- The paper introduces a quantifiable measure of the distracting effect, defining how irrelevant passages mislead LLMs in RAG systems.
- It demonstrates that answer-skewed retrieval and generated modal passages are especially effective at producing distracting influences.
- Fine-tuning with these distracting passages improves RAG accuracy by up to 7.5%, underscoring the value of diverse distractor methods.
Analyzing the Distracting Effect of Irrelevant Passages in RAG Systems
Retrieval Augmented Generation (RAG) systems enhance LLMs by grounding their responses on retrieved passages, reducing hallucinations. However, irrelevant passages can mislead the LLM, a phenomenon this paper formalizes as the "distracting effect." The paper introduces a quantifiable measure for this effect and explores methods to identify and leverage distracting passages to improve RAG robustness.
Quantifying the Distracting Effect
The distracting effect, DEq(p), of a passage p with respect to a query q is defined as the probability that an LLM does not abstain from answering the query based on the irrelevant passage. This is formalized as:
DEq(p)=1−pLLM(NO-RESPONSE∣q,p)
where pLLM(NO-RESPONSE∣q,p) represents the probability assigned by the LLM to the "NO-RESPONSE" token when prompted with the query and passage. A high DEq(p) indicates a strong distracting effect, meaning the LLM is likely to generate an answer based on the irrelevant passage. The authors emphasize that this measure isolates the effect of the passage itself and is robust across different LLMs, as demonstrated by high correlation scores (Figure 1).
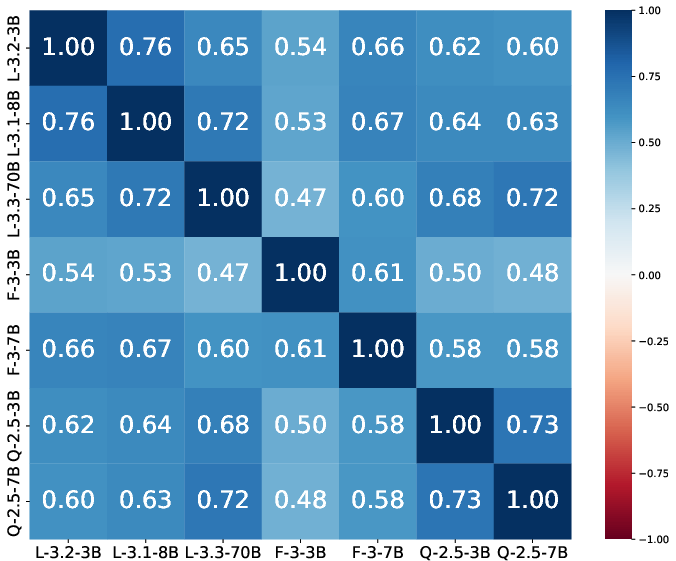
Figure 1: Spearman correlation of distracting effect computed using different LLMs (abbreviated, e.g., Llama → L). The strong correlations suggest that the distracting effect of a passage is relatively consistent across models despite architectural differences.
Methods for Obtaining Distracting Passages
The paper explores two primary approaches for obtaining distracting passages: retrieval and generation.
Retrieving Distracting Passages
The first approach involves retrieving candidate passages using standard and answer-skewed retrieval methods. Answer-skewed retrieval modifies the query embedding to retrieve documents related to the query but unrelated to the answer. The query embedding is modified as follows:
$E^{\text{sub}(q,a) = E_Q(q) - \lambda E_D(a)$
or
$E^{\text{proj}(q,a) = E_Q(q) - \lambda \frac{\left\langle E_Q(q), E_D(a) \right\rangle E_D(a)}{\left\|E_D(a)\right\|^2}$
where EQ(q) and p0 are embedding functions for the query and answer, respectively, and p1 is a hyperparameter controlling the aggressiveness of excluding answer-related documents. The top-ranked irrelevant passages from these retrieval systems are considered as potential distractors. It was shown that higher-ranked irrelevant results are more likely to be distracting (Figure 2).
