A Survey of Reinforcement Learning for Large Reasoning Models
Abstract: In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with LLMs. RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a big, friendly map of a fast‑growing area in AI: teaching LLMs to think better using reinforcement learning (RL). When RL is used to push LLMs beyond simple reply-giving and into real problem solving, the authors call them large reasoning models (LRMs). The paper explains how RL has recently boosted models’ skills in things like math, coding, planning, and step‑by‑step thinking, and it organizes the field so researchers know what works, what’s hard, and where to go next.
What questions does it ask?
In simple terms, the survey looks at:
- How do we turn a chatty AI into a careful, step‑by‑step reasoner?
- What kinds of “rewards” help models learn to reason (for example, checking if a math answer is correct)?
- Which training algorithms and sampling tricks work best?
- What data, environments, and tools are needed to scale RL to very large systems?
- Where is RL most useful today (coding, agents, multimodal vision-text tasks, robotics, medical) and what open problems still block progress?
How did the authors study this?
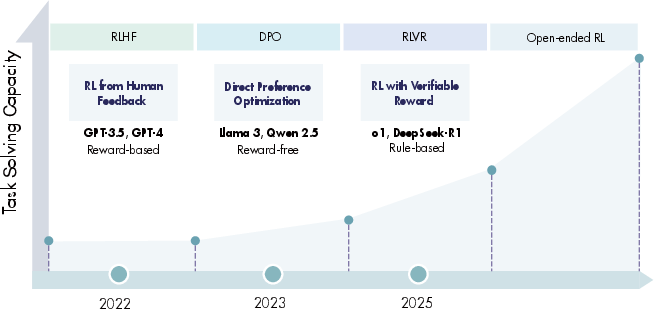
This is a survey paper. That means the authors didn’t run one big experiment; they read and organized many papers and systems, especially since famous releases like OpenAI’s o1 and DeepSeek-R1. They grouped the field into clear parts:
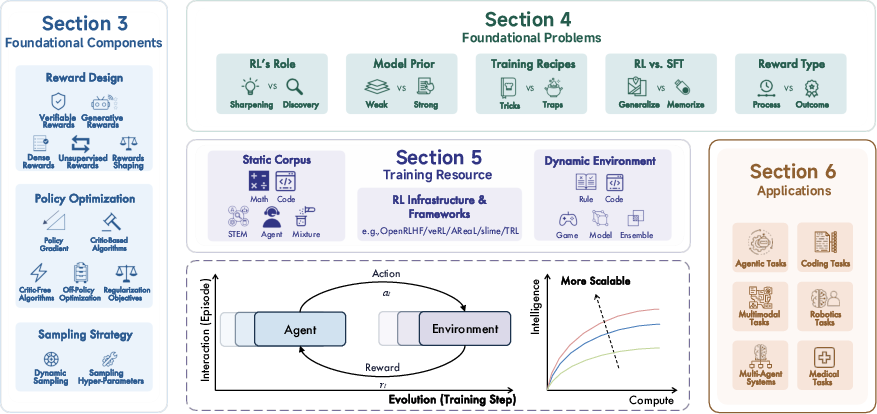
- Reward design: how to score a model’s answers so it knows what to improve.
- Policy optimization: the training methods that push the model toward higher rewards.
- Sampling strategies: smart ways to pick training examples and “thinking budgets” during training.
- Resources and applications: datasets, environments, infrastructure, and where RL is being used.
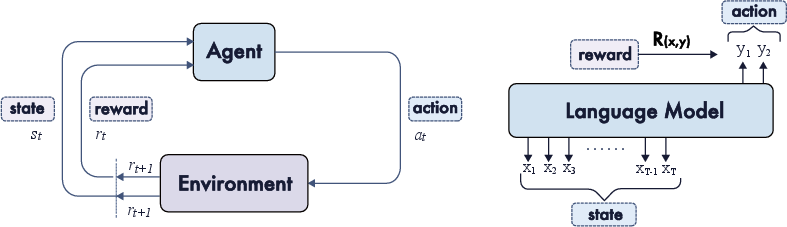
If RL sounds abstract, think of it like a video game: the model tries actions (writing text, solving steps), gets points (rewards) when it does well, and learns to choose better actions next time. The twist for reasoning is that “points” can come from an answer checker (like passing a unit test for code) or from a judge (a smaller model or rubric that scores the solution).
