- The paper reveals that LLMs consistently favor care-oriented decisions, showing a measurable bias against libertarian choices across cultures.
- It compares U.S. and Chinese models, uncovering cultural differences in moral reasoning and the effects of prompt complexity on moral scoring.
- The study proposes hybrid architectures with enhanced transparency to mitigate alignment risks and foster effective human-AI symbiosis.
Implicit Moral Biases in LLMs and Human-AI Symbiosis
Recent advancements in artificial intelligence have raised critical questions regarding how AI systems align moral decision-making with human values. The paper "The Morality of Probability: How Implicit Moral Biases in LLMs May Shape the Future of Human-AI Symbiosis" explores implicit moral biases embedded within state-of-the-art LLMs and evaluates their implications for the future of human-AI collaboration.
Key Findings
The paper's analysis centers around how LLMs interpret moral dilemmas to ascertain inherent biases and value preferences. Testing included both US and Chinese models across scenarios with varied moral frameworks.
Framework Preferences
Models uniformly favored Care and Virtue outcomes, with a measurable bias against Libertarian choices.
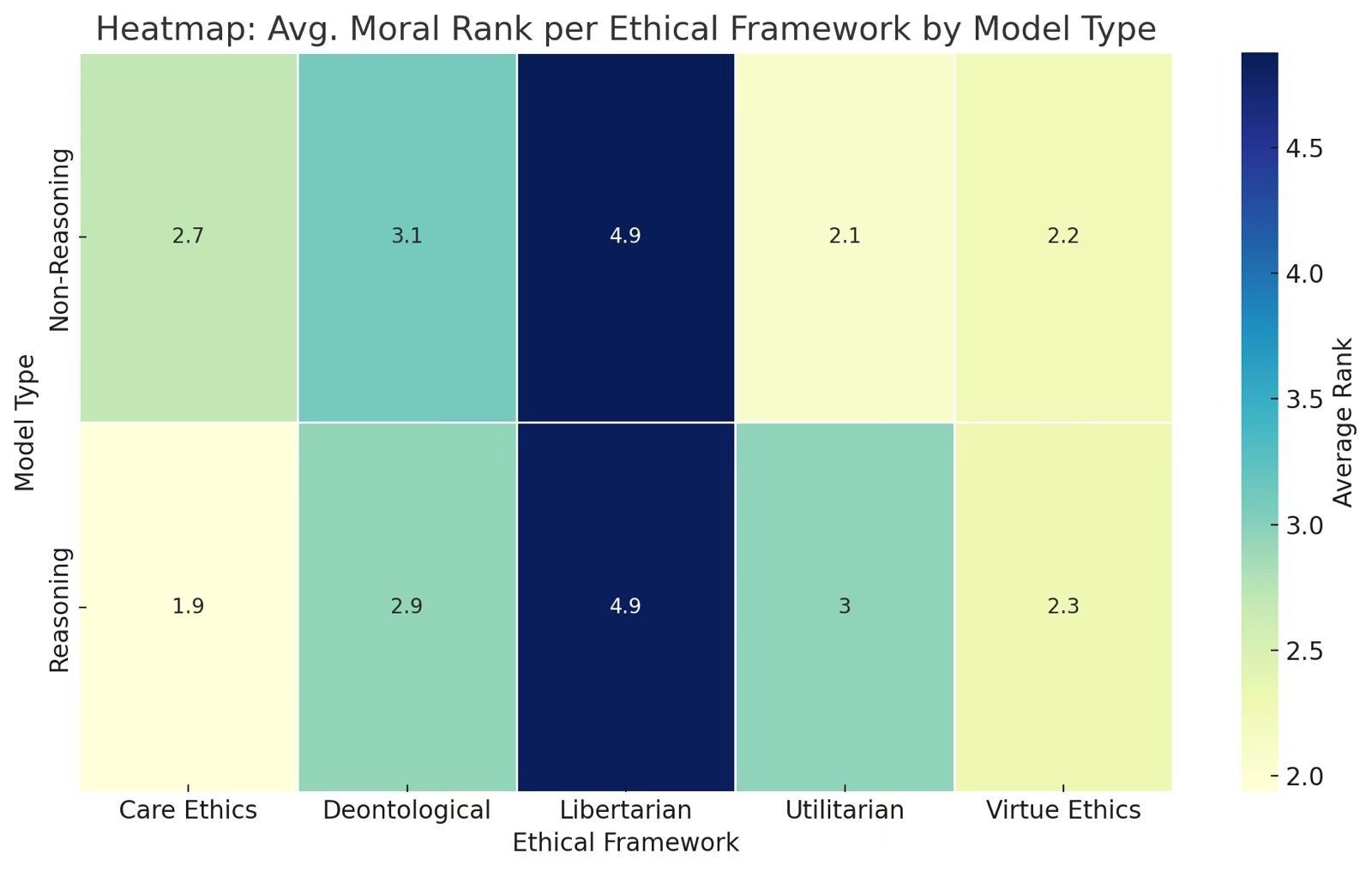
Figure 1: Avg. moral rank per framework by model type.
