- The paper demonstrates that gold utilitarian passages tailored to specific LLMs yield superior RAG performance versus generic human annotations.
- It presents a comprehensive benchmarking framework using set-based and ranking-based evaluations with pseudo-answer injection to assess passage utility.
- The findings imply that retrieval systems must adapt to individual LLM characteristics, as utility is non-transferable and overcontextualized passages can hinder performance.
LLM-Specific Utility in Retrieval-Augmented Generation: Technical Summary and Perspective
Introduction
The paper "LLM-Specific Utility: A New Perspective for Retrieval-Augmented Generation" (2510.11358) rigorously interrogates the widely-held assumption in Retrieval-Augmented Generation (RAG) research that passage utility is a generic, model-agnostic property. Instead, the authors introduce and define LLM-specific utility—the notion that the usefulness of retrieved passages is inherently LLM-dependent, determined by each model’s internal knowledge base and comprehension capacity. Through comprehensive benchmarking across multiple datasets and LLM architectures, the study demonstrates that passages deemed generally relevant by human annotators are frequently suboptimal for specific LLMs and, importantly, that gold utilitarian passages for one model are not transferable to others. These findings challenge static, human-aligned evaluation paradigms and suggest model-personalization is essential to maximizing RAG performance.
Core Findings and Numerical Results
Hyper-parameterized experiments using four LLMs (Qwen3-{8B,14B,32B} and Llama3.1-8B) and six knowledge-intensive datasets elucidate several main results:
