLMs need to succeed (like spatial reasoning, following instructions, and planning)?
- How far can we get with clever AI “workflows” (plan → build → test → improve)?
- Can reinforcement learning (letting the AI learn from scores/feedback) make open-source models much better?
How did they study it?
They set up a simple but realistic playground for machine design:
- BesiegeField environment: Think of a builder’s workshop inside a physics game. The AI can pick parts (like blocks, wheels, gears, springs), attach them together, and then press “play” to see how the machine behaves. The physics are realistic: gravity, collisions, and parts can even break.
- Two starter challenges:
- Car: Make a machine that drives forward as far as possible.
- Catapult: Make a machine that throws a boulder as far as possible.
- Clear scoring: The AI gets a reward based on performance (e.g., distance driven or stone thrown). For catapults, they reward both how high and how far the stone flies so it doesn’t “cheat” by only going straight up or only skimming the ground.
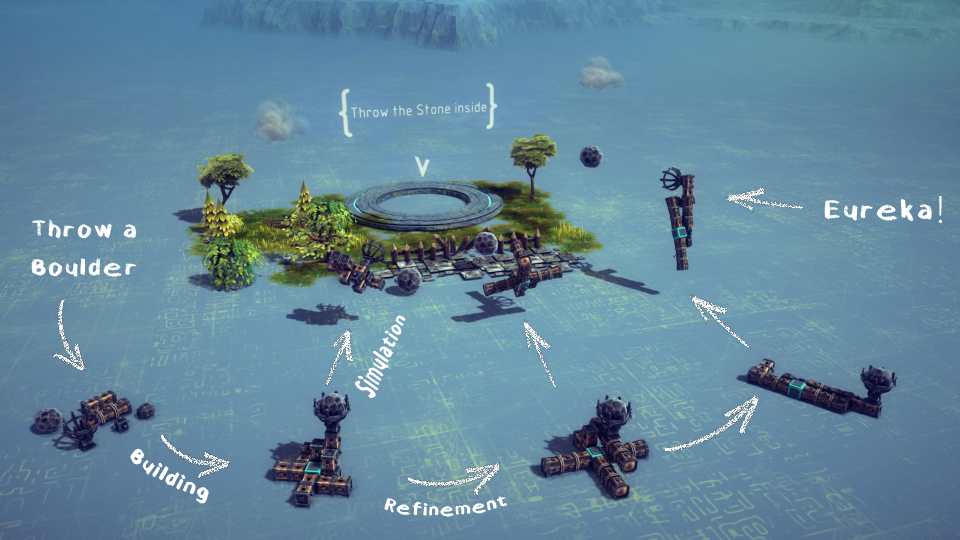
- Smart machine “blueprints”: Instead of just storing where every piece sits in space (like a photo), they record “who is attached to whom and how” (like LEGO instructions). This structure—called a construction tree—helps the AI reason about designs better.
- Agentic workflows: The AI acts like a designer that can:
- Plan (write down a design idea in steps),
- Build (turn the plan into a part-by-part machine),
- Test (run the simulation and read results),
- Improve (edit the design and try again).
- They tried:
- Single-agent: one AI does everything in one shot.
- Iterative editing: the AI designs, tests, critiques itself, and revises multiple times. Sometimes it makes multiple versions and keeps the best (like trying many prototypes).
- Hierarchical construction: first sketch a high-level blueprint (e.g., “frame + wheels + steering”), then build each piece step by step. This is like how people design: from big picture to details.
- Helpful tools explained simply:
- Chain-of-Thought (CoT): the AI writes out its reasoning like a scratchpad before building.
- Monte Carlo Tree Search (MCTS): try many small changes, keep the promising directions—like exploring branches of ideas and choosing the best path.
- Reinforcement learning (RL): They also trained an open-source model to improve by practice. The model builds a machine, gets a score, and adjusts its behavior to do better next time. They “cold-started” it with a small dataset of working examples (about 10k designs) and then used RL to push performance further. A trick called Pass@k rewards the best of several attempts in each training step, making it more likely to discover better designs.
What did they find, and why is it important?
