- The paper introduces a taxonomy for multi-step reasoning in LLMs, categorizing the process into generation, evaluation, and control stages.
- The study details methods like Chain-of-Thought prompting and Self-Consistency to improve accuracy and mitigate error propagation in reasoning tasks.
- The survey highlights practical applications across diverse domains and outlines future research directions for integrating symbolic and connectionist approaches.
Multi-Step Reasoning with LLMs: A Survey
This essay provides an authoritative summary of the paper "Multi-Step Reasoning with LLMs, a Survey" (2407.11511). The focus is on exploring the development, methodologies, and implications of multi-step reasoning in LLMs and their application across various domains.
Introduction
The paper opens with an exploration of the limitations of traditional LLMs in addressing reasoning tasks effectively. While LLMs have excelled in tasks such as text generation, natural language understanding, translation, and question answering, they exhibit deficiencies in reasoning benchmarks. The authors identify a crucial gap in the literature pertaining to multi-step reasoning capabilities in LLMs and propose a taxonomy to address this gap.
Taxonomy of Multi-Step Reasoning Approaches
The taxonomy proposed by the authors categorizes reasoning methodologies into three distinct stages: generation, evaluation, and control of reasoning steps. This framework is instrumental in understanding the diverse approaches being employed to enhance the reasoning capabilities of LLMs.
Generation of Steps
The generation stage involves the creation of prompts that guide LLMs to decompose complex problems into simpler sub-tasks. Initially, prompts were manually constructed, as seen in the Chain-of-Thought (CoT) prompting technique, which demonstrated significant improvements in solving math word problems by encouraging step-by-step reasoning.
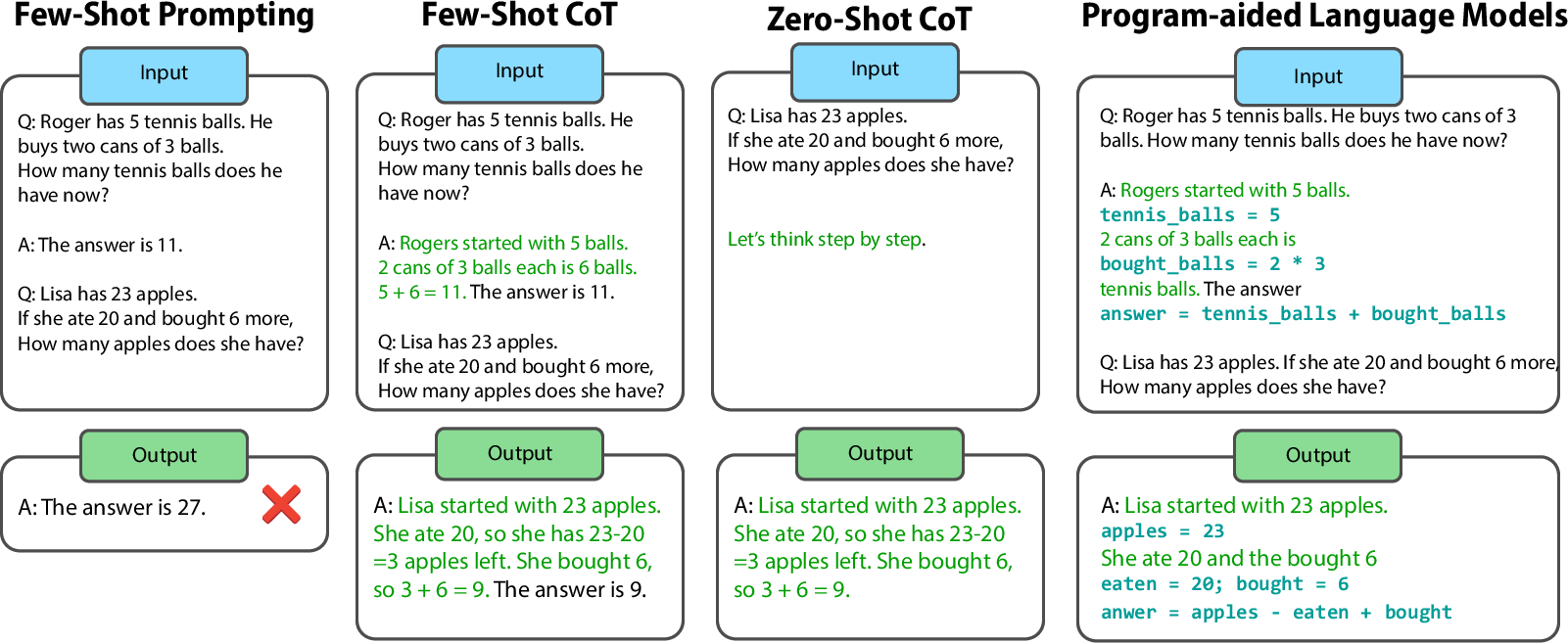
Figure 1: Different chain-of-thought (CoT) prompting techniques. At the top the prompts, at the bottom the answers. When shown the longer example prompt, the LLM follows the longer example when answering the question (Few-Shot CoT).
