WithAnyone: Towards Controllable and ID Consistent Image Generation
Abstract: Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.




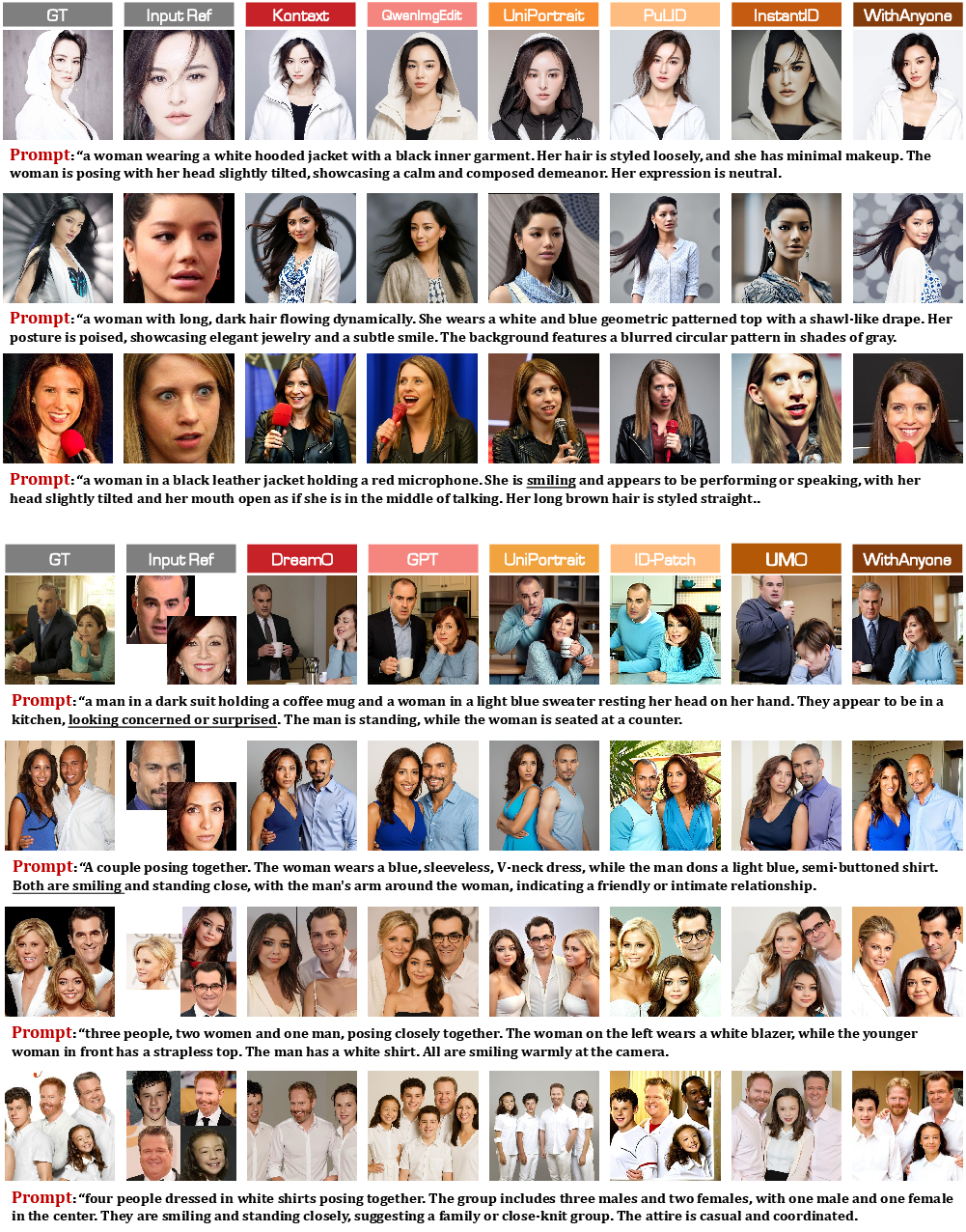
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “WithAnyone: Towards Controllable and ID Consistent Image Generation”
Overview
This paper is about teaching AI to create images of real people that look like them (keep their identity) while still letting the person change naturally—like turning their head, smiling, or being in different lighting. The authors build a new dataset and new training methods so the AI doesn’t just “copy-paste” the reference photo, but can generate varied, controllable, and realistic pictures of the same person or even groups of people.
