- The paper demonstrates efficient reinforcement learning by scaling long-context and short-CoT methods without relying on complex techniques.
- It integrates stages of pretraining, SFT, long-CoT fine-tuning, and RL to optimize policy, token efficiency, and reasoning strategies.
- Experimental results reveal state-of-the-art performance across text, coding, and vision benchmarks with improved reward and sampling strategies.
Kimi k1.5: Scaling Reinforcement Learning with LLMs
This paper introduces Kimi k1.5, a multi-modal LLM trained with RL, and details its training methodologies, multi-modal data recipes, and infrastructure optimizations (2501.12599). The key contributions revolve around long context scaling and improved policy optimization, enabling the development of a simplistic RL framework without the need for complex techniques like Monte Carlo tree search, value functions, and process reward models. The system achieves state-of-the-art reasoning performance across multiple benchmarks, matching OpenAI's o1 in several areas. Effective long2short methods are also presented, which leverage long-CoT techniques to enhance short-CoT models, outperforming existing short-CoT models by a significant margin.
Core Methodology and Innovations
The training of Kimi k1.5 involves several stages: pretraining, vanilla SFT, long-CoT supervised fine-tuning, and RL. The focus is on RL, with emphasis on RL prompt set curation and long-CoT supervised finetuning.
A high-quality RL prompt set is defined by three key properties:
- Diverse Coverage
- Balanced Difficulty
- Accurate Evaluability
The paper adopts a model-based approach to adaptively assess the difficulty of each prompt, using the SFT model to generate answers and calculating the pass rate as a proxy for difficulty. To avoid reward hacking, questions that are prone to easy guessing are excluded. Prompt engineering is used to construct a small, high-quality long-CoT warmup dataset, encapsulating key cognitive processes such as planning, evaluation, reflection, and exploration. Lightweight SFT on this warm-up dataset primes the model to internalize these reasoning strategies.
Reinforcement Learning Framework
The paper frames the RL problem as training a policy model πθ to accurately solve test problems, using a sequence of intermediate steps z=(z1,z2,…,zm) to bridge the problem x and the solution y. Planning algorithms are viewed from an algorithmic perspective, with a planning algorithm A iteratively determining the next search direction and providing feedbacks. This framework allows the training of a model to approximate the planning process, where the number of thoughts serves as an analogy to the computational budget allocated to planning algorithms.
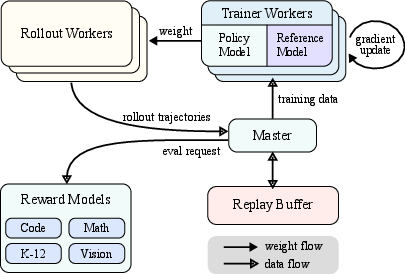
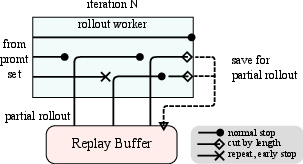
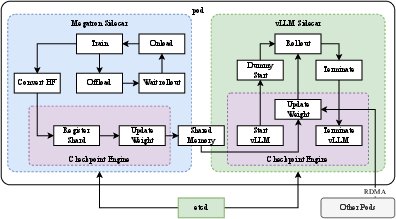
Figure 1: System overview
The model is trained to generate CoT with RL, where the quality of the generated CoT is evaluated by whether it leads to a correct final answer. An online policy mirror descent variant is used as the training algorithm, with the objective of maximizing the expected reward while regularizing the KL divergence between the current policy and a reference policy. A surrogate loss is derived, and the gradient is calculated using samples from the reference policy.
A key aspect of the RL framework is the exclusion of the value network, hypothesizing that the conventional use of value functions for credit assignment may not be suitable for the context of generating long CoT. Encouraging the model to explore diverse reasoning paths is crucial for developing critical planning skills.
Practical Implementation Details
Length Penalty
To address the issue of increasing response length during RL training, a length reward is introduced to restrain the growth of token length, improving token efficiency. The length reward promotes shorter responses and penalizes longer responses among correct ones, while explicitly penalizing long responses with incorrect answers.
Sampling Strategies
Curriculum sampling is used to start training on easier tasks and gradually progress to more challenging ones. Prioritized sampling focuses on problems where the model underperforms, directing the model's efforts toward its weakest areas.
Test Case Generation for Coding
A method is designed to automatically generate test cases for coding problems, utilizing the CYaRon library. The base Kimi k1.5 model is used to generate test cases based on problem statements, and the test cases are deemed valid if they yield matching results for a sufficient number of ground truth submissions.
Reward Modeling for Math
Two methods are used to improve the reward model's scoring accuracy:
The Chain-of-Thought RM is adopted in the RL training process to ensure more correct feedback.
Vision Data
Vision RL data is primarily sourced from three distinct categories:
Long2short: Context Compression for Short-CoT Models
Several approaches are presented for the long2short problem, including model merging, shortest rejection sampling, DPO, and long2short RL. These methods aim to transfer the thinking priors from long-CoT models to short-CoT models, improving performance even with limited test-time token budgets.
RL Infrastructure
The RL training system adopts an iterative synchronous approach, with each iteration encompassing a rollout phase and a training phase. A key innovation is the introduction of a Partial Rollout technique, which optimizes the handling of long-CoT features by managing the rollouts of both long and short trajectories. A hybrid deployment framework is implemented on top of Megatron and vLLM, achieving fast transition between training and inference phases. A code sandbox is developed as a secure environment for executing user-submitted code, optimized for code execution and code benchmark evaluation.