- Building real machines is hard for today’s LLMs—but not impossible.
- Stronger models (like Gemini 2.5 Pro) can build sensible cars and sometimes working catapults.
- Many open-source models struggle with 3D understanding and precise part placement.
- The way you represent the machine matters a lot.
- Designs described as a construction tree (which part attaches to which face, and how it’s rotated) work better than a simple “just coordinates” format. It’s the difference between having assembly instructions vs. just a picture.
- Helpful feedback makes better machines.
- When the AI sees more details from the simulation (like which parts broke or how fast wheels spin), it improves its designs faster.
- Common mistakes the AI makes:
- Parts facing the wrong way (a gear or wheel flipped).
- Attaching pieces to the wrong spots (like putting wheels on the wrong beam).
- Not following its own plan exactly during building.
- Misunderstanding physics (e.g., forgetting a counterweight for a catapult).
- Good planning helps—if it’s carried out faithfully.
- Writing down a clear chain-of-thought improves high-level design.
- Hierarchical design (big plan → detailed build) helps if the big plan is solid. If not, the structure doesn’t save the day.
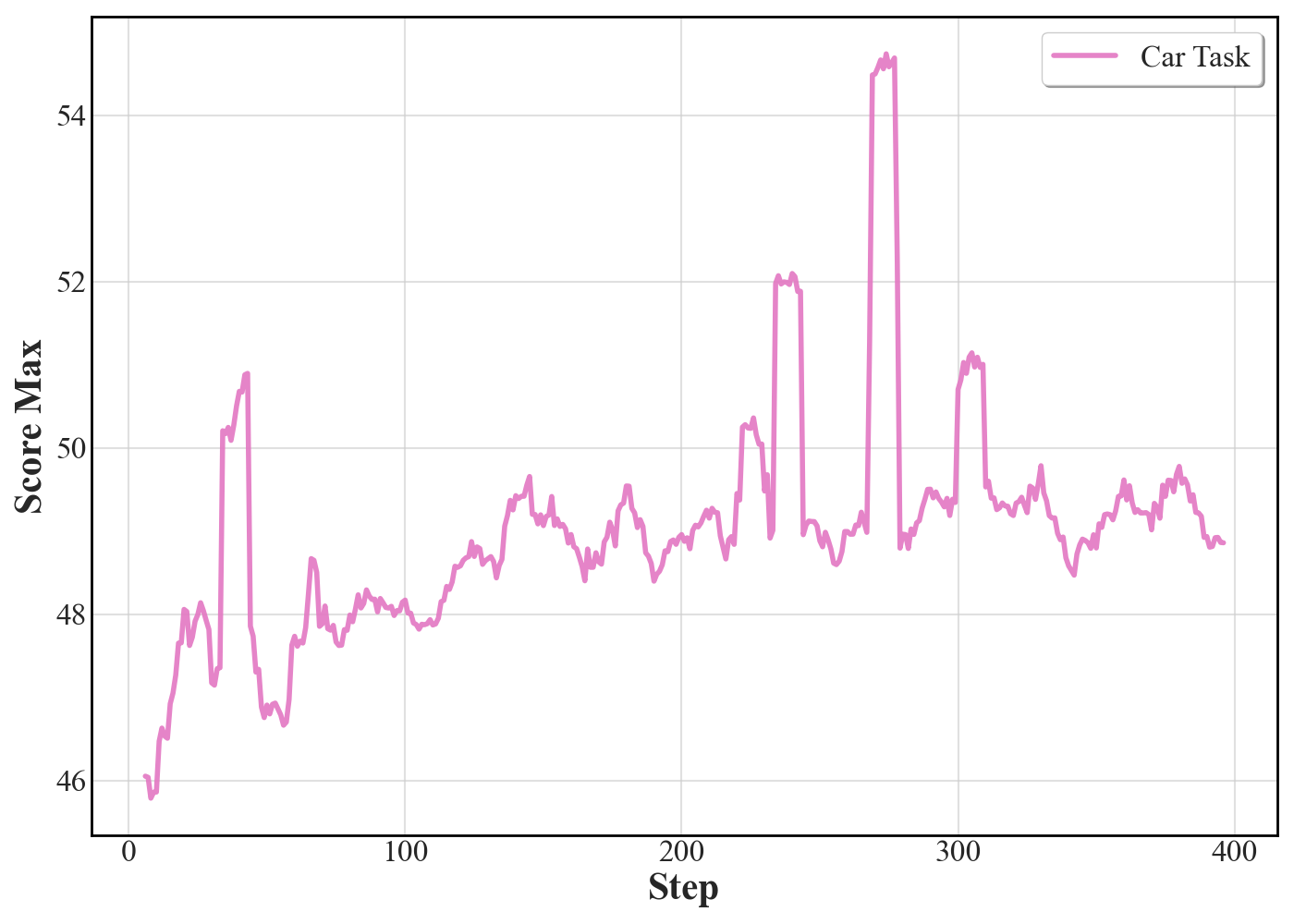
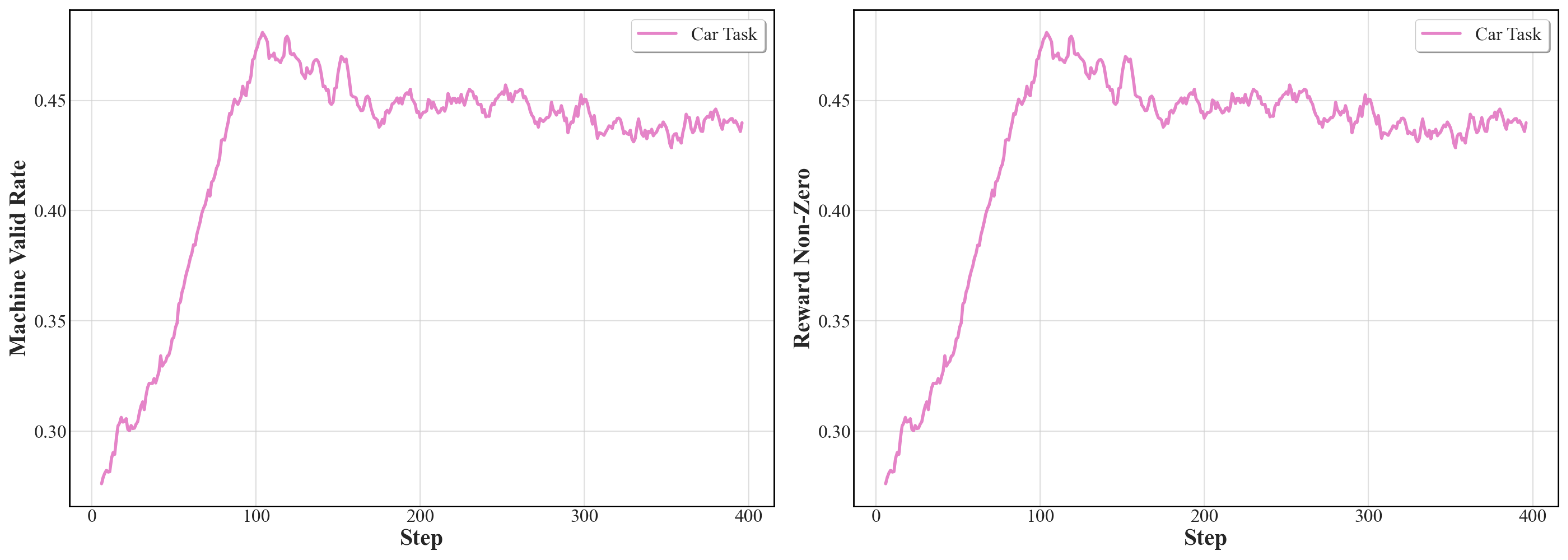
- Reinforcement learning helps open-source models, but it’s a modest boost.
- RL increased how often designs were valid and sometimes improved the best scores.
- Pass@k training (rewarding the best of several tries) was better at discovering strong designs.
- However, models often “stick” to one idea and just tweak it, rather than exploring truly different strategies—so more work is needed to keep designs diverse.
Why does this research matter?