Key questions the paper asks
- Can we make an AI that keeps someone’s identity consistent across different poses, expressions, and scenes, not just a direct copy of the original photo?
- How do we fairly measure identity accuracy without encouraging “copy-paste” behavior?
- What kind of training data and training tricks help the AI balance “looking like the person” with “being flexible and controllable”?
How they approached it (in everyday terms)
To solve the problem, the authors did three main things:
- Built a big dataset called MultiID-2M:
- Imagine a giant photo album of group pictures of celebrities, plus hundreds of different reference photos for each person (smiling, different angles, different hair, different makeup).
- This gives the AI many examples of how the same person can look naturally different from photo to photo.
- Created a fair test called MultiID-Bench:
- Instead of only measuring how similar the AI’s picture is to the single reference photo, they compare it to the actual scene it’s supposed to match (the “ground truth” image and prompt).
- They add a “copy-paste” score to detect when the AI is just copying the reference face too closely, instead of making a fresh, natural image.
- Trained a new model called WithAnyone using smarter rules:
- The model is built on a strong image-generation backbone (FLUX) that turns random noise into a picture step by step (you can think of it like sculpting a face from static).
- It uses “face embeddings” (like a compact fingerprint of a face) to understand identity.
- It adds a contrastive identity loss: this is like teaching the AI to pull the generated face closer to the correct person and push it away from other people—using lots of “negative” examples, which are faces of different identities.
- It uses “ground-truth–aligned” identity checks: when the model is learning, it uses landmarks (like eyes, nose, mouth positions) from the real target image to better judge whether the generated image matches the person, even while the image is still being formed.
Training happened in four gentle steps:
- Learn basics by reconstructing faces from simple prompts (like “two people”) to warm up the model.
- Keep reconstructing but now with full captions to tie identity to language and scenes.
- Use paired training: give the model one photo of a person as input and a different photo of the same person as the target. This breaks the “copy-paste” shortcut and forces the model to learn the true identity rather than copying pixels.
- Fine-tune on high-quality images to improve style, lighting, and overall look.
Technical terms explained simply:
- Identity consistency: making the generated face clearly look like the same person across different situations.
- Copy-paste artifact: when the AI basically traces the reference photo instead of creating a new, natural image of the same person.
- Embedding: a compact number-based “summary” of a face; like a digital fingerprint that helps the AI compare identities.
- Contrastive loss: a training rule that says “get closer to the correct person, farther from wrong ones.”
- Diffusion/FLUX: a method that starts from noise and gradually shapes it into a realistic image.
Main findings and why they’re important
- WithAnyone reduces “copy-paste” while keeping identity accuracy high:
- In tests, other models often face a trade-off: to look more like the person, they copy the reference too closely. WithAnyone breaks that trade-off and stays both accurate and flexible.
- Better control of pose and expression:
- The model responds well to prompts like “smiling” or “looking left” without losing who the person is.
- Works for multiple people in one image:
- WithAnyone can keep the identities of multiple people consistent in the same picture (like group photos) while still allowing natural differences between them.
- Strong scores in both numbers and user studies:
- Metrics and human evaluations agree: the model looks good and preserves identity without obvious copying.
What this means going forward
- More natural, customizable portraits:
- Think of making a family photo or a movie poster where everyone looks like themselves, but you can choose poses, expressions, styles, and scenes.
- Better benchmarks and data for the field:
- MultiID-2M and MultiID-Bench give researchers fairer tests and richer data to improve identity-aware generation.
- Safer, more controllable generation:
- Reducing copy-paste lowers the risk of awkward or unrealistic results and supports responsible, high-quality use.