Experimental Results and Analysis
The paper presents comprehensive evaluation results across various benchmarks for different modalities, including text, reasoning, and vision. The Kimi k1.5 long-CoT model achieves state-of-the-art reasoning performance across multiple benchmarks and modalities. The Kimi k1.5 short-CoT model delivers competitive or superior performance compared to leading open-source and proprietary models across multiple tasks.
The paper studies the scaling properties of RL with LLMs, illustrating the evolution of training accuracy and response length across training iterations. A strong correlation is observed between the model's output context length and its problem-solving capabilities. The long2short RL algorithm demonstrates the highest token efficiency compared to other methods such as DPO and model merge. Ablation studies demonstrate the effectiveness of the curriculum sampling strategy and the impact of negative gradients on the model's efficiency in generating long CoT.
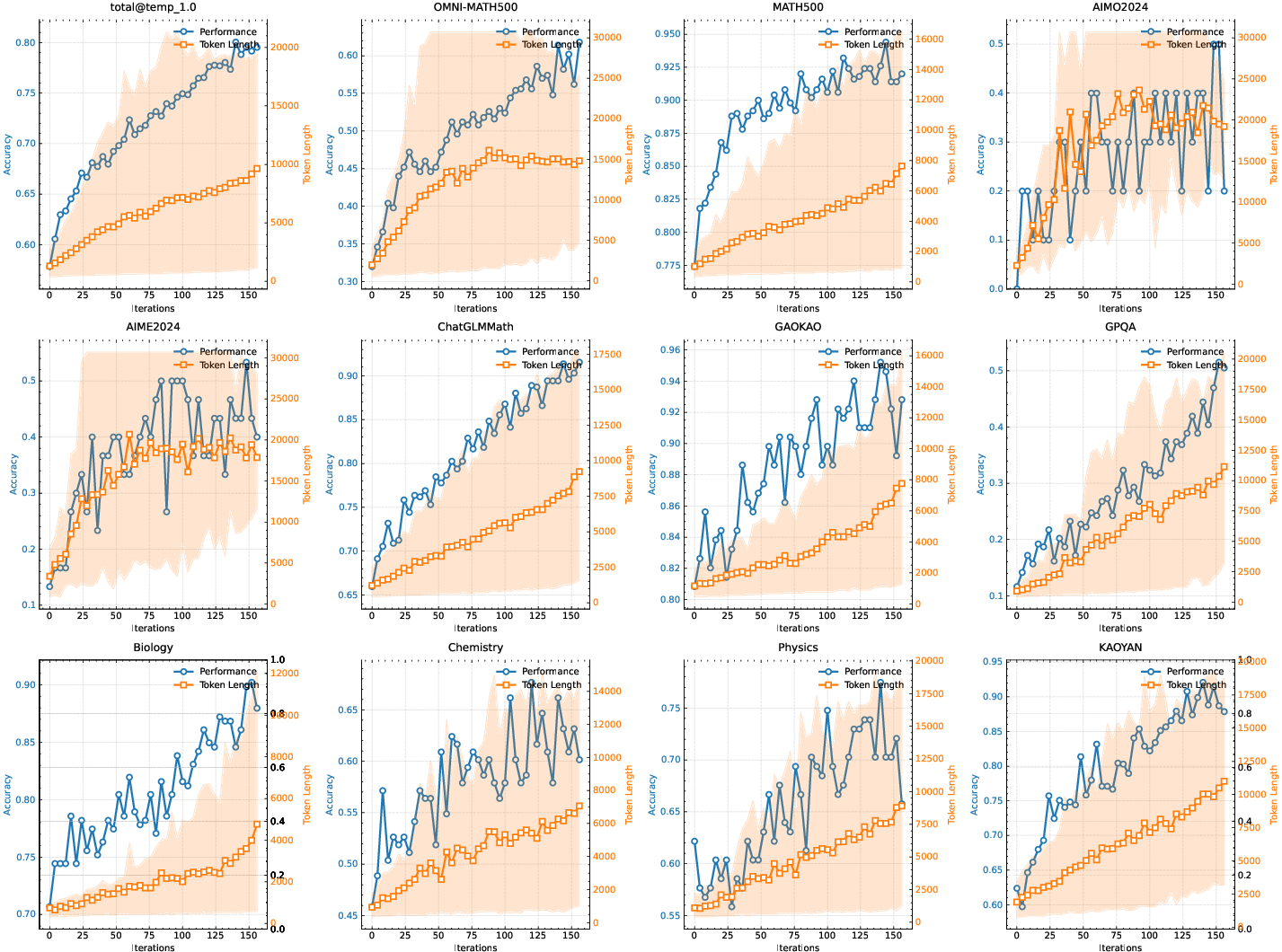
Figure 3: The changes on the training accuracy and length as train iterations grow. Note that the scores above come from an internal long-cot model with much smaller model size than k1.5 long-CoT model. The shaded area represents the 95\% percentile of the response length.
Conclusion
The paper presents the training recipe and system design of Kimi k1.5, highlighting the importance of scaling context length for the continued improvement of LLMs. Optimized learning algorithms and infrastructure optimization, such as partial rollouts, are crucial for achieving efficient long-context RL training. The combination of techniques enables improved policy optimization, and strong performance is achieved without using more complex techniques. The potential of long2short methods is also demonstrated, improving the performance of short CoT models. Future research directions include improving credit assignments and reducing overthinking without hurting the model's exploration abilities.