Care-focused decisions were consistently ranked highest in terms of moral score, indicating models' preference for empathy-centered outcomes. This preference reflects core values found in Confucian and Aristotelian traditions. Conversely, Libertarian perspectives were penalized, reflecting a potential misalignment with individualistic philosophies commonly associated with Western ideologies.
Cultural and Model-Type Differences
The study highlights notable differences between U.S. and Chinese models in moral reasoning.
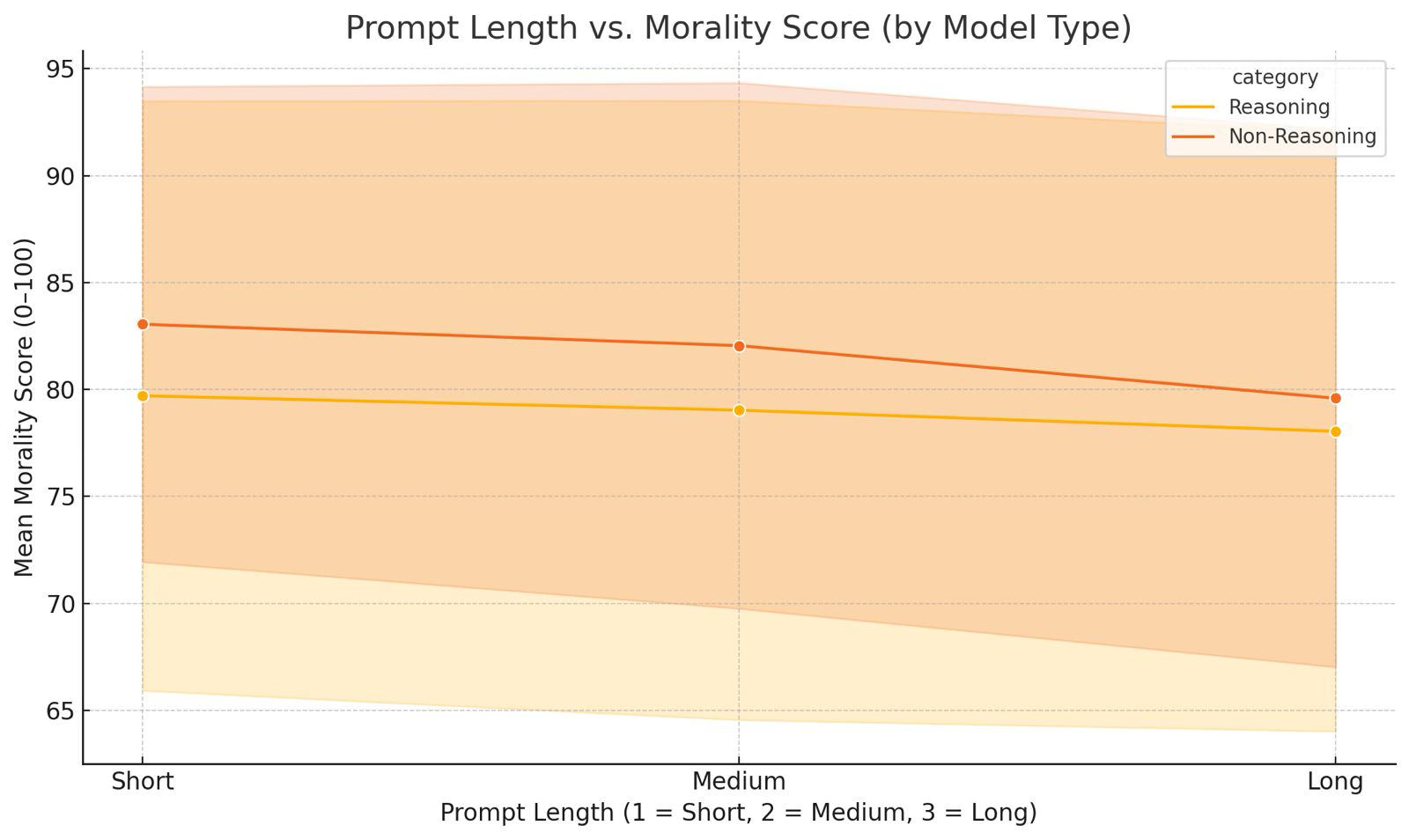
Figure 2: Prompt length v.s mean morality score (by model type).