- A step toward AI-assisted engineering: Imagine AI co-designers that can draft, test, and refine machines—saving human engineers time and discovering fresh ideas.
- New skills for AIs: This task pushes AIs to combine language, 3D spatial reasoning, physics understanding, and careful instruction-following. These are key for real-world design.
- Better tools and training: The study shows that:
- Structured representations (like construction trees) are crucial.
- Agentic workflows (plan → build → test → improve) beat “one-shot” answers.
- RL with clear, automatic scores (verifiable rewards) can grow practical design skills.
- What’s next: To design more complex machines, future AIs will likely need richer multimodal inputs (text + diagrams), stronger spatial reasoning, better exploration (so they try truly different ideas), and the ability to keep learning over time without forgetting past skills.
In short, this paper builds a realistic playground for machine design, tests how far today’s AIs can go, and shows a promising path—using thoughtful workflows and reinforcement learning—toward AIs that can truly invent and improve machines.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed so future researchers can act on it:
- Task scope is narrow: only two machine types (car and catapult), single-task prompts, and a short 5-second evaluation horizon. It is unclear how methods scale to more complex, multi-functional machines (e.g., articulated walkers, cranes, multi-stage gear trains) or longer-horizon behaviors and tasks.
- No co-design of structure and control: machines are evaluated under a fixed/shared control policy and simple activation timing. Many mechanisms require nontrivial, time-dependent control. How to jointly optimize topology, geometry, and control policies remains open.
- Physics and constraints are simplified: the setup omits material properties, manufacturing tolerances, frictional nuances, fatigue, failure modes beyond “destruction,” and real-world constraints (safety, regulations). Extending to richer physics (fluid-structure interaction, compliant elements), material models, and durability criteria is not addressed.
- Sim-to-real gap is unexamined: designs are validated only in Besiege-based simulation. There is no assessment of transferability to other simulators or physical prototypes, nor strategies to reduce sim-to-real discrepancies (e.g., domain randomization, ensemble simulators).
- Benchmark diversity and metrics are limited: performance is measured mainly by mean/max distance/height; there is no explicit evaluation of diversity, novelty, robustness, or multi-objective trade-offs (e.g., energy efficiency, weight, stability margins, safety).
- Reward design is ad hoc and brittle: simple distance/height rewards (with walls to deter hacking) may not capture design quality. Systematic reward shaping, constraint enforcement, and verifiable multi-objective evaluation (including robustness to disturbances and repeated trials) are missing.
- Environment feedback is coarse and short-horizon: only a small subset of telemetry over 5 seconds is fed back. How to select and summarize richer, longer-horizon state to best guide design refinement is not studied.
- Representation choices are underexplored: the proposed construction-tree representation is shown superior to coordinate lists, but there is no assessment of richer symbolic formalisms (e.g., graph grammars, typed assembly grammars, constraint-based programs) or constrained decoding to guarantee validity and reduce common orientation/attachment errors.
- Plan-to-assembly misalignment persists: chain-of-thought often diverges from the produced construction tree. There is no dedicated mechanism to verify and enforce CoT-to-design consistency (e.g., schema/constraint checkers, program repair loops, executable design sketches).
- Lack of multimodal grounding: all reasoning is text-only even though design is inherently spatial. The impact of integrating diagrams, 3D previews, videos, or interactive viewers on spatial reasoning and accuracy is unexplored.
- Agentic pipeline design is not stress-tested: hierarchical and iterative workflows help only when blueprints are reliable; error accumulation across agents remains a bottleneck. There is no ablation of orchestration strategies, fault-tolerance, or coordination protocols to reduce cascading failures.
- Search strategy is limited: the paper briefly uses MCTS and sampling but lacks comparisons to classical design search (evolutionary algorithms, Bayesian optimization, MAP-Elites, quality-diversity methods) or more powerful program synthesis/search techniques.
- Generalization is untested: there is no evaluation on out-of-distribution tasks, different block sets, terrains, forces, or altered physics parameters; no transfer to novel objectives or cross-environment generalization.