- Broad applications but also responsibility:
- Useful for creative industries, social media, and photo editing. At the same time, the authors’ focus on celebrities and standardized evaluation highlights the need for ethical, respectful use of identity-based AI.
Knowledge Gaps
Below is a concise list of the paper’s key knowledge gaps, limitations, and open questions that remain unresolved.
- Copy-Paste metric validity and robustness:
- The mathematical definition of M_CP (including the ε stabilization and normalization by θ_tr) lacks sensitivity analysis; how do different ε values or near-zero θ_tr cases affect the metric?
- Correlation with human judgments was reported as “moderate” without effect sizes or formal validation across diverse scenarios; stronger psychometric validation is needed.
- The metric is tied to ArcFace embeddings; does its performance hold under alternative face encoders (e.g., AdaFace, MagFace) or multi-encoder ensembles?
- ArcFace-centric evaluation bias:
- Identity similarity and losses rely heavily on ArcFace; the paper does not quantify how biases in ArcFace (race, age, gender, makeup, occlusion) propagate to training and evaluation.
- No cross-demographic breakdowns of Sim(GT), CP, and blending are reported; subgroup fairness and performance stratification remain unexplored.
- Ground-truth–aligned ID loss assumptions:
- Using GT landmarks to align generated faces during training may bias the learned representation toward GT geometry; impact when GT landmarks are unavailable (real-world inference) is not examined.
- The method’s behavior when GT and generated poses differ significantly (e.g., profile vs. frontal) is not analyzed; does the alignment introduce pose-dependent distortions?
- Face detection and region-restricted attention:
- Identity embeddings are restricted to attend only to detected face regions, but the effect of mis-detections, partial faces, extreme poses, heavy occlusions, masks, or profile views on identity fidelity is not quantified.
- No ablation on different face detectors or segmentation strategies (quality thresholds, multi-face conflicts) is provided.
- Dataset construction quality and label noise:
- Identity assignment via ArcFace clustering and cosine threshold (0.4) lacks empirical estimates of false-match/false-miss rates and cluster purity; how noisy are the identity labels?
- The paper claims “diverse nationalities and ethnicities,” but provides no distributional statistics or fairness audits across demographic groups.
- Benchmark coverage and representativeness:
- MultiID-Bench contains 435 cases with up to 4 identities; performance for larger groups (≥5), crowded, or highly occluded scenes is not evaluated despite MultiID-2M including such cases.
- Prompts are derived from GT images; generalization to free-form, compositional, or ambiguous prompts is not assessed.
- Reported anomalies for VLMs (prior knowledge about TV series) reveal potential contamination/overlap with foundation model training data; mitigation and decontamination strategies are not discussed.
- Scalability and efficiency:
- Extended negative pools (up to thousands per sample) can be memory- and compute-intensive; the paper does not report training/inference costs, throughput, or memory footprints.
- No systematic sensitivity studies on loss weights (λ_ID, λ_CL), temperature τ, negative pool size, or hard-negative mining strategies are presented.
- Controllability granularity:
- While improved prompt-based control for pose and expression is claimed, the paper does not expose attribute-level controllers (e.g., explicit yaw/pitch/roll, smile intensity, gaze) or quantify control accuracy against target attributes.
- Spatial control (placement of multiple identities via boxes/keypoints) is not formally supported or evaluated; current control is text-only.
- Style and domain generalization:
- Robustness across non-photorealistic styles (sketch, anime, oil painting), extreme lighting, low-resolution inputs, and heavy image degradations is not measured.
- The impact of strong stylization on identity fidelity and copy-paste is not studied in a controlled manner.
- Generalization beyond celebrities:
- MultiID-2M focuses on celebrities; generalization to ordinary individuals (no public image banks, fewer references per identity) and domain shift to non-celebrity photos remains an open question.
- Multi-ID composition and interactions:
- Identity blending and co-occurrence metrics are reported, but compositional correctness (relative positions, occlusions, gaze interactions, body overlaps) is not rigorously evaluated.