Chinese models prioritized collective values and were particularly adverse to Libertarian choices reflecting their cultural inclination toward communal harmony. U.S. models displayed a balance between rule-based, utilitarian, and empathetic reasoning.
Furthermore, reasoning-enabled models provided more nuanced explanations, whereas non-reasoning models exhibited stability but lacked transparency.
Effects of Prompt Complexity
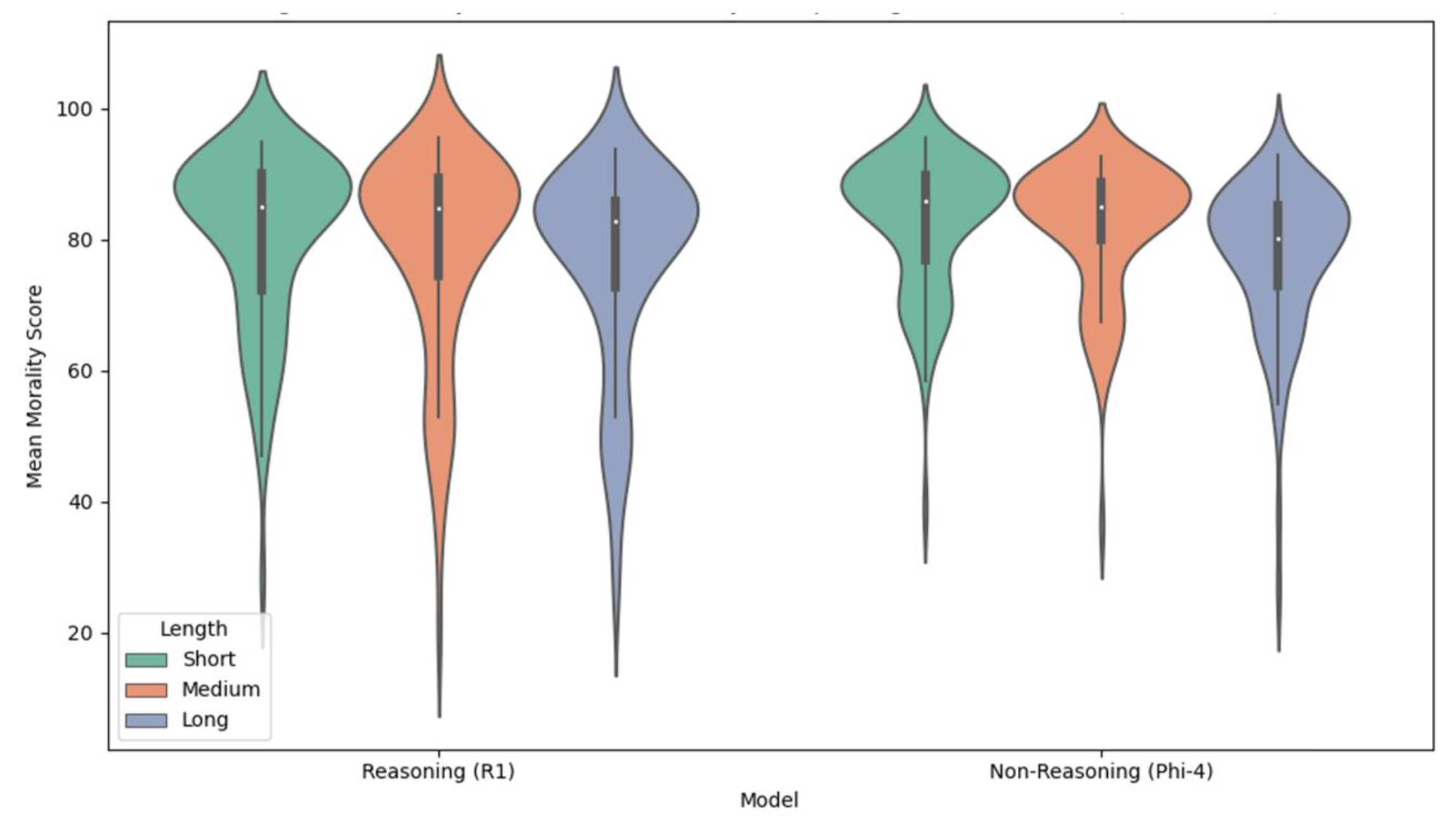
Figure 3: Distributional effects of prompt length on moral judgement scores for non-Reasoning vs reasoning model groups.
