- The paper presents a novel Radiomics-Guided Transformer that integrates global image data with localized radiomic features for effective weakly supervised pathology detection.
- It utilizes a dual-branch architecture with a BYOA module to derive attention maps and generate bounding boxes for radiomic feature extraction.
- Experimental results on the NIH ChestXRay dataset show significant improvements in IoU and AUROC, underscoring enhanced interpretability and clinical relevance.
Introduction and Motivation
The paper "Radiomics-Guided Global-Local Transformer for Weakly Supervised Pathology Localization in Chest X-Rays" (2207.04394) proposes a unified Transformer-based framework that incorporates both global image information and local, domain-specific radiomic features for weakly supervised disease localization and classification in chest X-ray analysis. The work addresses several bottlenecks in medical image analysis pipelines, particularly the challenge of leveraging radiomic features—which are highly informative but traditionally depend on expert-annotated regions of interest (ROIs)—in the absence of localization supervision.
Methodology
The core contribution is the Radiomics-Guided Transformer (RGT), which combines two processing streams: an image branch operating over the entire chest X-ray and a radiomics branch that ingests local features extracted from regions hypothesized by the network.

Figure 1: Overview of the RGT framework: A chest X-ray is processed to yield an attention heatmap for localization, which enables bounding box extraction; radiomic features from this region are fused with global representations for classification.
Each branch is instantiated as a Transformer encoder. The image branch utilizes a Progressive-Sampling ViT backbone, enhancing token granularity adaptively to support more precise attention over subtler radiographic details. The radiomics branch leverages a smaller Transformer, without positional encodings, that ingests a set of 107 radiomic features, spanning first-order intensity, shape, and several texture descriptors (GLCM, GLDM, etc.).
A critical element is the Bootstrap Your Own Attention (BYOA) module, which extracts attention maps from the CLS token in the image branch. After thresholding and post-processing, the most salient regions drive the bounding box proposals required for radiomics extraction. Notably, the process leverages only image-level disease supervision without access to ground-truth localizations during training.
Figure 2: The RGT dual-branch architecture with cross-attention fusion between the Image and Radiomics Transformers.

Figure 3: The BYOA module thresholds the image branch's CLS-token attention, generates bounding boxes, and applies PyRadiomics feature extraction to guide the radiomics branch.
Both representations are fused via cross-attention layers, allowing bidirectional interaction between the aggregate (CLS) and patch representations of each modality. The final classification is performed jointly from both CLS tokens using Focal Loss for robust handling of class imbalance. An additional NT-Xent-style contrastive loss enforces agreement between the global image view and the localized radiomics view in the latent space.
Results
The experimental evaluation utilizes the NIH ChestXRay dataset for detecting and localizing 8 focal cardiopulmonary conditions. Only image-level labels are used during training, consistent with a weakly supervised setting.
In localization, RGT achieves a mean improvement of 3.6% in intersection-over-union (IoU) across multiple thresholds compared to ViT and the baseline method under the same weak supervision constraints. For instance, at IoU 0.1, RGT reaches 59.1% mean localization accuracy, outperforming the ViT baseline and prior methods.
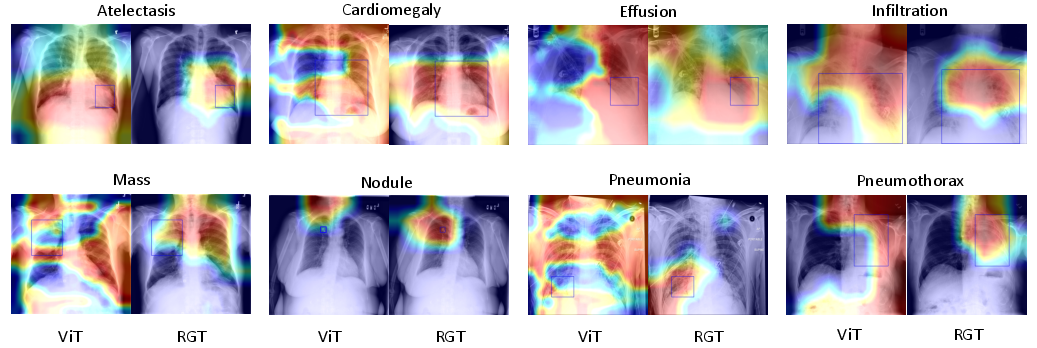
Figure 4: Qualitative results: RGT demonstrates more precise and consistent localization than ViT, with attention maps closely overlapping ground-truth boxes across multiple pulmonary disease types.
