- The paper introduces a hybrid explanation-guided learning framework (H-EGL) that integrates self-supervised and human-guided attention alignment to improve diagnostic accuracy.
- The method employs a ViT-based encoder-decoder with dual loss components, including human-AI alignment and discriminative attention learning, validated on the ChestXDet dataset.
- Results show H-EGL achieves a test AUC of 89.3%, superior F1/MCC scores, and robust performance under noise, demonstrating enhanced interpretability and generalization.
Introduction and Motivation
Transformer-based architectures, particularly Vision Transformers (ViTs), have become central to medical image analysis due to their capacity for spatially-aware feature representation via attention mechanisms. However, these models are susceptible to shortcut learning and spurious correlations, which can undermine generalization and fairness. Explanation-Guided Learning (EGL) seeks to mitigate these issues by aligning model attention with human-understood features, but fully supervised approaches are annotation-intensive and may over-constrain the model. The paper introduces Hybrid Explanation-Guided Learning (H-EGL), a framework that synergistically combines self-supervised and human-guided attention alignment to enhance both interpretability and generalization in ViT-based chest X-ray diagnosis.
H-EGL Framework and Methodology
H-EGL is built on a ViT-based encoder-decoder architecture, integrating visual (chest X-ray) and textual (disease label) inputs. The text encoder is frozen to maintain semantic consistency, while the ViT components are trainable. The model outputs both multi-label disease predictions and class-specific attention maps.
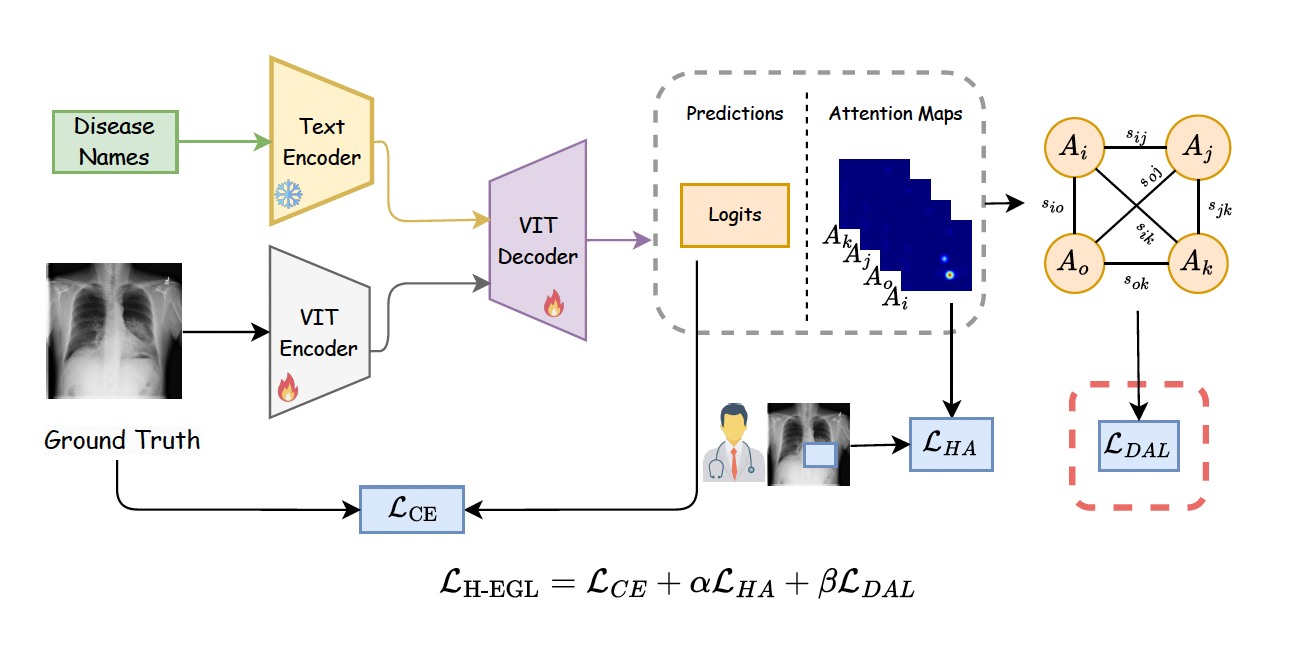
Figure 1: Overview of the H-EGL framework, illustrating the integration of visual and textual inputs, the generation of class-wise predictions and attention maps, and the dual loss structure for attention alignment.