- RL with verifiable rewards (RLVR) is preliminary: small-scale GRPO with LoRA yields modest gains and rapid entropy collapse. Diversity-preserving RL, curriculum learning, credit assignment over long action sequences, and sample efficiency are not addressed.
- Pass@k improves maxima but not exploration breadth: while pass@k boosts best-case scores, there is no analysis of its effect on design diversity, stability, and generalization; combining pass@k with explicit diversity objectives remains open.
- Cold-start data quality and bias are uncertain: the dataset (9,984 machine–CoT pairs) is generated by a proprietary LLM, risking bias and leakage. The coverage, licensing, and representativeness of functional strategies are not audited.
- Single-task RL specialization only: finetuning is done per machine type with a single prompt. Multi-task, meta-RL, or continual learning (avoiding catastrophic forgetting while expanding the design repertoire) are not explored.
- Context limitations and memory: edit history helps but is bounded by context window size. External memory, retrieval-augmented design libraries, or persistent design graphs for long-horizon refinement remain untested.
- No formal guarantees or constraints: there is no formal grammar or verifier to guarantee feasibility, safety, or constraint satisfaction (e.g., collision-free assembly, torque/clearance constraints). Formal methods for constraint-checking are missing.
- Computational cost and efficiency are opaque: simulation and search costs, throughput, and scaling behavior (with model size, context length, candidate budget) are not analyzed; caching, surrogate modeling, or differentiable approximations are absent.
- Differentiable or learned simulators are not leveraged: the work does not explore gradient-based improvements via differentiable physics or learned surrogates to accelerate and guide optimization.
- Human-in-the-loop is absent: there is no study of how designer feedback, preference learning, or interactive constraint editing could steer search and improve practicality.
- Safety and ethical considerations are not discussed: autonomous machine design poses risks (e.g., unsafe mechanisms, misuse). Governance, guardrails, and safe-design constraints are not formulated.
- Reproducibility and release details are unclear: the availability of BesiegeField plugins, datasets, seeds, and evaluation scripts is not specified; cross-lab reproducibility remains uncertain.
- Scaling laws and capability diagnostics are missing: there is no systematic study of how performance scales with model size, 3D-aware pretraining, multimodal inputs, search budget, or agent count, nor targeted diagnostics for spatial/physical reasoning deficits.
- Blueprint reliability remains an open bottleneck: hierarchical design helps only with accurate high-level decomposition. Methods to learn robust blueprints (e.g., supervised blueprint corpora, blueprint verifiers, or scaffolded subassembly tests) are not provided.
- Robustness analysis is limited: there is no testing under parameter noise, assembly perturbations, disturbances, or repeated trials to measure reliability, tolerance, and fault resilience.
- Lack of standardized benchmarks: broader, community-accepted tasks and metrics for compositional machine design—spanning functionality, efficiency, robustness, and diversity—are not proposed, hindering fair comparison and progress tracking.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed with current capabilities demonstrated in the paper, especially leveraging BesiegeField, agentic workflows, construction-tree machine representations, and RLVR finetuning templates.
- Educational sandbox for mechanical design (Education)
- Tools/Workflow: Use BesiegeField in engineering courses and labs to teach kinematics, linkages, gear trains, and control basics via task-oriented builds (e.g., cars, catapults) and reward-based evaluation.
- Assumptions/Dependencies: Physics fidelity suffices for conceptual learning; institutional access to BesiegeField; basic instructor preparation for agentic workflows.
- Benchmarking suite for spatial and physical reasoning in LLMs (Academia, AI Research)
- Tools/Workflow: Adopt BesiegeField and the construction-tree format to evaluate LLMs on file/spatial validity, simulation performance, CoT-to-machine alignment, and diversity under Pass@k RLVR.
- Assumptions/Dependencies: Standardized prompts, metrics, and open protocols; reproducible environment setups; community willingness to adopt the benchmark.
- Rapid early-stage ideation for simple mechanisms (Manufacturing, Consumer Products)
- Tools/Workflow: Use agentic LLM designers to generate diverse assemblies from standardized 3D part libraries; filter via physics-in-the-loop simulation to produce inspiration boards and candidate configurations.