- Gold utilitarian passages—identified as passages that increase answer accuracy for a given LLM compared to its generation without context—yield consistently superior RAG performance over human-annotated passages. For example, on NQ, Qwen3-32B achieves 82.16% with its own gold utilitarian passages versus 73.60% with human annotation.
- This utility is non-transferable across LLMs. An LLM achieves maximal accuracy when provided gold utilitarian passages identified for itself; using another’s reduces effectiveness (see heatmap analysis).
- The overlap between human annotation and LLM-specific utility is partial (~50% for NQ/MS MARCO-FQA). Not all human-labeled relevant passages enable answer improvement for any given LLM.
- Perplexity analysis shows LLMs assign lower PPL to passages within their specific gold utilitarian set, supporting the hypothesis that model-readability and internal representation capacity modulate utility.
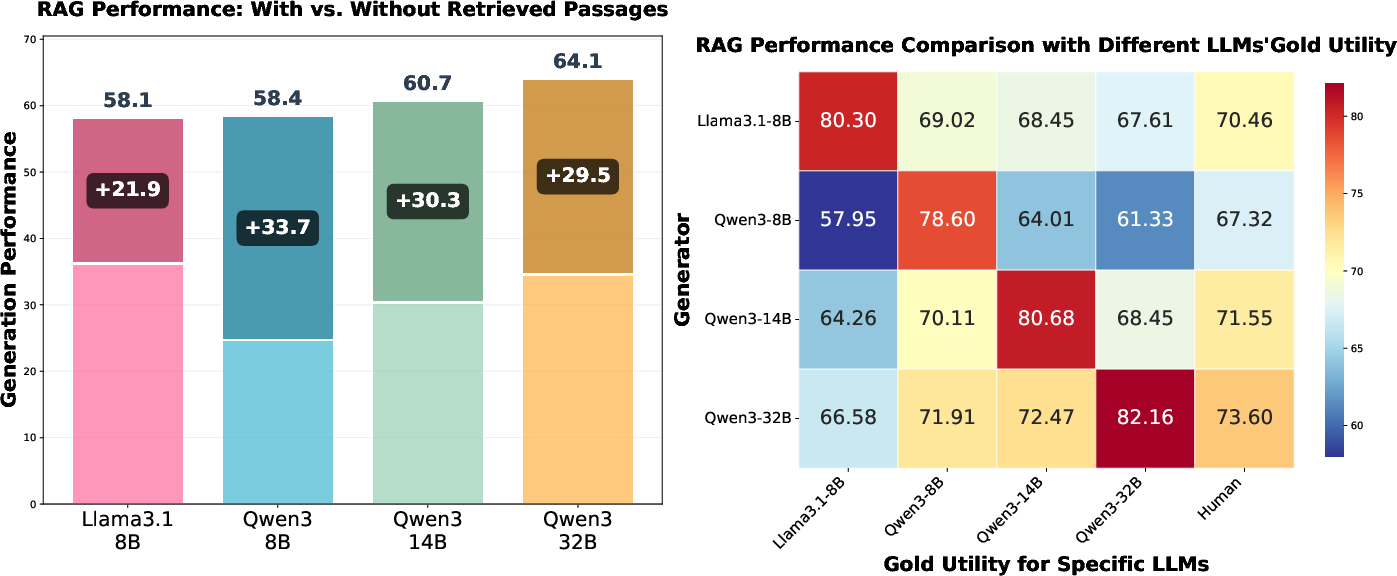
Figure 1: Left: Substantial variance in RAG answer rates among LLMs given identical retrieval; Right: RAG performance gains only with model-specific gold utilitarian passages, confirming non-transferability.
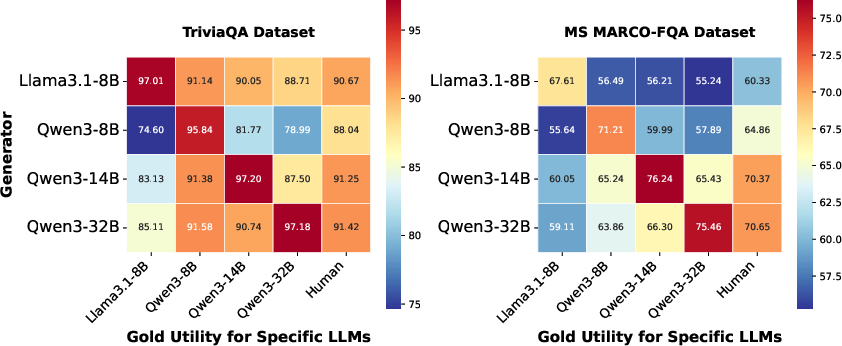
Figure 2: RAG performance of LLMs sharply peaks when using gold utilitarian passages identified by the target LLM, regardless of dataset.

Figure 3: The mean intersection between LLM-specific gold passages and human annotations is less than 50%, emphasizing selective utility.
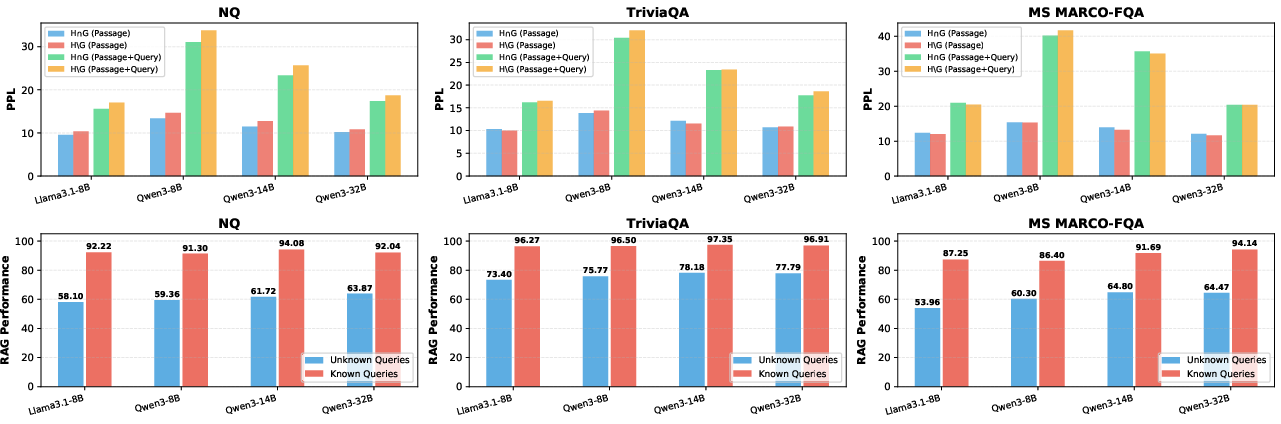
Figure 4: Top: Perplexity (PPL) of LLMs is markedly lower on gold utilitarian passages vs. generic human-annotated ones. Bottom: Human-annotated passages sometimes decrease RAG performance for queries already fully answerable by the model’s parametric memory.