- Failure cases for multi-person arrangement (identity swaps, duplicated faces, incorrect pairing of references to generated faces) are not systematically analyzed.
- Evaluation protocol dependencies:
- Rankings of CP are conditioned on Sim(GT) thresholds (e.g., >0.35 or >0.40); the sensitivity of conclusions to these thresholds is not explored.
- The paper mixes closed-source baselines and heterogeneous backbones (FLUX, VAE, DiT) without compute budget normalization; fairness of comparisons is unclear.
- User study limitations:
- Only 10 participants evaluated 230 groups; statistical power, inter-rater reliability, and detailed effect sizes are not reported.
- No blinded or counterbalanced protocol details; potential anchoring or model-recognition biases remain.
- Safety, ethics, and legal considerations:
- The dataset uses celebrity imagery scraped from the web; consent, licensing status, and take-down policies are not described.
- Risks of impersonation, deepfake misuse, and identity harm are not addressed; no proposed safeguards (watermarking, usage policies, detection tools) accompany model/dataset release.
- Reproducibility details:
- Training pipeline hyperparameters (learning rates, optimizer configs, augmentation policies), exact negative sampling procedures, and stylization recipe are only partially described; full reproducibility is uncertain.
- No code/eval artifacts for computing CP, blending, and identity metrics across alternative encoders are documented for independent verification.
- Extensions and broader applicability:
- Video personalization (temporal coherence, identity drift), cross-modal inputs (audio, multi-view), and 3D-aware identity control are not explored.
- Extension to non-human “identities” (e.g., pets, characters) and cross-species identity preservation is not examined.
- Open methodological questions:
- Can copy-paste be mitigated further via 3D face priors, disentangled latent controls, or pose/expression conditional diffusion without sacrificing Sim(GT)?
- What are the theoretical limits of balancing fidelity and variation under different identity encoders and training objectives?
- How does the approach perform under limited reference images per identity (e.g., 1–5), and what are the minimal data requirements to avoid copy-paste?
Practical Applications
Immediate Applications
The following bullet points summarize concrete use cases that can be deployed now, drawing on the paper’s dataset (MultiID-2M), benchmark (MultiID-Bench), training paradigm (paired tuning), losses (GT-aligned ID loss, ID contrastive loss with extended negatives), and copy-paste metric.
- Identity-consistent creative production for ads, film, and gaming
- Sectors: media/entertainment, advertising, game art
- What: Generate controllable portraits and multi-person scenes of known talent (actors, athletes, influencers) with reliable identity consistency and natural variation in pose/expression/lighting, avoiding copy-paste artifacts.
- Tools/Products/Workflows: “WithAnyone for Adobe/Blender” plugins; studio asset pipelines that maintain a reference vault; promptable pose/expression control with MultiID-Bench-based QA gates.
- Assumptions/Dependencies: Legal consent and licensing for identity use; sufficient reference images per identity; GPU inference capacity; demographic robustness of ArcFace-based pipelines.
- Social photo apps and editors for group compositing and retouching
- Sectors: consumer software, social platforms
- What: Insert or adjust individuals in group photos while preserving identity and enabling natural facial edits (smile, gaze, pose), with lower risk of obvious cloning artifacts.
- Tools/Products/Workflows: Mobile editor feature “Add friend to photo”; region-aware face conditioning; Copy-Paste risk scoring to discourage trivial cloning in UX.
- Assumptions/Dependencies: User-provided reference faces; reliable face detection/landmarks in varied lighting; moderation for impersonation abuse.
- Brand ambassador consistency across marketing assets
- Sectors: advertising, CRM, retail
- What: Produce entire campaign sets with consistent brand ambassadors while varying style, setting, and expression for A/B tests.
- Tools/Products/Workflows: Creative asset generation pipelines with MultiID-Bench regression tests; dashboards tracking Sim(GT) vs Copy-Paste scores.
- Assumptions/Dependencies: Reference library management; QA processes; alignment of prompts and campaign briefs; ethics/legal compliance.