The training objective is a composite loss:
LH-EGL=LCE+αLHA+βLDAL
where:
- LCE: Standard multi-label cross-entropy for classification.
- LHA: Human-AI alignment loss, penalized Dice loss aligning attention maps with expert-annotated regions.
- LDAL: Discriminative Attention Learning loss, enforcing class-level separability in attention maps via pairwise cosine similarity.
DAL is a self-supervised module that encourages the model to produce attention maps that are discriminative across classes, without requiring explicit negative samples or localization annotations. This inductive bias is less restrictive than prior contrastive or regularization-based approaches, preserving the model’s ability to capture subtle, clinically relevant features.
Experimental Setup
The framework is evaluated on the ChestXDet dataset, a subset of NIH ChestX-ray14, with expert-annotated pathology locations. Four thoracic pathologies are considered: atelectasis, cardiomegaly, consolidation, and effusion. The model uses Med-KEBERT for text encoding and a ViT-B backbone for image encoding. Training is performed with AdamW, a batch size of 32, and early stopping. Ablation studies isolate the contributions of DAL and human alignment.
Baselines include:
- KAD: Knowledge-enhanced detection using structured knowledge graphs.
- GAIN: Gradient-based attention inference adapted for transformers.
- DWARF: Human-annotation-only attention alignment.
- DAL-only: Purely self-supervised attention alignment.
Results
H-EGL achieves the highest test AUC (89.3%), outperforming KAD (88.1%) and GAIN (88.0%), with low variance (0.7%). F1 and MCC scores are also superior, and the generalization gap is minimized, indicating robust performance across test samples. Ablation reveals that removing either DAL or human alignment degrades performance, confirming the complementary nature of the hybrid approach.
Robustness analysis under Gaussian noise perturbations demonstrates that H-EGL and DAL maintain higher performance than baselines, with minimal degradation as noise increases.
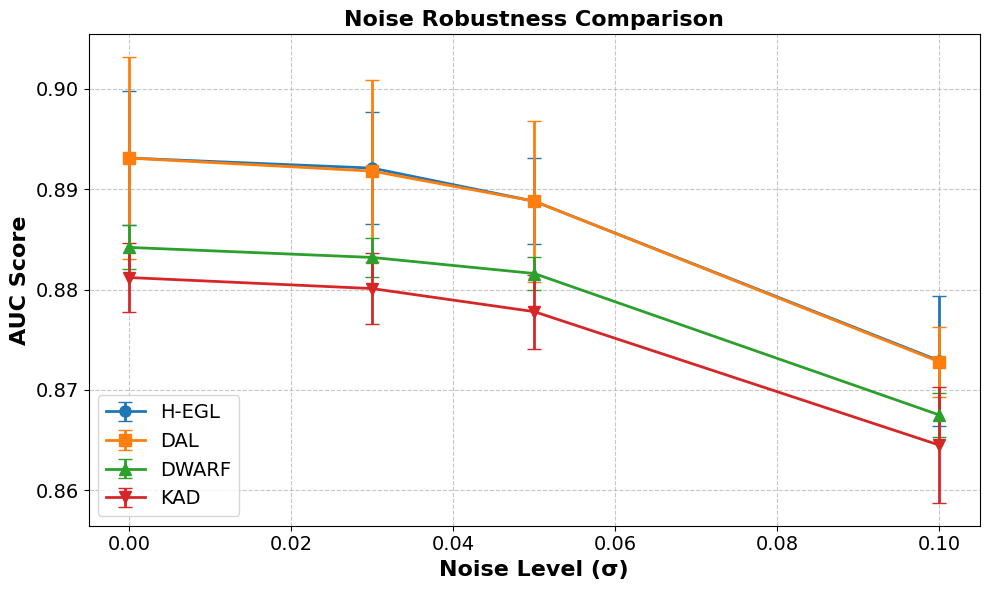
Figure 2: Robustness of H-EGL and DAL under increasing input noise, showing superior stability compared to other models.
Qualitative analysis of attention maps shows that H-EGL and DAL more accurately localize pathological regions and reduce false positives compared to KAD and DWARF. The hybrid approach achieves better alignment with expert annotations without sacrificing classification accuracy.