- Assumptions/Dependencies: Mapping between Besiege-like parts and real off-the-shelf components; acceptance of low-fidelity simulation for ideation; human-in-the-loop triage.
- Low-fidelity CAD pre-visualization copilot (Software/CAD)
- Tools/Workflow: A plugin that converts textual functional requirements into construction-tree assemblies, providing pre-CAD sketches that can be imported or constrained in mainstream CAD tools.
- Assumptions/Dependencies: APIs to translate construction trees into CAD constraints; coverage of standard joints/fasteners; alignment with CAD tolerances is not guaranteed at this stage.
- Failure-mode exploration and durability testing in simulation (QA/Reliability)
- Tools/Workflow: Run stress scenarios with environment disturbances (e.g., walls, wind, gravity variations) to analyze part breakage and weak points; produce structured failure reports for design refinement.
- Assumptions/Dependencies: Adequate correspondence between simulated and real failure phenomena for qualitative insights; reward design avoids reward hacking.
- RLVR training template for domain-specific LLMs (AI/ML Ops)
- Tools/Workflow: Reuse GRPO + LoRA + Pass@k pipelines with verifiable rewards; leverage the cold-start dataset curation strategy from community designs to bootstrap domain-specific reasoning.
- Assumptions/Dependencies: Sufficient compute; licensing compliance for community data; safe RL hyperparameterization to mitigate entropy collapse.
- Design rationale capture and search (Engineering Management)
- Tools/Workflow: Store CoT traces alongside construction trees and simulation feedback to create a searchable design memory (what was tried, why, and what happened).
- Assumptions/Dependencies: Data governance and IP policies; ability to anonymize and standardize design logs; organizational buy-in.
- Multi-agent design process rehearsal (Operations/Team Training)
- Tools/Workflow: Simulate designer–inspector–refiner workflows with MCTS candidate selection to train teams on iterative design and critique practices.
- Assumptions/Dependencies: Minimal domain adaptation; training materials and scenarios; basic orchestration of agents in the workflow.
- Game/UGC content creation for physics-building titles (Gaming/Media)
- Tools/Workflow: Integrate LLM-generated machines into Besiege-like games to seed user content, scenarios, and challenges; offer iterative refinement via environment feedback.
- Assumptions/Dependencies: Modding APIs, community moderation, and licensing for generated content.
- Robotics education on mechanism and drivetrain fundamentals (Robotics)
- Tools/Workflow: Teach mechanical concepts (gear ratios, suspensions, arm linkages) in a safe simulator; optionally layer simple control policies to demonstrate behavior differences under control.
- Assumptions/Dependencies: Abstracted controls map to classroom learning goals; instructors provide context on the limits of simulation vs. hardware.
Long-Term Applications
These use cases require further research and development to increase fidelity, integrate with industrial ecosystems, and ensure safety, compliance, and scaling.
- Full-fledged agentic CAD copilot for mechanical assemblies (Software/CAD, PLM)
- Tools/Workflow: Integrated assistant that recommends parts, placements, constraints, materials, and tolerances; validates in high-fidelity multiphysics simulators; co-generates control policies; produces manufacturable drawings and BOMs.
- Assumptions/Dependencies: High-accuracy physics and material models; tight integration with CAD/CAE suites (e.g., SolidWorks, Fusion 360, Ansys); safety and regulatory compliance; robust CoT-to-spec translation.
- Automated mechanism synthesis for robotics subassemblies (Robotics, Automotive)
- Tools/Workflow: Agentic exploration of linkages, suspensions, grippers, gear trains; multi-objective optimization (precision, weight, power) with control-policy co-design and constraints (workspace, payload).
- Assumptions/Dependencies: Scalable search under constraints; closed-loop control and co-simulation; reliable manufacturability checks.
- Digital twin–driven continuous design improvement (Industrial IoT)
- Tools/Workflow: Use telemetry to update digital twins; RLVR-based agents propose design iterations; pass@k preserves solution diversity; automatically test against field conditions.
- Assumptions/Dependencies: Data pipelines for secure telemetry; simulator-model alignment; governance for deploying iterative design changes.