- E-commerce product imagery and virtual try-on with stable models
- Sectors: retail/e-commerce
- What: Use identity-consistent models to present apparel/beauty products across diverse poses and expressions, improving catalog coherence.
- Tools/Products/Workflows: Batch generation tools that pin model identity while prompting pose/expression; benchmark-in-the-loop QA to detect identity drift or copying.
- Assumptions/Dependencies: Extension beyond celebrity references; domain adaptation to product contexts; model governance to prevent deceptive imagery.
- Event photography and portrait studios: multi-shot completion and compositing
- Sectors: professional photography
- What: Generate missing shots or better group compositions that preserve each attendee’s identity with controllable expressions and poses.
- Tools/Products/Workflows: Studio software integrating WithAnyone; per-attendee reference capture; copy-paste artifact checks before delivery.
- Assumptions/Dependencies: Consent; reliable identity matching across varied angles; data management for references.
- Copy-Paste Risk Score for content quality assurance
- Sectors: software, content moderation, creative ops
- What: Use the paper’s Copy-Paste metric to flag overly cloned outputs and enforce natural variation targets in generation workflows.
- Tools/Products/Workflows: “Copy-Paste score” API integrated into CI/CD for gen features; prompt-checkers that recommend pose/expression diversification.
- Assumptions/Dependencies: Availability of a target scene or proxy references; tuning threshold per use case; potential domain gaps if GT is unavailable.
- Benchmark-as-a-Service for multi-identity generation
- Sectors: software, ML platforms, academia
- What: Standardize evaluation of multi-ID generation with MultiID-Bench, reporting Sim(GT), Sim(Ref), copy-paste, blending, CLIP metrics, and aesthetics.
- Tools/Products/Workflows: Hosted evaluation; leaderboards; reproducible splits; automated reports for model releases.
- Assumptions/Dependencies: Agreement on metric definitions; dataset licensing; periodic updates to cover long-tail identities.
- Training recipe adoption: paired tuning and extended negatives
- Sectors: ML research & product teams, foundation model vendors
- What: Integrate the paper’s four-phase training and losses to reduce copy-paste while preserving fidelity for identity-sensitive tasks.
- Tools/Products/Workflows: Open-source training scripts; reference bank construction via clustering; extended negative pools from curated ID-labeled datasets.
- Assumptions/Dependencies: Large-scale paired data; compute budgets; careful hyperparameter tuning (temperatures, weights).
- Synthetic augmentation for face recognition robustness
- Sectors: biometrics, security
- What: Generate controlled variations (pose, lighting, expression) for identities to stress-test and improve recognition systems.
- Tools/Products/Workflows: Data augmentation pipelines tied to Sim(GT) and blending metrics; balanced sampling to mitigate demographic bias.
- Assumptions/Dependencies: Compliance with privacy and biometric regulations; careful evaluation to avoid overfitting to synthetic distributions.
- Reference vault management and curation
- Sectors: media asset management, creative ops
- What: Adopt the paper’s clustering/cleaning pipeline to build high-quality identity reference banks for studios/agencies.
- Tools/Products/Workflows: ArcFace-based clustering, DBSCAN-style de-duplication; OCR/logo removal; LLM captions for metadata.
- Assumptions/Dependencies: Stable face embedding performance across demographics; robust face detection; licensed sources.
Long-Term Applications
These use cases require further research, scaling, or development—especially extensions to video, real-time systems, and broader domains beyond celebrity faces.
- Identity-consistent multi-character video generation and editing
- Sectors: film/TV, streaming, VFX
- What: Extend WithAnyone to temporally consistent video for de-aging, continuity across shots, and controllable expressions over time.
- Tools/Products/Workflows: Video DiT/rectified-flow backbones; temporal contrastive losses; frame-level copy-paste monitoring.
- Assumptions/Dependencies: Video datasets with paired identity references; temporal alignment methods; watermarking/provenance tooling.
- Real-time telepresence and VR avatars
- Sectors: communications, XR
- What: Live identity-preserving avatars that faithfully reflect user expressions and poses without rigid copying artifacts.