Methodology: Benchmarking LLM-Specific Utility Judgment
The paper formalizes LLM-specific utility judgment as a benchmark task. For each query, gold utilitarian passages are built using a binary indicator of answer improvement relative to no-passage generation. Two evaluation regimes are defined:
- Set-based: Subset selection, measured via Precision, Recall, F1, and Accuracy for cases with/without gold utility.
- Ranking-based: Ordering passages by utility, assessed using NDCG and Recall@K.
Multiple passage selection and ranking mechanisms are compared:
- Verbalized judgment: Prompting LLMs to select or rank passages either pointwise or listwise, with or without reference to pseudo-answers.

Figure 5: Prompts for pointwise and listwise utility judgment, showing schema for query-plus-candidate selection.
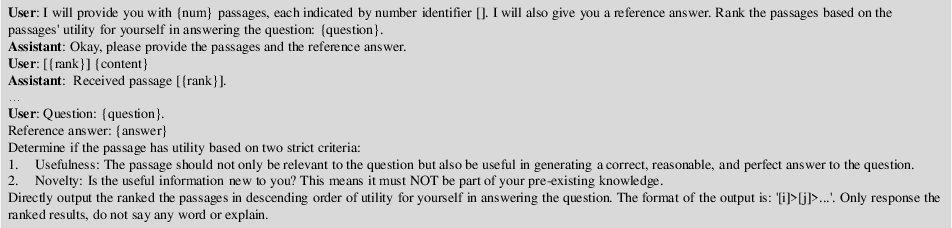
Figure 6: Listwise ranking prompt structure for LLM utility assessment.
- Attention-based estimation: Scoring passages by decoding-time attention weights, found to be a poor proxy.
- Likelihood-based estimation: Utilizing the probability of a pseudo-answer conditioned on the passage.
- Pseudo-answer injection: Pre-generating answers from retrieved candidates and supplying them to the model for utility evaluation, shown to robustly improve passage selection and ranking accuracy.
Empirical results demonstrate several strong patterns:
- Model-aware selection (verbalized with pseudo-answers) outperforms conventional reranking and generic retrievers (e.g., BGE-M3), across datasets. Listwise selection is systematically superior to pointwise.
- For queries answerable without retrieval ("known"), providing even relevant passages can decrease performance, indicating over-reliance on context and potential misalignment between internal model state and supplied evidence.
- Family proximity (e.g., Qwen3 variations) increases passage-set overlap, but maximal accuracy remains bound to strictly the target model’s own utilitarian set.
- Attention-based heuristics underperform drastically, substantiating that attention distributions do not encapsulate factual utility in RAG.