Subsequent approaches like Zero-Shot CoT further simplified the prompt engineering process by utilizing generic instructions such as "Let's think step by step," demonstrating the zero-shot reasoning capabilities of LLMs.
Evaluation of Steps
Evaluation is crucial for mitigating error propagation in multi-step reasoning. Approaches like Self-consistency employ ensemble methods to improve the robustness of reasoning by considering multiple reasoning paths and selecting the most consistent outcome.
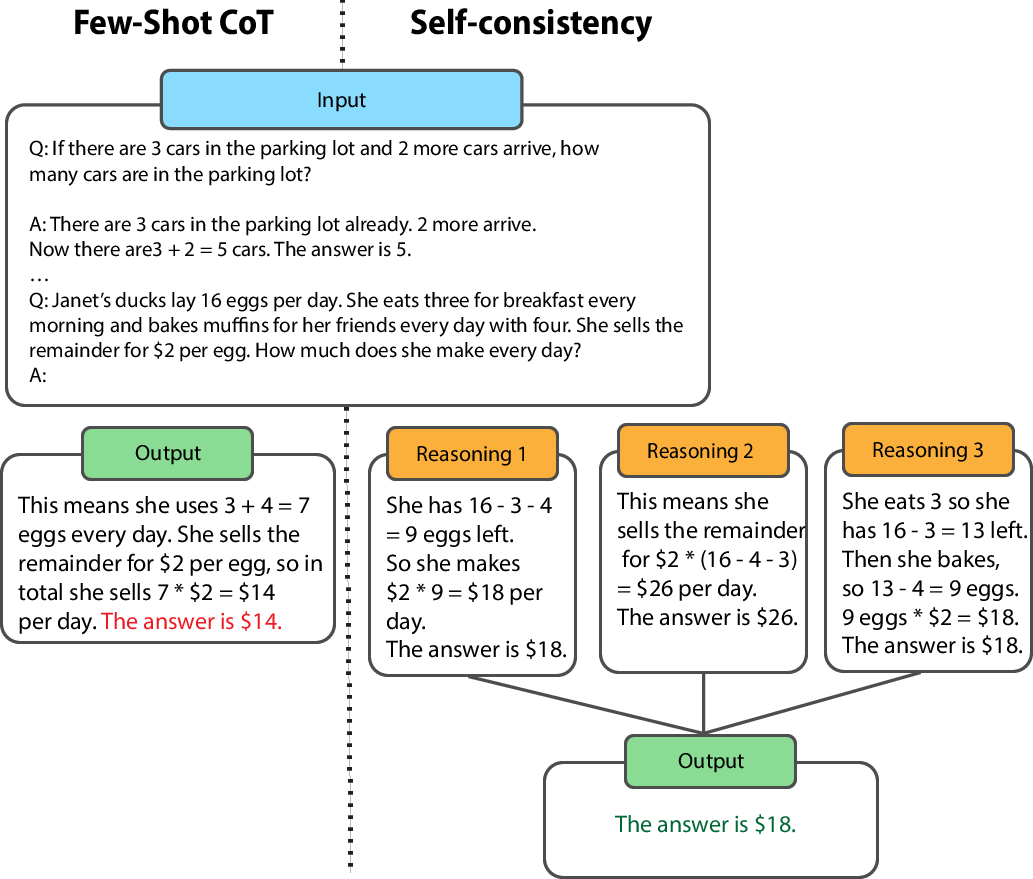
Figure 2: Self-Consistency (Adapted from previous works), showing majority voting over answers that the model produces.