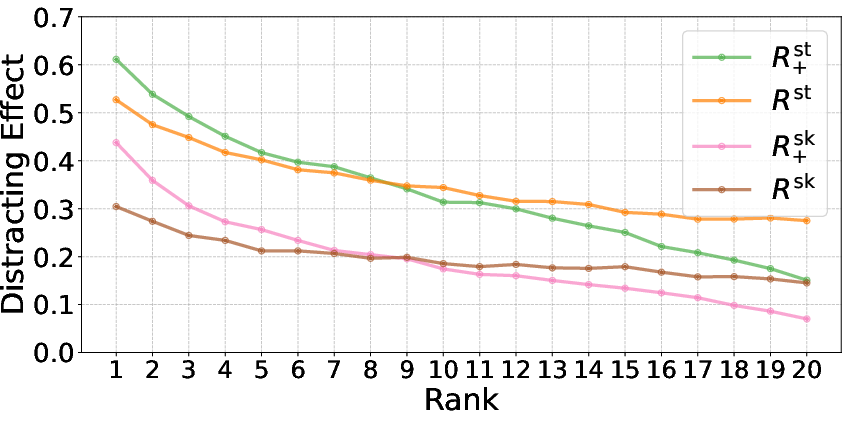
Figure 2: Average distracting effect at different rank positions for various retrieval methods. Results are shown for Llama-3.1-8B, averaged across datasets. Higher-ranked passages consistently demonstrate greater potential to mislead the model.
Generating Distracting Passages
The second approach involves generating synthetic distracting passages using a strong LLM, guided by a categorization of different distractor types:
- Related Topic (p2): Passages discussing a topic closely related to the query but not containing the answer.
- Hypothetical (p3): Passages discussing the query in a hypothetical scenario where the answer differs.
- Negation (p4): Passages providing a wrong answer in negation.
- Modal Statement (p5): Passages providing a wrong answer with a disclaimer of uncertainty.
These categories, inspired by previous work [basmov2024llms, abdumalikov2024answerability], are used in few-shot learning prompts to generate diverse distracting passages. It was found that the joint collection of methods allows for much more distracting passages compared to any single method (Figure 3).
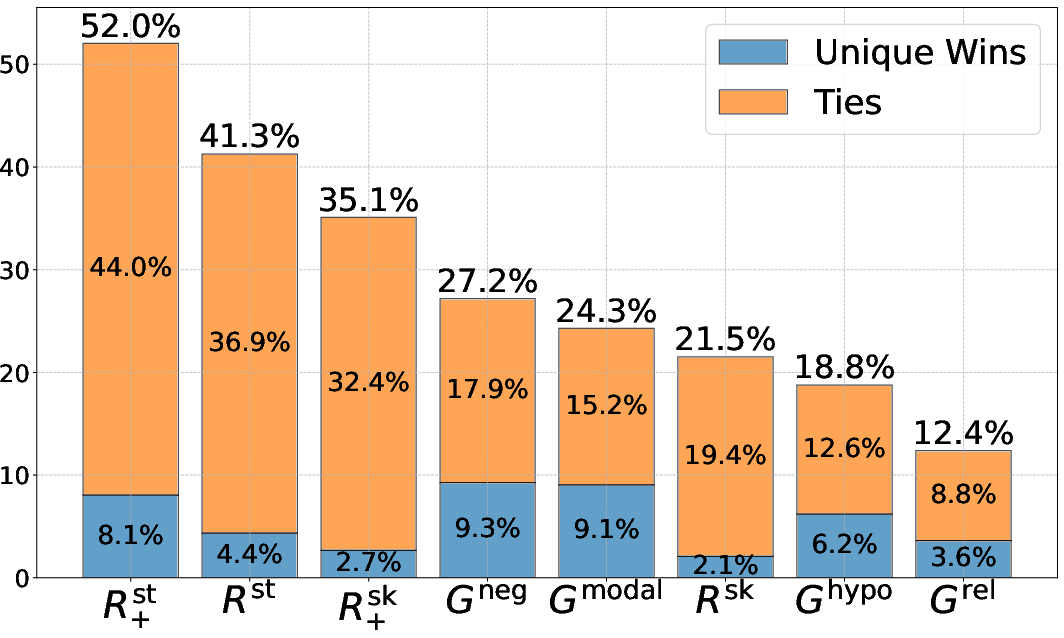
Figure 3: Percentage of queries where each method provides the most distracting passage for Llama-3.1-8B. In blue are the times when no other method reaches the same distracting effect, in orange the percentage of times the highest score is shared with other methods.
Analyzing the Distracting Effect of Different Methodologies
The paper compares the distracting effects of passages obtained through retrieval and generation. The results indicate that answer-skewed retrieval consistently provides more distracting passages than standard retrieval. Among the generation-based methods, p6 appears most effective at producing distracting passages. Combining retrieval and generation techniques leads to a significantly more diverse and challenging set of distractors (Figure 4).
