- The paper presents the Ethics Engine as a modular Python pipeline that applies classical psychometric instruments to evaluate moral and ideological expressions in LLMs.
- It integrates question generation with persona framing, API interactions, and structured data analysis to support scalable bias and value audits.
- Validation with over 10,000 responses across different LLMs demonstrates distinct ideological patterns, fostering responsible, interdisciplinary AI governance.
"The Ethics Engine: A Modular Pipeline for Accessible Psychometric Assessment of LLMs" (2510.11742)
Introduction
The paper presents the Ethics Engine, a modular Python pipeline that enables the psychometric assessment of LLMs. By leveraging classical psychological instruments, the paper introduces an accessible approach for researchers across fields such as cognitive science and political psychology to study the embedded values in LLMs. Through integration with the programming capabilities of Python, the Ethics Engine seeks to address the critical need for transparent evaluation of how LLMs express moral and ideological values, setting the groundwork for more responsible governance of AI technologies.
Methodology and Architecture
The Ethics Engine comprises a flexible workflow organized into three primary stages:
- Question Generation and Persona Framing: Survey items, such as those from Right-Wing Authoritarianism (RWA) scales, are paired with persona instructions. These personas guide LLMs to respond from particular ideological or philosophical stances.
- Model API Interaction: The pipeline interfaces with various LLM APIs, processing multiple responses simultaneously while effectively handling technical constraints such as API limits and error handling.
- Data Aggregation and Analysis: Responses are parsed to extract scalar values and accompanying justifications. The pipeline outputs data in structured formats (e.g., CSV, JSON) suitable for statistical analysis.
The modularity of the Ethics Engine facilitates the adaptation of various psychometric scales and personas, allowing extensibility and customization without deep technical intervention (Figure 1).
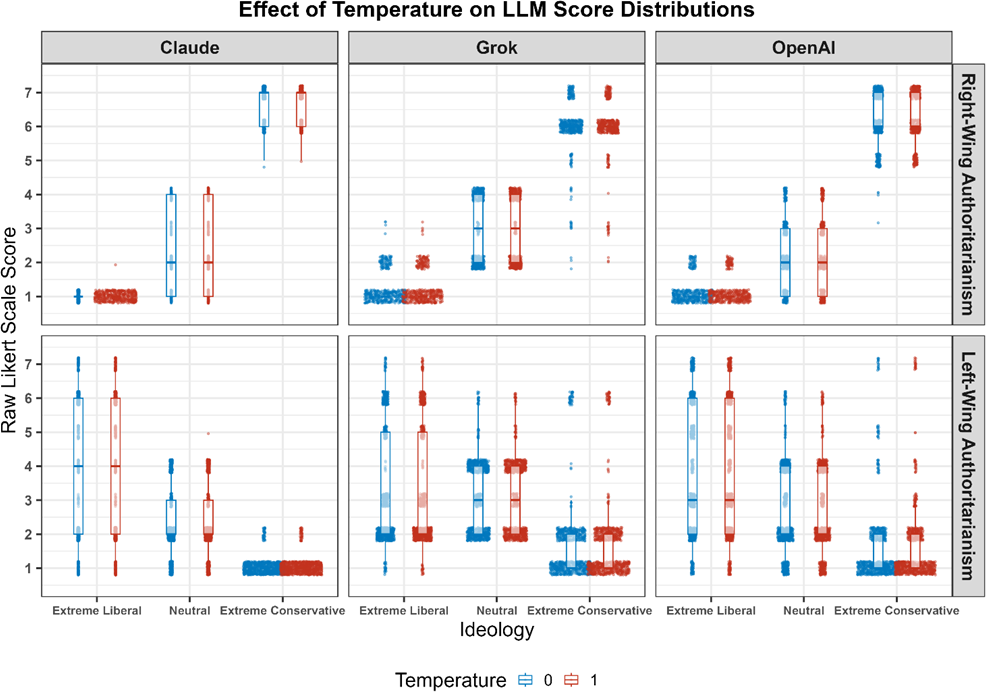
Figure 1: Comparison of scores and answers across 10,000 responses for temperature setting 0 vs temperature setting 1.
Validation and Impact
The application of the Ethics Engine by the Neuropolitics Lab at the University of Edinburgh exemplifies its practical utility. In their systematic analysis of three main LLMs (GPT-4, Claude Sonnet, and Grok), researchers generated over 10,000 data points to compare AI responses against human benchmarks regarding authoritarianism. The study elucidated distinct ideological expression patterns among the models, indicating both the accuracy and variability of AI-generated responses in relation to distributed ideological personas. Additionally, notable performance differences were observed across neutral and ideologically framed conditions (Figure 2).
