- The paper introduces parallel reasoning that concurrently explores multiple reasoning paths to enhance LLM inference robustness.
- It details the decomposition of queries, parallel processing of subtasks, and aggregation of outputs for improved accuracy.
- The survey evaluates both non-interactive and interactive methods, highlighting efficiency gains and optimization challenges.
A Survey on Parallel Reasoning
Introduction
The paper "A Survey on Parallel Reasoning" explores parallel reasoning as a novel inference paradigm designed to enhance the reasoning robustness of LLMs by concurrently exploring multiple reasoning paths before converging on a final answer. This paradigm is positioned as a complementary methodology to overcome the limitations of traditional sequential reasoning methods that can suffer from a so-called "prefix trap," where models become committed to early reasoning paths, potentially leading to suboptimal solutions. Parallel reasoning aims to tap into a broader scope of a model's problem-solving abilities, mimicking a breadth-first approach.
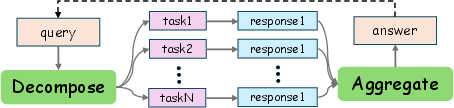
Figure 1: An overall framework for a recurrent parallel reasoning paradigm, highlighting the decomposition, parallel processing, and aggregation phases.
Defining Parallel Reasoning
Parallel reasoning extends inference-time processes, diverging from the sequential Chain-of-Thought (CoT) approach. It can be formally characterized through three stages:
- Decomposition (D): This stage involves breaking down the input query Q into multiple sub-tasks {T1,T2,…,Tn}.
- Parallel Processing (PM): The LLM M is applied concurrently to each sub-task, generating intermediate results.
- Aggregation (A): This operator combines the intermediate results to formulate a single coherent output, providing robustness in reasoning by synthesizing various potential solutions.
Formally, given an input query Q, the parallel reasoning process is expressed as:
Π(Q)=(A∘PM∘D)(Q)
Non-Interactive Parallel Reasoning
In non-interactive settings, each reasoning path is generated and scored independently before aggregation. Key approaches include:
- Self-Consistency: Solutions are voted on, allowing the most frequent outcome among generated samples to be chosen. This method significantly enhances answer reliability by promoting consensus over individual errors but remains computationally intensive.
- Ranking-Based Methods: These utilize verifiers or reward models to score and rank responses, selecting the most promising candidates. This strategy often results in improved decision-making by emphasizing the quality of outputs rather than frequency.
- Structured Reasoning: Techniques such as Tree-of-Thoughts and Graph-of-Thoughts allow the model to navigate and prune solution trees, providing not just improved accuracy but efficiency in paths generated.
Interactive Parallel Reasoning
Interactive methods involve real-time communication between parallel entities, providing dynamic resolutions and corrections during the reasoning process. This is further divided into:
- Intra-Interaction: Different reasoning threads share intermediate outputs within a single model, optimizing the trajectory mid-process, allowing paths to correct and refine collaboratively.
- Inter-Interaction: Models or agents engage dialogically, incorporating diverse viewpoints and corrections, often leading to better reasoning in complex, multifactorial tasks.
Efficiency in Parallel Reasoning
Efficiency is a crucial dimension tackled in parallel reasoning:
- Parallel Decoding: Involves breaking down the task at a token or semantic level and processing them concurrently, significantly reducing the total time needed compared to traditional, fully linear approaches.
- Speculative and Parallel Techniques: These streamline token generation processes by employing drafting and verification strategies, which align intermediate outputs closer to desired results, cutting down on iterative errors.
- Function-Level Parallelism: Enables LLMs to execute external function calls contemporaneously, thereby expediting tasks with inherent parallel dependencies.
Application Domains
The practical applications for parallel reasoning are rapidly expanding, including:
- Grand Challenge Problems: Enhanced parallel reasoning speeds are observed in complex problem areas such as competitive math and coding domains.
- Reliability Enhancement: By leveraging multiple parallel outputs, models become better at mitigating hallucinations and factual inaccuracies.
- Open-ended Tasks: Augments creativity by facilitating diverse perspectives in tasks like creative content generation.
Challenges and Future Directions
Despite the promising advances, parallel reasoning faces several challenges in optimization:
- Performance Bottlenecks: The fundamental constraint of single-path performance upper bounds persists, requiring more sophisticated aggregation strategies.
- Optimization Complexity: Developing holistic, end-to-end training pipelines that effectively leverage candidate pool diversity remains an uphill battle.
Future work should focus on integrating more seamless end-to-end systems that maximize inference efficiency and capitalize on multimodal capabilities, aiming for heightened robustness and richer interactions in LLM application contexts.
Conclusion
"A Survey on Parallel Reasoning" positions parallel reasoning as a pivotal framework to expand the robustness and depth of reasoning in AI models. By transitioning from single-path sequential processing to a broader parallel scope, parallel reasoning frameworks promise enhanced practical performance in AI applications, albeit with significant challenges in training and scalability. This paradigm shift underscores the importance of systemic computational advances and the continuous refinement of reasoning capabilities.