- Tools/Products/Workflows: Low-latency inference stacks; face-region attention; driver signals from webcams or sensors; safety filters.
- Assumptions/Dependencies: Efficient on-device models; robust tracking; privacy-preserving pipelines.
- Clinical and aesthetic planning tools (face procedures)
- Sectors: healthcare
- What: Identity-consistent simulations of likely outcomes (e.g., dental/orthognathic/cosmetic) under diverse poses/lighting.
- Tools/Products/Workflows: Secure clinical UIs; physician-controlled prompts; audit trails; patient consent management.
- Assumptions/Dependencies: Medical validation; bias/fairness assessments; strict regulatory compliance and disclaimers.
- Policy toolkits for identity rights and deepfake governance
- Sectors: policy/regulation, platform trust & safety
- What: Use copy-paste and blending metrics to define permissible similarity ranges, detect near-clones of public figures, and enforce platform rules.
- Tools/Products/Workflows: “Similarity thresholding” standards; API integrations for takedown or review queues; provenance labels.
- Assumptions/Dependencies: Legal adoption; robust reference databases; careful calibration to balance satire/fair use.
- Enterprise-grade generative compliance and model cards
- Sectors: software governance, enterprise AI
- What: Incorporate MultiID-Bench metrics into model documentation and release gates to demonstrate controlled identity fidelity without cloning.
- Tools/Products/Workflows: Compliance dashboards; build-time tests; lineage logs; risk statements linked to metrics.
- Assumptions/Dependencies: Organizational buy-in; standardized reporting; periodic auditing.
- Cross-domain multi-entity generation (beyond faces)
- Sectors: robotics (parts ID), ecology (species), industrial inspection
- What: Adapt the paired-data construction and contrastive negative pooling to objects, animals, and parts that require consistent identity across variations.
- Tools/Products/Workflows: Domain-specific detectors/embedders; curated paired datasets; sector-specific evaluation protocols.
- Assumptions/Dependencies: Reliable “identity” embeddings per domain; labeled references; new benchmarks.
- Personalized assistants with consistent visual identity across apps
- Sectors: consumer software, productivity
- What: Maintain a user’s avatar identity consistently across chat, docs, meetings, and social apps, with controllable expressions/styles.
- Tools/Products/Workflows: Cross-app identity tokens; pose/expression APIs; privacy-preserving storage of reference vaults.
- Assumptions/Dependencies: Interoperability standards; consent and portability; device-local generation.
- Deepfake forensics and training datasets
- Sectors: security, forensics
- What: Create labeled sets of “copy-paste” vs “controlled variation” deepfakes to train detectors; use metrics as features.
- Tools/Products/Workflows: Synthetic data generation pipelines; feature engineering around angular distances; forensic benchmarks.
- Assumptions/Dependencies: Access to high-quality references; legal permissions; continual updates to counter adversarial advances.
- On-device identity customization for mobile and edge
- Sectors: consumer hardware, embedded systems
- What: Compress and distill identity customization models for phones, AR glasses, and cameras while preserving controllability.
- Tools/Products/Workflows: Quantization/distillation; edge inference runtimes; incremental reference-bank updates.
- Assumptions/Dependencies: Efficient DiT variants; thermal/power constraints; secure storage of identity data.
- Rights-managed creative platforms with audit and watermarking
- Sectors: creative SaaS, IP management
- What: Platforms that track identity references, verify usage rights, watermark outputs, and audit copy-paste risk across projects.
- Tools/Products/Workflows: Asset rights registries; provenance frameworks; user education about ethical generation.
- Assumptions/Dependencies: Industry standards for watermarking and provenance; integration with legal/licensing systems.
Notes on Assumptions and Dependencies (Cross-cutting)
- Identity references: Many applications require multiple high-quality, diverse references per identity; systems should manage a “reference vault” and consent.
- Embeddings and detection: ArcFace/RetinaFace and landmark alignment underpin key losses/metrics; demographic bias and edge cases must be monitored.