- Policy and standards for AI-generated mechanical designs (Policy/Regulation)
- Tools/Workflow: Develop verification, documentation, and liability frameworks; adopt assembly graph/construction-tree standards; require auditable CoT for design provenance and safety cases.
- Assumptions/Dependencies: Multi-stakeholder consensus; accredited verification tools; legal clarity on AI-generated IP and accountability.
- Procurement-aware design automation (Supply Chain)
- Tools/Workflow: Constrain designs to available catalogs; optimize cost, lead time, and performance; produce alternative designs that are robust to supply disruptions.
- Assumptions/Dependencies: Catalog APIs and continuously updated inventories; optimization under uncertainty; procurement policies.
- Safety-first automated certification pipelines (Aerospace, Medical Devices)
- Tools/Workflow: Combine formal verification, physics-in-the-loop testing, and hazard analysis; generate traceable compliance artifacts directly from AI-assisted designs.
- Assumptions/Dependencies: High-assurance simulators; domain-specific standards (e.g., DO-178C/DO-254 analogs for mechanical systems); rigorous validation data.
- Multimodal design assistants (Text + 2D drawings + 3D CAD + simulation) (Cross-sector)
- Tools/Workflow: Parse legacy blueprints and CAD; reconstruct assembly graphs; propose design improvements; simulate expected behavior; support visual-semantic dialogue.
- Assumptions/Dependencies: Robust perception for CAD and scans; large multimodal datasets; accurate mapping from legacy artifacts to parametric models.
- Large-scale design knowledge bases and retrieval (Knowledge Management)
- Tools/Workflow: Curate machine–CoT–simulation triplets; enable semantic search for design strategies, failure modes, and trade-offs; support transfer learning across domains.
- Assumptions/Dependencies: Data governance and privacy; IP licensing; effective indexing of structured assemblies and rationale.
- Cross-domain extension to EDA and building systems (EDA, Construction)
- Tools/Workflow: Apply compositional design and Pass@k RLVR to chip floorplanning/placement or HVAC/plumbing layouts under spatial constraints and verifiable simulators.
- Assumptions/Dependencies: Domain-specific simulators and constraints; adaptation of construction-tree analogs to nets and routes; new reward functions.
- Robot assembly planning from construction trees (Manufacturing Automation)
- Tools/Workflow: Convert assembly graphs into robot tasks: order of operations, fixturing, tool changes; verify with discrete-event simulations and physical checks.
- Assumptions/Dependencies: Accurate grasping/fixturing modeling; integration with MES/ERP; safety certification for human-robot collaboration.
- Energy device prototyping (Energy)
- Tools/Workflow: Design gearboxes, linkages, and mechanisms for wind/wave energy; simulate loads, fatigue, and maintenance regimes; iterate with RLVR under realistic environmental models.
- Assumptions/Dependencies: Advanced multiphysics (fluid–structure interaction); material fatigue modeling; site-specific environmental data.
- Marketplace and governance for AI-generated mechanical designs (Industry Platforms)
- Tools/Workflow: Host vetted AI-generated assemblies; attach verifiable performance badges and compliance reports; enable licensing and customization for SMEs.
- Assumptions/Dependencies: Platform trust and curation; standardized metadata; legal frameworks for distribution and modification.
Glossary
- Agentic workflow: A structured process where LLM-based agents iteratively plan, build, critique, and refine designs using environment feedback. "The figure shows a high-level sketch of the agentic workflow (w/ Gemini Pro 2.5), along with the resulting machines and their simulated performance."
- Autoregressive strategy: A sequential generation approach that constructs outputs step-by-step, with each step conditioned on previously generated elements. "we adopt an autoregressive strategy to build the machine block by block:"
- BesiegeField: A machine-design testbed built on the Besiege game, enabling part-based construction, physical simulation, and reward-based evaluation. "we introduce BesiegeField, a testbed built on the machine-building game Besiege, which enables part-based construction, physical simulation and reward-driven evaluation."