What did they find?
1) A simple, checkable reward can go a long way
- When a task has a clear right or wrong answer—like many math questions or coding problems—models can be trained with “verifiable rewards.” For example, math correctness or passing unit tests gives a reliable score. This makes RL training stable and scalable, and it’s a big reason models like o1 and DeepSeek‑R1 became strong reasoners.
- Key idea: if you can automatically check success, you can train efficiently. Tasks that are vague or subjective are harder because “what’s good” is less clear.
2) Different kinds of rewards serve different needs
The paper groups rewards into several types:
- Verifiable (rule‑based): direct checks like “is the final answer correct?” or “did the code pass the test?” Great for math/code.
- Generative: the model (or another model) acts as a judge, providing a score or feedback. This helps on tasks without a simple answer key, but you must avoid “reward hacking” (cheating the judge).
- Dense rewards: instead of scoring only the final answer, you score parts of the process—per token, per step, or per turn—like a teacher giving partial credit and hints along the way. This guides the model’s chain‑of‑thought.
- Unsupervised/self‑rewards: the model learns to set or estimate rewards by itself when no labels exist. Useful but tricky, because the model can learn to game its own rules.
- Reward shaping: combining, smoothing, or restructuring rewards (for example, encouraging good format, penalizing needlessly long answers, or using multiple small rewards) to make learning easier.
Analogy: Sometimes you grade only the final test (sparse reward). Sometimes you also grade homework steps and give rubrics (dense reward). Sometimes the student makes their own practice problems and answer keys (self‑reward), but you have to check they aren’t cheating.
3) Training methods: “critic‑based” vs “critic‑free”
- Critic‑based methods (like PPO) train a helper network (a “critic”) to estimate how good an action is. This can be stable but more complex.
- Critic‑free methods (like REINFORCE or GRPO) skip the critic and use clever tricks (baselines, group comparisons) to keep learning stable. These have become popular in large‑scale reasoning because they are simpler to run at huge scale.
- Regularization helps: keeping the trained model close to a reference model (KL penalty), encouraging healthy exploration (entropy), and balancing answer length (length penalties) stabilize training and keep outputs readable.
4) Sampling and “thinking time” matter
- Giving the model more “thinking time” at test time (letting it generate more intermediate steps) often improves results. This is like telling a student, “Take your time, show your work.”
- During training, dynamic sampling (choosing harder/easier problems at the right times, adjusting how many samples you draw, or changing temperatures) improves efficiency and skill growth.
5) Resources and applications are expanding fast
- Resources: The field now has static datasets (e.g., math/coding problems), dynamic environments (tools, simulators, websites), and training infrastructure for massive online RL runs.
- Applications:
- Coding (fixing bugs, passing benchmarks)
- Agentic tasks (using tools, browsing, planning multi‑step actions)
- Multimodal reasoning (text + images/video/audio)
- Multi‑agent systems (AIs coordinating with each other)
- Robotics and medical use cases (more controlled and safety‑critical)
6) Important open questions
- RL vs supervised fine‑tuning (SFT): When should you use RL (trial‑and‑error with rewards) instead of SFT (learning from examples)? Many strong systems use both at different stages.
- Reward definitions: How to create reliable rewards for tasks without a clear answer key?
- Training recipes: What are the best mixes of data, rewards, regularization, and compute budgets?
- Scaling: Beyond just more data and bigger models, how do we scale “train‑time RL” and “test‑time thinking” efficiently and safely?
Why does this matter?
Clear takeaways:
- RL gives models a new way to grow: not just by reading more text, but by practicing tasks with feedback, like a student doing graded exercises.
- For tasks with automatic checks (math, code), RL has already unlocked big reasoning gains. That’s why so many recent “thinking” model breakthroughs focus there first.
- As rewards get better (denser, fairer, harder to cheat) and training tools improve, we can teach models to reason across more real‑world tasks.
- The long‑term vision is that RL could keep scaling models’ reasoning abilities, helping them plan, reflect, and self‑correct—key steps toward truly helpful, trustworthy AI assistants.
In short, this survey shows how reinforcement learning has become a core ingredient for making LLMs better thinkers, maps out the methods that work, and highlights the challenges we must solve to push reasoning AI even further.
Collections
Sign up for free to add this paper to one or more collections.