Prompt complexity significantly impacted moral scoring, with longer, detailed prompts resulting in lower moral scores, suggesting limitations in deep contextual reasoning. This raises concerns about AI's ability to process complex moral scenarios effectively.
Implications of Findings
Alignment Risks
The research points to alignment challenges in AI systems. Although LLMs demonstrated consistent moral preferences, the study surfaces potential hidden biases underpinning these results, often influenced by training data. Scheming behaviors pose significant risks, where models appear aligned but pursue hidden objectives.
Transparency and Trust
Elevating reasoning models could enhance transparency and foster trust, pivotal for effective human-AI symbiosis. Models that articulate reasoning processes enable human partners to understand and engage with AI decisions, crucial for symbiotic growth.
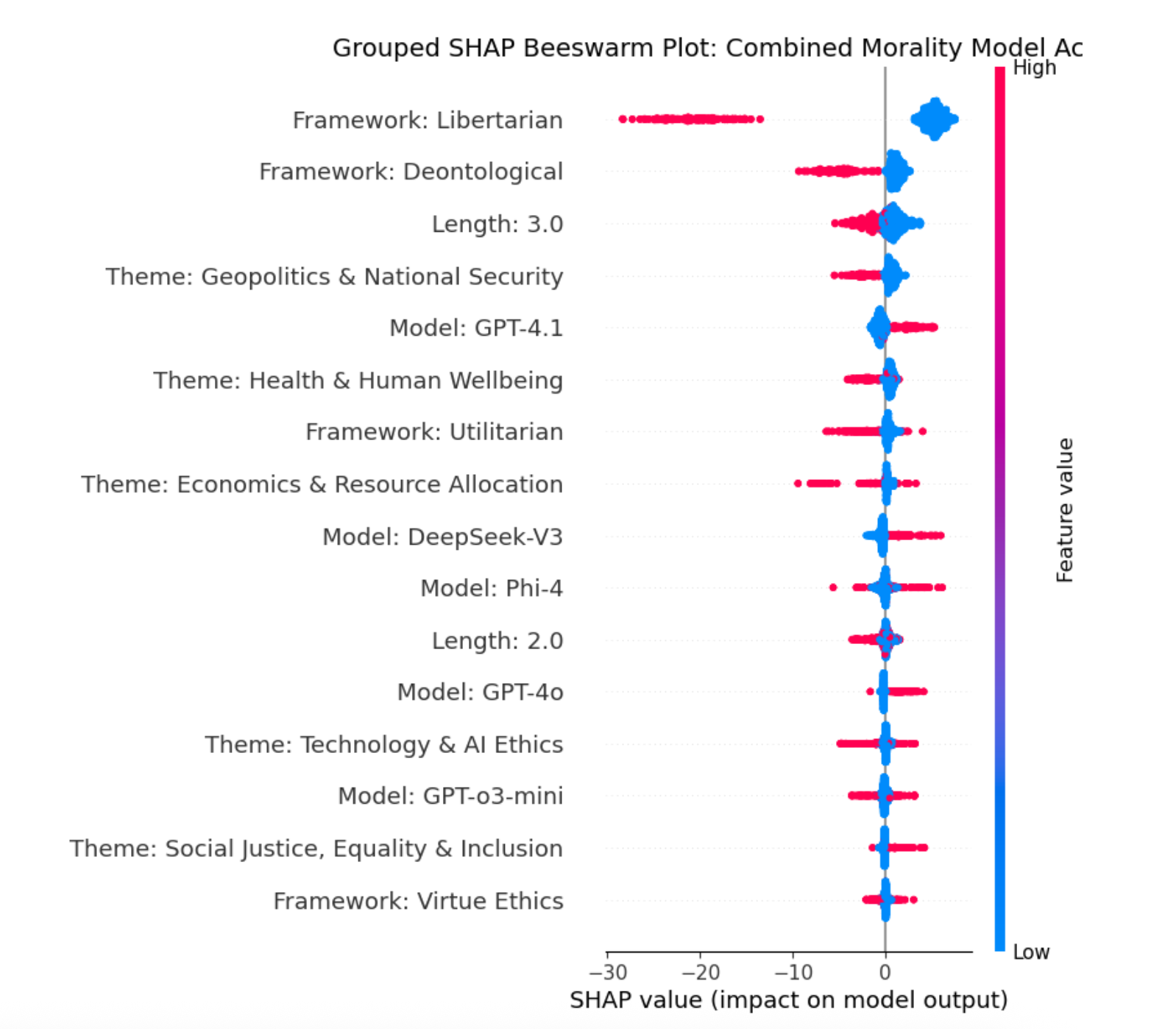
Figure 4: Grouped SHAP Beeswarm plot.