- Chain-of-thought (CoT): A reasoning technique where the model explicitly writes intermediate steps before producing a final answer or design. "The agent generates a chain-of-thought (CoT; \citet{wei2022chain}) to reason about what is needed and why, and then derives an abstract plan"
- Cold-start finetuning: Post-training used to initialize or adapt a model with a small curated dataset before further reinforcement learning. "Cold-start finetuning and dataset curation."
- Compositional machine design: The task of assembling standardized parts into machines whose structures and behaviors meet functional goals under physics. "We introduce and formalize the task of compositional machine design, where machines are assembled from standardized parts to achieve functional goals."
- Computer-aided design (CAD): Software-driven modeling used to create mechanical parts and detailed geometric designs. "foundation models are already capable of synthesizing 3D shapes and building mechanical parts with computer-aided design (CAD) models,"
- Construction tree representation: A structure-aligned encoding of machines using parent–child attachment relations and relative orientations between parts. "This plan is later translated into the construction tree representation."
- Elastic mechanics: The study of deformable-body behavior where materials can temporarily deform under forces and recover shape. "operate under a shared control policy in an environment governed by rigid-body and elastic mechanics."
- Electronic design automation (EDA): Tools and methods that automate chip layout and circuit design under spatial and connectivity constraints. "electronic design automation (EDA) for chip layouts requires spatial reasoning to place components of varying shapes under spatial constraints (albeit in a more regular and grid-constrained fashion than mechanical parts in machines)."
- Fly-by-wire: Electronic control systems that stabilize and control aircraft, replacing or augmenting direct mechanical linkages. "as exemplified by aircraft that rely on fly-by-wire systems to stabilize their inherently unstable aerodynamic configurations (which would otherwise be unflyable by a human pilot alone)."
- Generative flow networks: Distribution-matching training objectives that encourage diverse solution discovery by learning to sample from target distributions. "distribution-matching objectives like generative flow networks"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies using grouped, relative advantages among sampled outputs. "We adopt group relative policy optimization (GRPO; \citet{shao2024deepseekmath}) with LoRA parametrization (rank 64) and mixed-precision training to finetune the cold-started model."
- In-context learning: The ability of LLMs to adapt to new tasks using only information provided within the prompt, without weight updates. "limited 3D understanding and/or in-context learning."
- KL regularization: A penalty based on Kullback–Leibler divergence that constrains a finetuned model to stay close to its initialization. "We apply KL regularization with strength 0.001 to encourage the model to remain close to its initialization."
- LoRA parametrization: Low-Rank Adaptation, a parameter-efficient finetuning method that injects small trainable matrices into pretrained weights. "We adopt group relative policy optimization (GRPO; \citet{shao2024deepseekmath}) with LoRA parametrization (rank 64)"
- Machine validity rate: The proportion of generated machines that pass both file parsing and spatial collision checks. "machine validity rate, the proportion of machines that satisfy both file and spatial validity;"
- Meta-designer agent: A specialized agent that decomposes requirements into high-level blueprints of functional subsystems before lower-level construction. "we introduce a meta-designer agent that first analyzes the requirements and constraints, and then constructs a high-level blueprint of the major functional blocks"
- Monte Carlo Tree Search (MCTS): A heuristic search method that explores decision trees via randomized simulations and backpropagated statistics. "At refiner stages, multiple candidates are generated for running Monte Carlo tree search (MCTS; \citet{coulom2006efficient})."
- Pass@k advantage estimator: An RL training strategy that computes advantages using the best among k sampled outputs to encourage discovery of strong solutions. "our default setting adopts Pass@k advantage estimator."
- Reinforcement learning with verifiable rewards (RLVR): Finetuning models using reward signals produced by deterministic verifiers or simulators to ensure correctness. "We thus explore reinforcement learning with verifiable rewards (RLVR) in BesiegeField to develop machine-design capabilities."
- Rigid-body mechanics: The study of motion and interaction of solid bodies that do not deform under applied forces. "operate under a shared control policy in an environment governed by rigid-body and elastic mechanics."
- Spatial validity rate: The fraction of generated designs that are physically feasible in space (e.g., no self-collisions) prior to simulation. "spatial validity rate, the proportion of generated machines that are free from self-collisions;"
Collections
Sign up for free to add this paper to one or more collections.