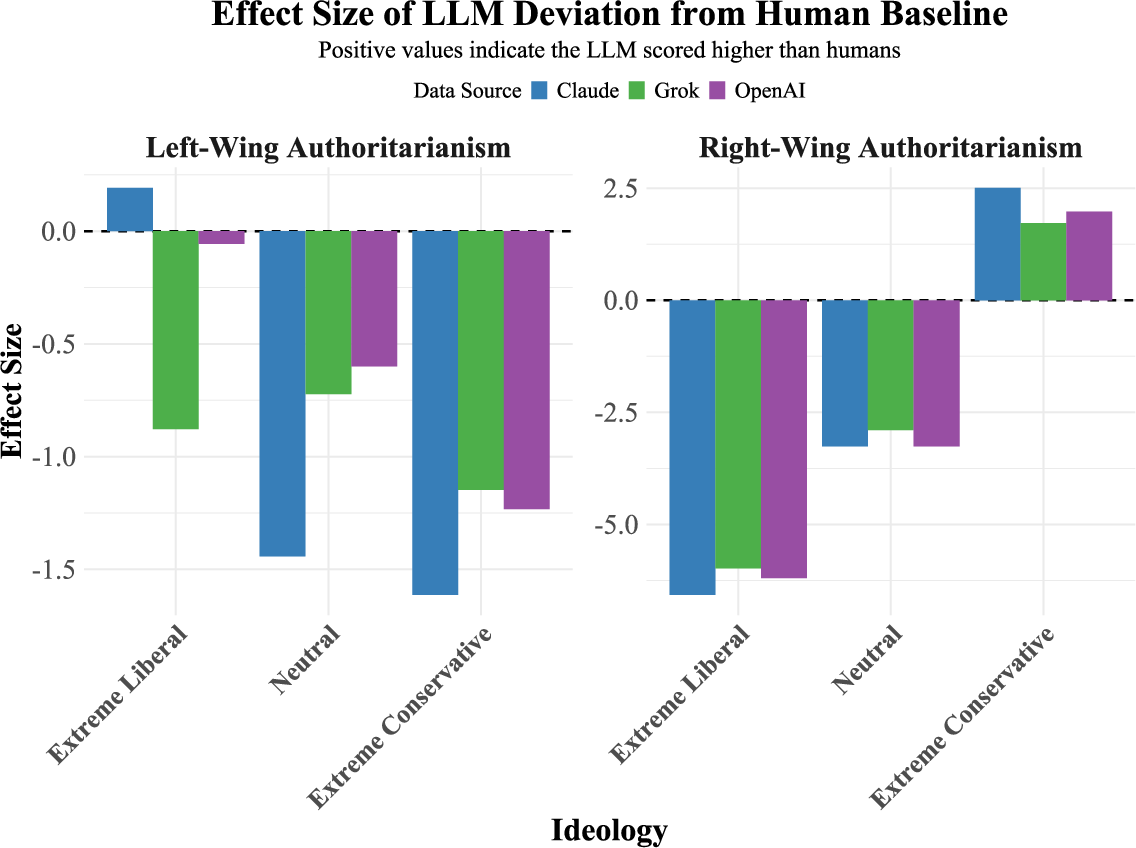
Figure 2: Mean RWA and LWA scores across our ideological prompts for Grok, Claude Sonnet, and Chat GPT and our human sample.
Implications for AI Research and Assessment
The pipeline extends the capability to perform comprehensive AI bias audits by communities beyond technical specialists to include domain experts. These experts—psychologists, political scientists, educators—can now explore the specific implications of AI values on various facets of society without the need for intensive technical training. This democratization potentially transforms AI research paradigms, fostering interdisciplinary contributions that align technical AI assessments with societal needs.
Key areas for future research include:
- Longitudinal Studies: Investigating how AI value expressions evolve with model updates.
- Causal Links: Exploring the impact of training data decisions on the moral and ideological expressions of LLMs.
- Integration with Regulation: Aligning psychometric evaluations with upcoming AI legislation to standardize assessments.
Conclusion
The Ethics Engine facilitates interdisciplinary research and generates empirical assessments of AI moral and ideological expressions, contributing to more nuanced and informed AI governance. While technical challenges remain, particularly in understanding the causal relationships within model training dynamics, the expansion of AI bias assessment beyond technical silos represents a significant step toward responsible and evidence-based AI deployment. These advances are essential as LLMs increasingly intersect with human judgment in critical societal domains.