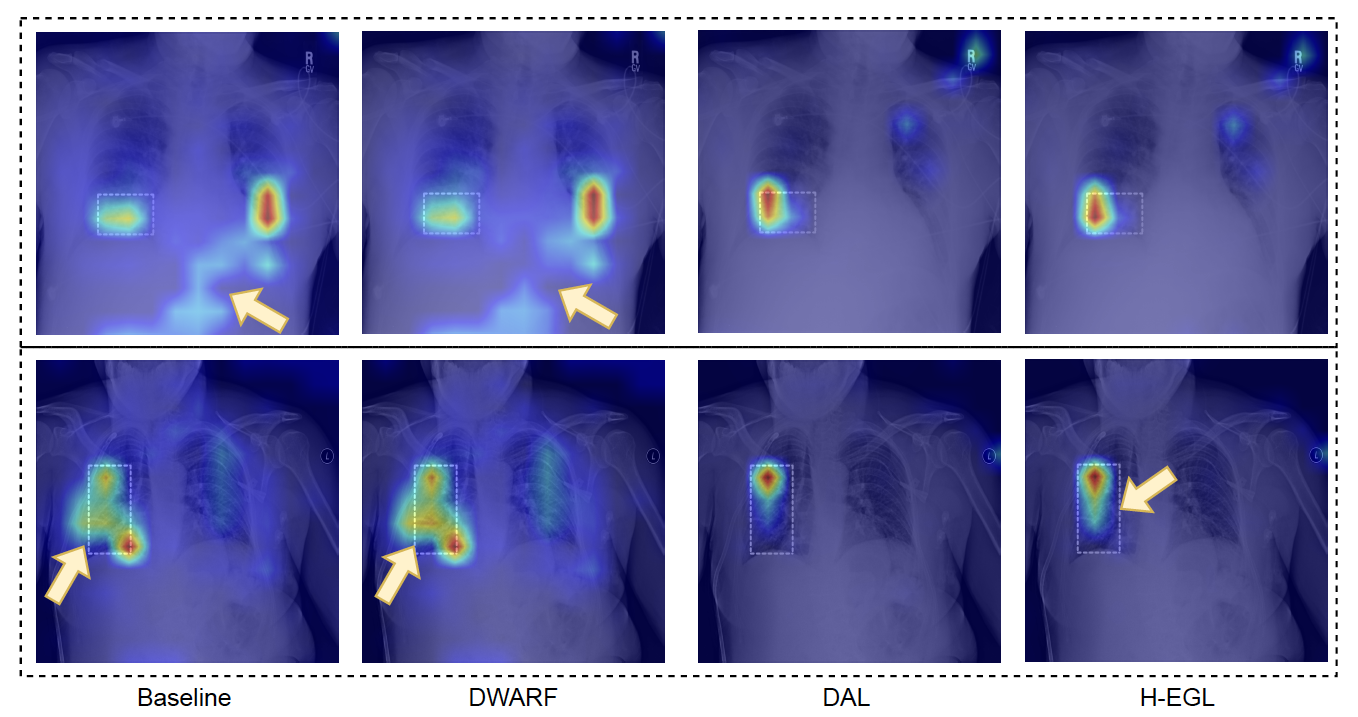
Figure 3: Comparative attention maps across models, highlighting improved localization and reduced false positives in H-EGL and DAL.
Discussion and Implications
The results substantiate that hybrid attention alignment—combining human-guided and self-supervised constraints—yields superior interpretability and generalization. DAL’s flexible inductive bias avoids over-regularization, enabling the model to learn complex, task-specific features. The framework is annotation-efficient, scalable, and compatible with existing transformer-based medical imaging pipelines.
A notable finding is the trade-off in DWARF between interpretability and accuracy; strong human alignment can reduce predictive performance. H-EGL circumvents this by balancing guidance and autonomy, analogous to trust region methods in policy learning, which adaptively constrain optimization to prevent overfitting.
The approach is architecture-agnostic and can be extended to other domains where attention alignment is critical. Future work should explore dynamic adjustment of self-supervision and human alignment during training, potentially via adaptive weighting or curriculum learning, to further optimize interpretability and generalization.
Conclusion
Hybrid Explanation-Guided Learning (H-EGL) advances the state-of-the-art in transformer-based medical image analysis by integrating self-supervised and human-guided attention alignment. The framework achieves improved robustness, interpretability, and classification performance, validated on chest X-ray diagnosis. Its scalable, annotation-efficient design positions it as a promising direction for future research in human-AI alignment and explanation-guided learning in medical imaging and beyond.