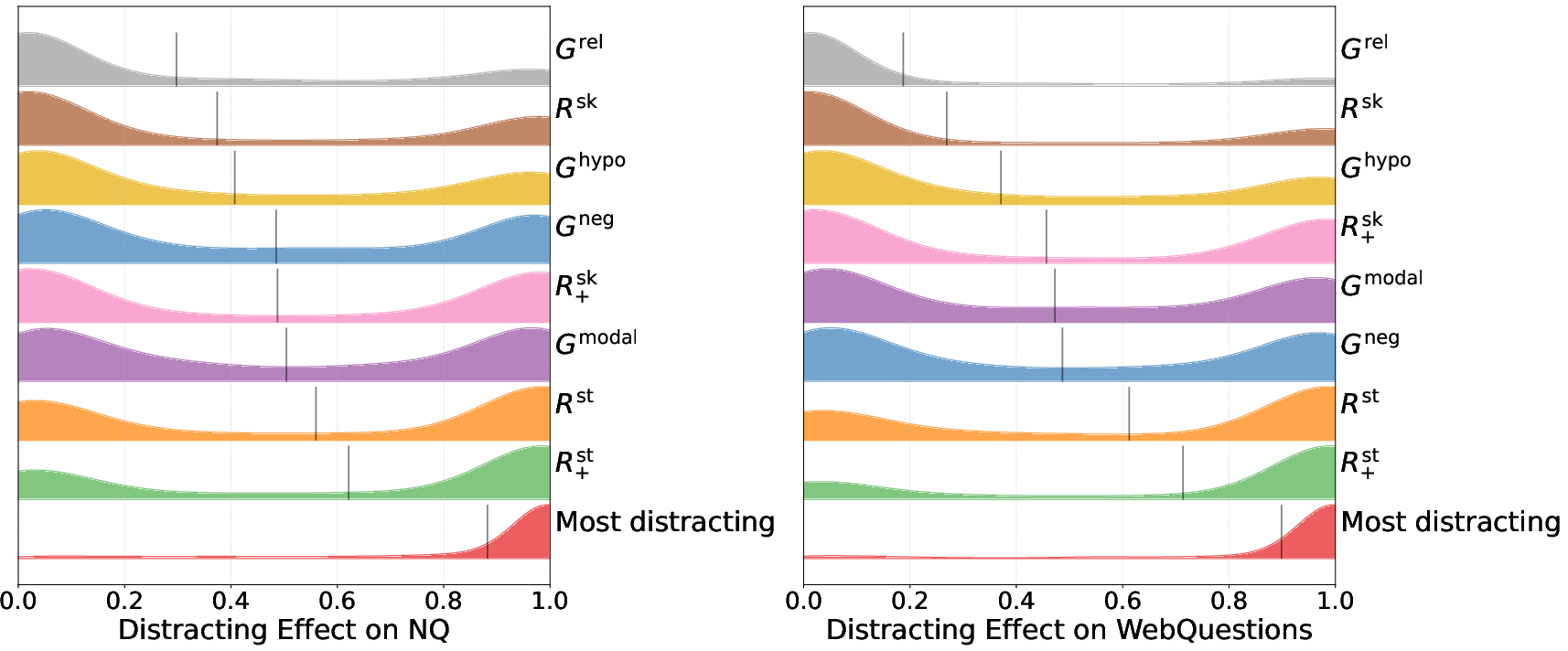
Figure 4: Distribution of distracting effect for passages obtained through different methods, as measured by Llama-3.1-8B. Methods are ordered by their mean distracting effect (shown by vertical black lines), with higher means indicating a greater ability to distract the model.
Impact on RAG Accuracy
The authors demonstrate that hard distracting passages (DE > 0.8) significantly reduce RAG accuracy compared to weak distracting passages (DE < 0.2) when included in the prompt alongside a relevant passage. This confirms the reliability of the distracting effect measure.
Application: RAG Fine-Tuning
The paper showcases the utility of distracting passages by fine-tuning an LLM on a question-answering task using a training set constructed with these passages. It was shown that fine-tuning with distracting passages leads to superior results compared to fine-tuning on standard RAG datasets, with improvements of up to 7.5% in answering accuracy. Specifically, training on "Hard" examples, which include highly distracting passages, results in major gains over baselines in various test sets.
Conclusion
This paper offers a comprehensive framework for understanding and addressing the issue of distracting passages in RAG systems. By formalizing the distracting effect, providing methods for obtaining distracting passages, and demonstrating their impact on RAG accuracy, the authors provide valuable insights for building more robust and reliable RAG systems. The results highlight the importance of considering not only relevance but also the potential for irrelevant information to mislead LLMs.