- Benchmarks and metrics: MultiID-Bench presumes access to GT or well-specified prompts; in real-world moderation, approximate targets or multi-reference distributions may be needed.
- Compute and scaling: Paired training with extended negative pools is compute-heavy; deployment may need distillation and edge optimization.
- Legal/ethical constraints: Identity use, deepfake risks, and impersonation require policy guardrails, watermarking, and user education.
- Generalization: The dataset is celebrity-heavy; domain adaptation to non-celebrity or enterprise contexts may require additional curation and consent.
Glossary
- Angular distance: The angle-based distance between two embeddings on the unit sphere used to compare identities. "We define the angular distance as (geodesic distance on the unit sphere)."
- ArcFace: A face recognition model that produces identity-discriminative embeddings for faces. "ArcFace embedding requires landmark detection and alignment,"
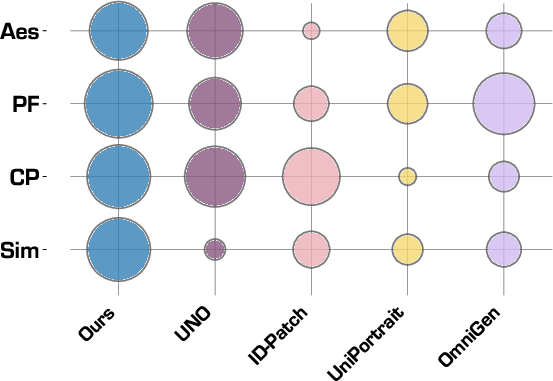
- CLIP I/T: CLIP-based image/text similarity metrics used to quantify prompt fidelity in generation. "We additionally report identity blending, prompt fidelity (CLIP I/T), and aesthetics;"
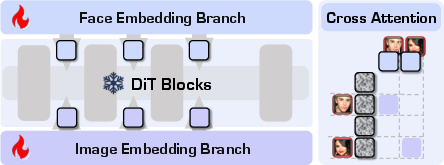
- Contrastive identity loss: A loss that pulls generated face embeddings toward the correct identity while pushing away other identities. "we introduce an ID contrastive loss that explicitly pulls the generated image closer to its reference images in the face embedding space while pushing it away from other identities."
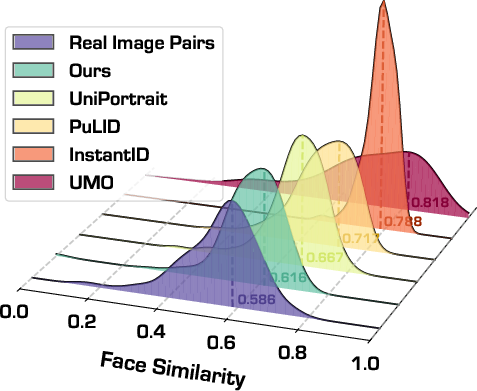
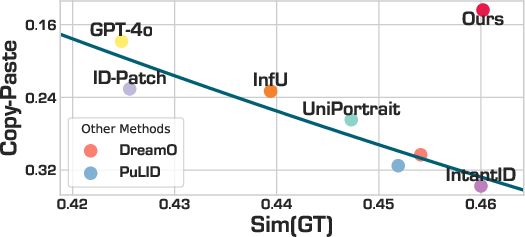
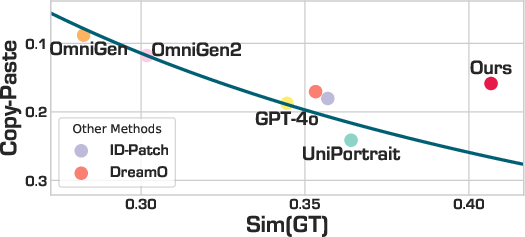
- Copy-Paste artifact: A failure mode where the model replicates the reference image instead of preserving identity under variations. "We term this failure mode the copy-paste artifact: rather than synthesizing an identity in a flexible, controllable manner, the model effectively copies the reference image into the output"
- Copy-Paste metric: A metric that measures the bias of a generated image toward the reference versus the ground truth. "The Copy-Paste metric is given by"
- Cosine distance: A measure of dissimilarity computed as one minus cosine similarity between embeddings. "We minimize the cosine distance between GT-aligned ArcFace embeddings of the generated and ground-truth (GT) faces:"
- Cosine similarity: The normalized dot product used to compare face embeddings and assign identities. "assign identities by matching ArcFace embeddings to single-ID cluster centers using cosine similarity (threshold 0.4)"
- DiT-style backbone: Diffusion Transformer-based architectures used as the generative model backbone. "With the rise of DiTâstyle backbones~\citep{peebles2023scalable,esser2024scaling,flux2024} (e.g., SD3, FLUX), progress in ID preservation like PuLID~\citep{guo2024pulid}, also attracts great attention."