On pathology classification, RGT achieves an average AUROC of 0.839, exceeding state-of-the-art CNN approaches (e.g., CheXNet at 0.828) and previous Transformer-based baselines.
Notably, RGT consistently demonstrates enhanced discrimination for pathologies such as Infiltration and Nodule, with improvements as high as 0.13 AUROC over prior work. The method is robust across three random initializations, as evidenced by low standard deviations.
Further analysis explores the sensitivity of the attention threshold in BYOA and the supervised-to-contrastive loss balancing parameter (λ). Larger bounding boxes (lower threshold T) provide more useful radiomic descriptors for the classification task, indicating the importance of receptive field size in medical representation fusion. Meanwhile, intermediate weighting of the contrastive loss maximizes classification accuracy, affirming the value of joint supervision.
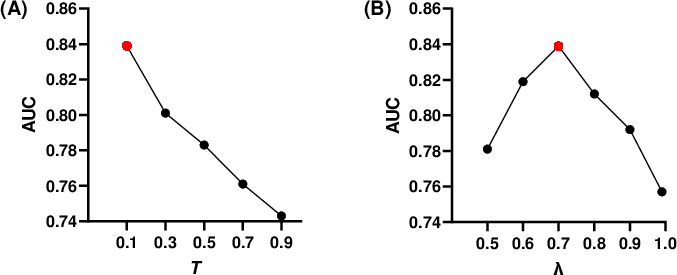
Figure 5: Disease classification AUROC is modulated by the size of attention map threshold T (A) and the contrastive loss balance parameter λ (B).
A usability study with radiologists further validated that RGT heatmaps are well-aligned with expert consensus with respect to salient disease regions, supporting the clinical interpretability of the network.
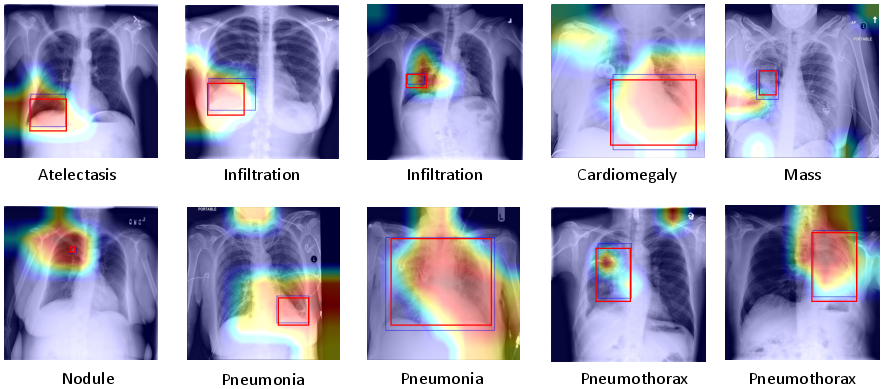
Figure 6: RGT heatmaps (saliency) compared to localization annotations from two radiologist experts, corroborating practical utility and strong agreement on region of interest.
Discussion and Implications
By integrating self-guided radiomics with vision Transformers, this work enables pathology localization and characterization without explicit ROI labeling, addressing a major stumbling block in automated medical image analysis. The architectural design demonstrates that handcrafted, clinically validated features, when appropriately fused with learned representations, can not only provide interpretability but translate to tangible improvements in classification and localization accuracy.
The feedback mechanism in BYOA effectively bootstraps a localization signal from weak disease-level annotations, suggesting further research opportunities in self-supervised or semi-supervised joint representation learning, especially in other medical imaging modalities.
Limitations include the current reliance on coarse saliency maps for bounding box estimation and the use of fixed-size per-class boxes during training, which may not fully capture variable pathology presentations. Future directions could include dynamic or adaptive bounding box generation and exploring richer saliency mechanisms for radiomics region definition.
Conclusion
The RGT framework demonstrates that radiomics-informed, cross-attention Transformer models can achieve strong weakly supervised localization and classification performance in chest X-ray analysis, establishing a more interpretable and clinically relevant foundation for CAD systems. This approach provides a blueprint for incorporating domain knowledge into self-attention architectures, compelling further research in modality fusion, explainability, and interpretable medical AI.