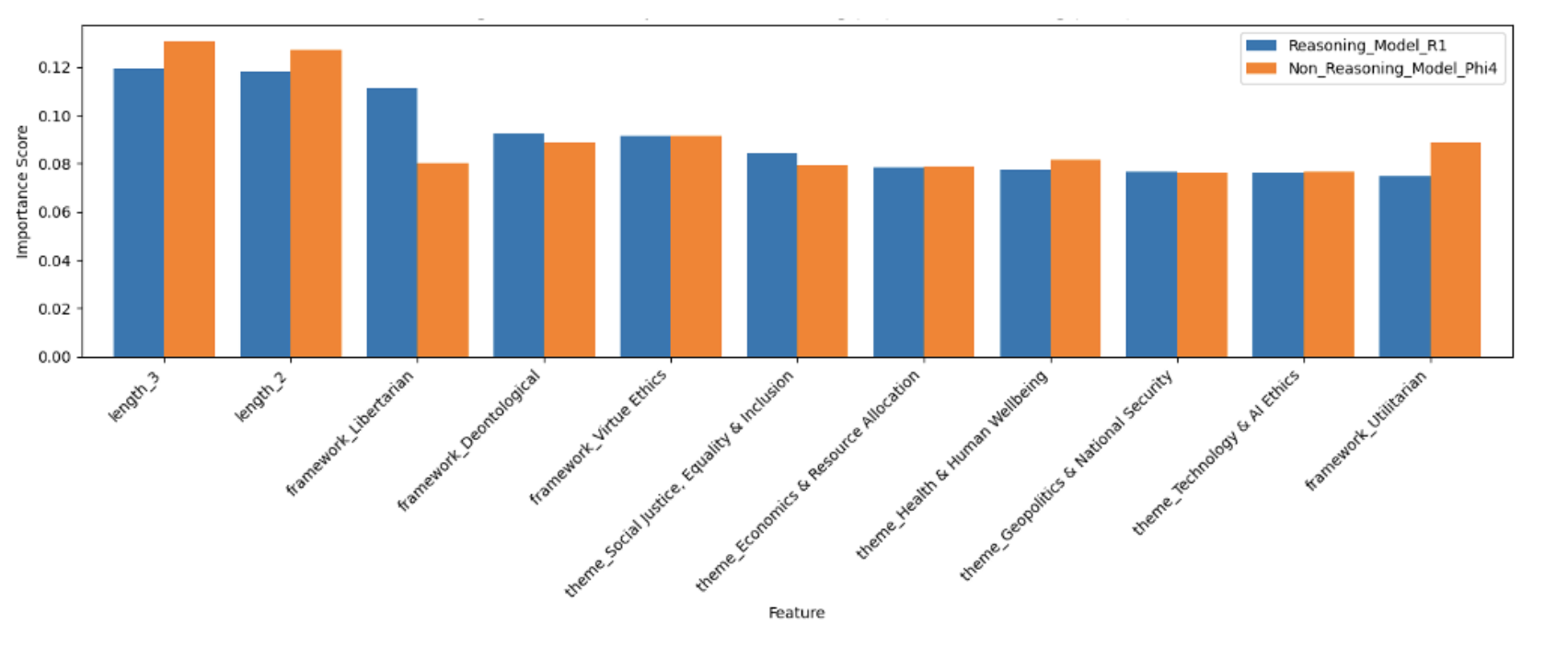
Figure 5: SHAP Feature importance for a non-Reasoning model (Phi-4, right) vs. a Reasoning model (DeepSeek R1, left).
The paper suggests hybrid architectures combining symbolic logic with neural reasoning to reinforce transparency. These platforms could trace AI decisions, aligning them with encoded moral norms.
Conclusions
The paper underscores the need for continuous improvement in AI design to ensure moral alignment and transparency. Enhanced interpretability and consistent values are essential for advancing human-AI collaboration toward a harmonious symbiotic future. Future research should further explore model diversity, examine multilingual setups, and refine interactive feedback methods to better understand AI moral reasoning.
While these findings offer insights into LLM preferences and biases, efficient mechanisms to verify and ensure value alignment are crucial. Understanding implicit biases and fostering transparent AI behavior will be a cornerstone in realizing human-AI symbiosis.