- Diffusion loss: The training objective for diffusion/rectified-flow models that regresses velocity between noise and data. "Diffusion Loss. We adopt the mini-batch empirical flow-matching loss."
- Flow-matching loss: An empirical rectified-flow objective that trains the model to predict the velocity from noise to data. "We adopt the mini-batch empirical flow-matching loss."
- FLUX: A diffusion-transformer architecture that serves as the backbone for the proposed model. "WithAnyone, a novel identity customization model built on the FLUX~\citep{flux2024} architecture"
- Geodesic distance: The shortest-path distance on the unit sphere used to interpret angular distances between embeddings. "(geodesic distance on the unit sphere)"
- GT-aligned ID loss: An identity loss computed by aligning generated faces with ground-truth landmarks to avoid noisy detection. "Ground-truthâAligned ID Loss."
- Ground-truth (GT): The target reference image or identity used to evaluate fidelity in benchmarks. "Let denote the face embeddings of the reference identity, the target (ground-truth), and the generated image, respectively."
- Identity blending: A metric capturing unintended mixing of identities in multi-person generation. "We additionally report identity blending, prompt fidelity (CLIP I/T), and aesthetics;"
- Identity customization: The task of conditioning image generation to preserve specific identities. "WithAnyone: A novel ID customization model built on FLUX that achieves state-of-the-art performance, generating high-fidelity multi-identity images while mitigating copy-paste artifacts and enhancing visual quality."
- Identity fidelity: The degree to which a generated image matches the target identity rather than simply copying the reference. "Evaluation considers both identity fidelity and generation quality."
- InfoNCE: A contrastive learning objective used to separate positive identity pairs from negatives via a temperature-scaled softmax. "The loss follows the InfoNCE~\citep{oord2018representation} formulation:"
- Negative pool (extended negatives): A large set of non-matching identity embeddings used to strengthen contrastive training. "The labeled identities and their reference images enable the construction of an extended negative pool (images of different identities), which provides stronger discrimination signals during optimization."
- Prompt fidelity: How well the generated image adheres to the text prompt, often measured with CLIP metrics. "We additionally report identity blending, prompt fidelity (CLIP I/T), and aesthetics;"
- RetinaFace: A face detection model used to obtain landmarks for alignment before embedding extraction. "the coupled detection model as (RetinaFace~\citep{Deng2020retinaface}),"
- UNet: A convolutional encoder–decoder architecture historically used in diffusion models for image synthesis. "Many methods in the UNet/Stable Diffusion era inject learned embeddings (e.g., CLIP or ArcFace) via crossâattention or adapters"
- VAE-derived face embeddings: Identity features obtained by encoding faces with a variational autoencoder, often prone to low-level copying. "use VAEâderived face embeddings concatenated with model inputs, which can produce pixelâlevel copyâpaste artifacts and reduce controllability."
- VLMs (Vision-LLMs): Multimodal models that jointly process images and text but may underperform on identity-sensitive tasks. "However, VLMs~\citep{Qwen2.5-VL,openai2025gpt4o} exhibit limited ability to distinguish individual identities and instead emphasize non-identity attributes such as pose, expression, or background."
Collections
Sign up for free to add this paper to one or more collections.

