- The paper introduces W-RAG, a framework that utilizes LLM-generated weak labels to improve dense retriever training in RAG for OpenQA.
- It reranks BM25-retrieved passages using LLMs, converting answer likelihood into effective training signals for DPR and ColBERT models.
- Experiments on MSMARCO, NQ, SQuAD, and WebQ validate significant recall improvements, demonstrating the framework’s practical impact on OpenQA.
"W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering"
The paper "W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering" proposes an innovative framework that tackles the challenges associated with training dense retrievers for Retrieval-Augmented Generation (RAG) systems in Open-domain Question Answering (OpenQA). By employing weak supervision through LLM-generated labels, the study offers a practical approach to improve retrieval and answering capabilities without relying heavily on costly human annotations.
Introduction and Methodology
In knowledge-intensive applications like OpenQA, LLMs invariably encounter limitations in accessing up-to-date and factual information purely through their parametric knowledge. The RAG architecture mitigates these limitations by leveraging external knowledge sources, thus enhancing LLMs' capabilities in generating accurate answers. Dense retrieval methods, although effective, suffer from the scarcity of annotated data.
W-RAG is introduced as a solution to these challenges, employing a process where the top-K passages retrieved via BM25 are reranked by an LLM. The reranking is based on the likelihood of generating the correct answer from each passage. The top-ranking passages are used as weakly labeled positive examples for training dense retrieval models, principally DPR and ColBERT architectures.
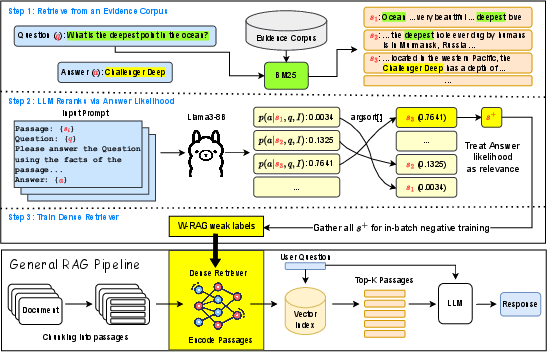
Figure 1: W-RAG fits into the general RAG pipeline by training the retriever with LLM generated weak labels.
Weak-label Generation
W-RAG's label generation process employs the ranking potential of LLMs by querying them with passages, questions, and a ground-truth answer. An autoregressive LLM evaluates each passage's capability to yield the answer based on the provided context and generates a ranking score that guides the dense retrieval training. By focusing on passage relevance defined by answer likelihood, W-RAG creates a dataset conducive for training effective retrievers, shifting the traditional paradigm from semantic similarity to practical answer retrieval capability.

Figure 2: Prompts used for weak label generation and question answering.
Results and Evaluations
The experiments conducted across distinct OpenQA datasets, namely MSMARCO, NQ, SQuAD, and WebQ, highlight the efficacy of W-RAG in improving both retrieval and OpenQA performance. The experiments demonstrate consistent improvements in recall metrics, validating the approach's capability to effectively rerank candidates and thus train more competent dense retrievers than traditional unsupervised methods. The robust evaluation validates the hypothesis that leveraging weak labels derived from LLMs can significantly bridge the gap between unsupervised and supervised retrieval methods.
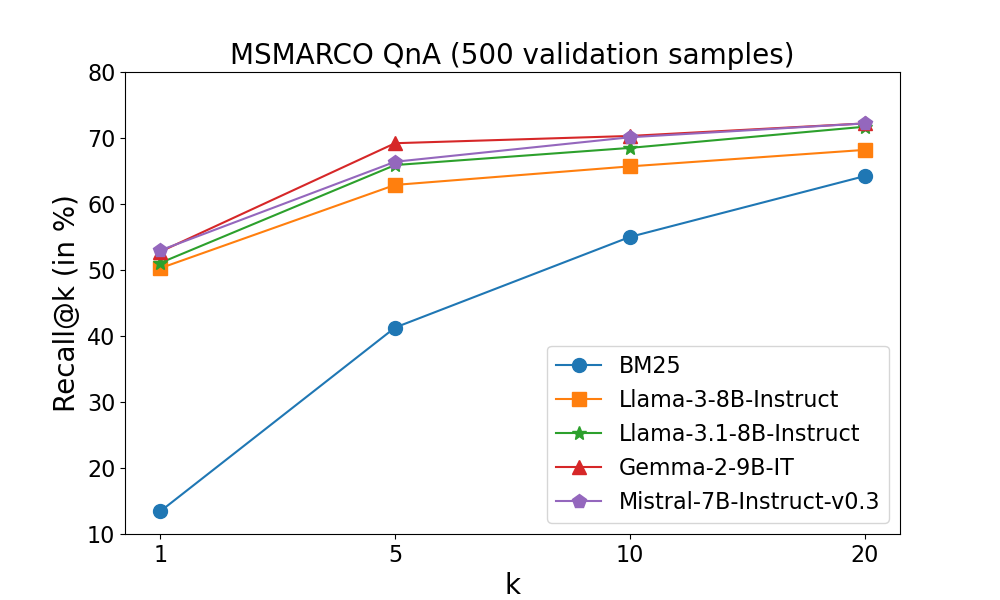
Figure 3: Comparison of recall for various LLMs at different top k positions, when reranking top 100 passages retrieved by BM25.
Implications and Future Work
The W-RAG framework sets a precedent for employing LLMs in a meta-supervisory capacity, generating labels for training dense retrieval systems cost-effectively. This methodological advancement facilitates scalable and responsive OpenQA systems capable of leveraging live and dynamic information from external sources more effectively.
Future research can further investigate the types of retrieved passages that optimize RAG system performance, probing into different structures and scoring mechanisms in retrieval systems. The use of adaptive passage compression techniques could also be explored to mitigate complexity and noise, enhancing inference efficiency within RAG frameworks.
Conclusion
The W-RAG framework delineates a promising direction for OpenQA by innovating the training paradigm for dense retrieval systems, alleviating dependency on exhaustive human annotations. Through research in weak supervision methodologies, it charts a viable path for scalable and effective integration of external information sources with LLMs, catalyzing advancements in real-world OpenQA applications.