Additionally, tool-based validation leverages formal languages, such as Python, enabling LLMs to generate code for reasoning tasks, which can then be verified using external evaluators, mitigating errors inherent in natural language reasoning.
Control of Steps
The control stage manages the depth and breadth of reasoning steps. Approaches range from simple greedy selection, which follows a linear sequence of reasoning steps, to more sophisticated tree-search strategies like Tree-of-Thoughts. These strategies enable the exploration of multiple reasoning paths, supporting dynamic reasoning processes.
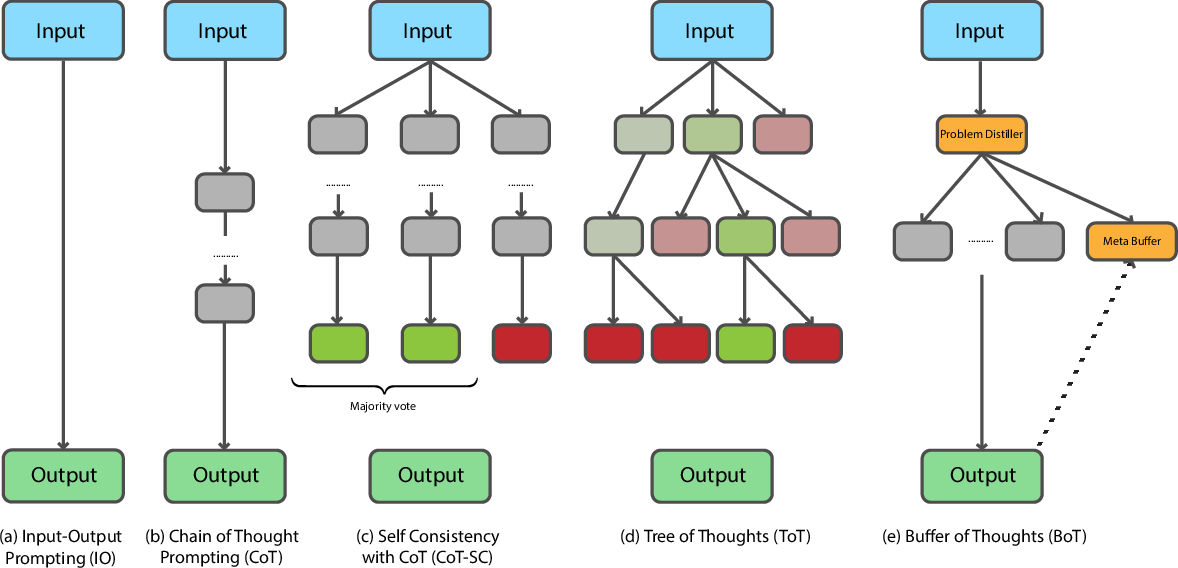
Figure 3: Reasoning structure of Simple prompting (a), Chain-of-thought (b), Self-Consistency (c), Tree-of-Thoughts (d) and Buffer of Thoughts (e); Tree-of-thoughts (d) uses an external prompt-optimizing algorithm to guide the model to perform a tree search over reasoning steps, exploring multiple alternatives.
Practical and Theoretical Implications
The survey identifies significant advancements in reasoning capabilities beyond math problems, extending to domains such as logic, combinatorial games, and robotics. These developments hold promise for enhancing the practical application of LLMs in decision-making and problem-solving tasks across domains.
In a theoretical context, the work highlights the potential for integrating symbolic reasoning with connectionist models, deepening the understanding of how LLMs can be designed to perform complex reasoning tasks.
Future Directions
The paper sets an agenda for future research, advocating for exploration into areas such as in-context reinforcement learning, enhanced grounding of LLM reasoning in real-world contexts, and the potential of smaller, efficient LLMs through knowledge distillation and symbolic integration.
Conclusion
This survey provides a comprehensive overview of the progress and ongoing challenges in multi-step reasoning with LLMs. It underscores the transformative potential of reasoning-enhanced LLMs in solving complex problems through structured approaches involving prompt generation, evaluation, and control, and it sets a path for future exploration and innovation in this rapidly evolving field.