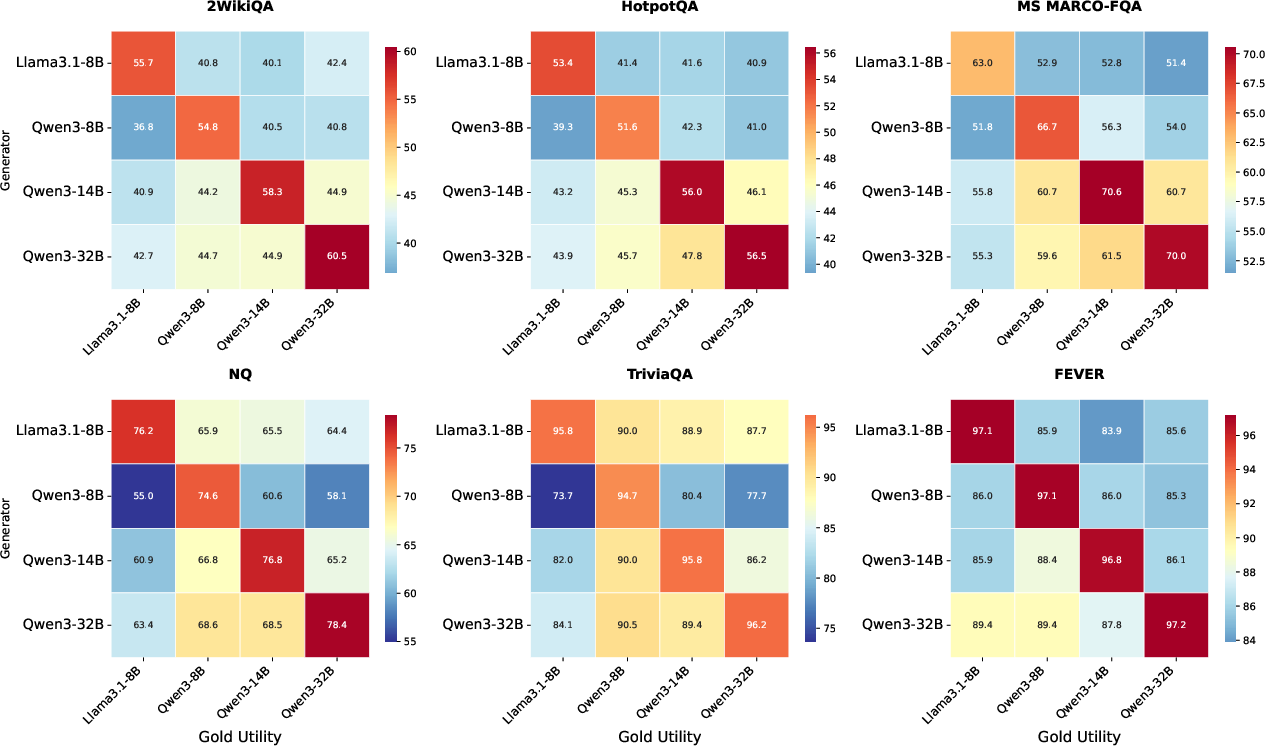
Figure 7: Heatmap of RAG performance when using top-20 gold utility passages from different models, further substantiating non-transferability and need for model alignment.
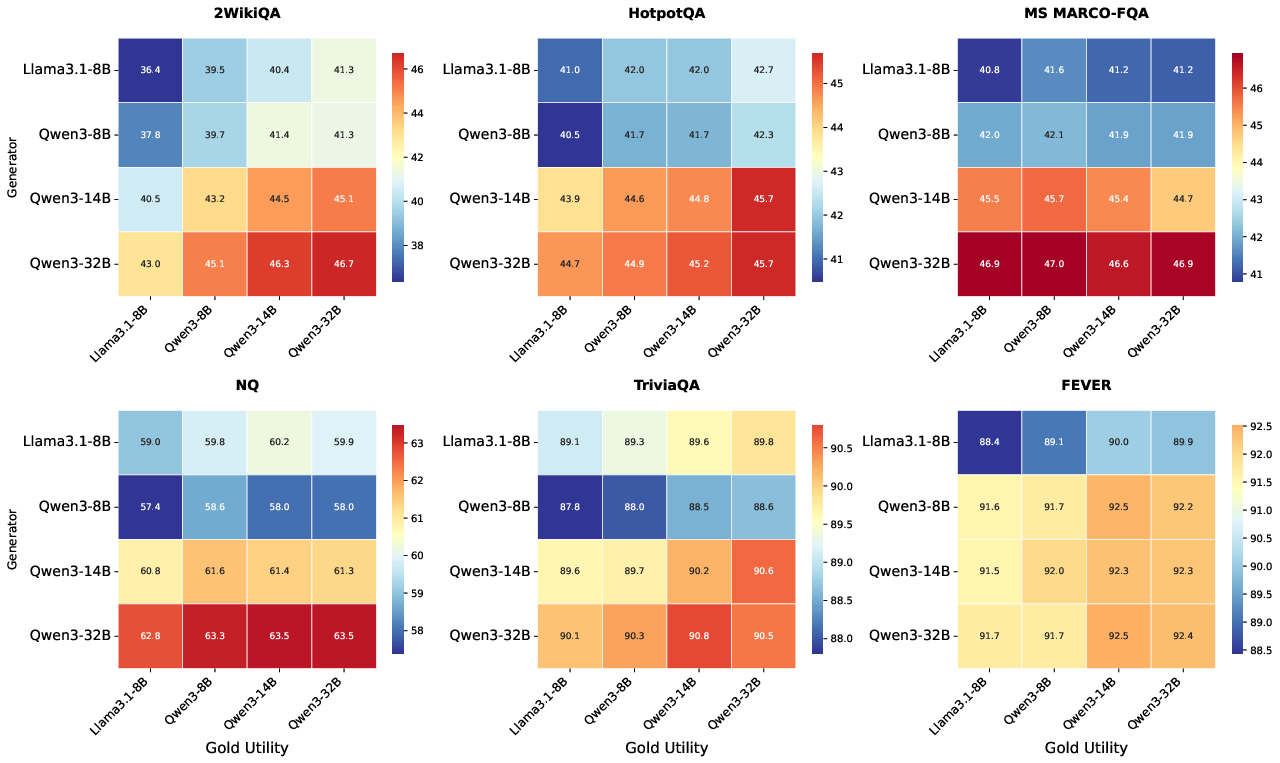
Figure 8: RAG accuracy when utility judgments (verbalized listwise w/ pseudo-answer) from varied models are used, demonstrating partial transferability though accuracy peaks with self-aligned judgments.
Theoretical and Practical Implications
These results dismantle the assumption of universal passage utility, presenting major implications:
- Benchmarking and evaluation in RAG must shift from generic, human-centric passage annotation toward dynamic, model-specific utility assessment.
- Retrieval systems must be personalized and calibrated for downstream LLMs, potentially via distillation, curriculum learning, or feedback loops as suggested by cited methods [zhang2025distilling] [zhang2025leveraging].
- Knowledge organization and passage reranking algorithms are pressured to account for both model-parametric knowledge and comprehension idiosyncrasies, not simply topic relevance.
- Future work should focus on lightweight, efficient utility predictors attuned to target LLMs, and mechanisms for direct passage rejection when internal knowledge suffices (mitigating overcontextualization errors).
Limitations and Future Research Directions
Several open questions remain:
- Developing utility judgment protocols that reliably reject all passages for known queries, not only select for unknowns, remains unsolved—even with advanced prompts and pseudo-answer strategies, recall and F1 are degraded in strict rejection settings.
- Establishing optimal strategies for utility distillation into retrieval models and selectors for new, unseen LLM architectures.
- Expanding benchmarks to include multi-hop reasoning and tasks where fine-grained passage selection and ordering may yield less binary or more continuous utility functions.
Conclusion
This work reorients RAG research from generic, relevance-centric annotation to LLM-specific utility, validating that only model-personalized passage sets maximize answer generation accuracy. Static general utility sets are sharply suboptimal and non-transferable. Rigorous benchmarks and suite of selection and ranking techniques illustrate that verbalized pseudo-answer-based methods are most effective, and that RAG paradigms must become attuned to the knowledge and comprehension gaps of their target models. Critical future directions entail designing utility functions and retrievers that dynamically adapt to model-specific needs and reliably distinguish context necessity for answering.