Sample-Efficient Online Learning in LM Agents via Hindsight Trajectory Rewriting
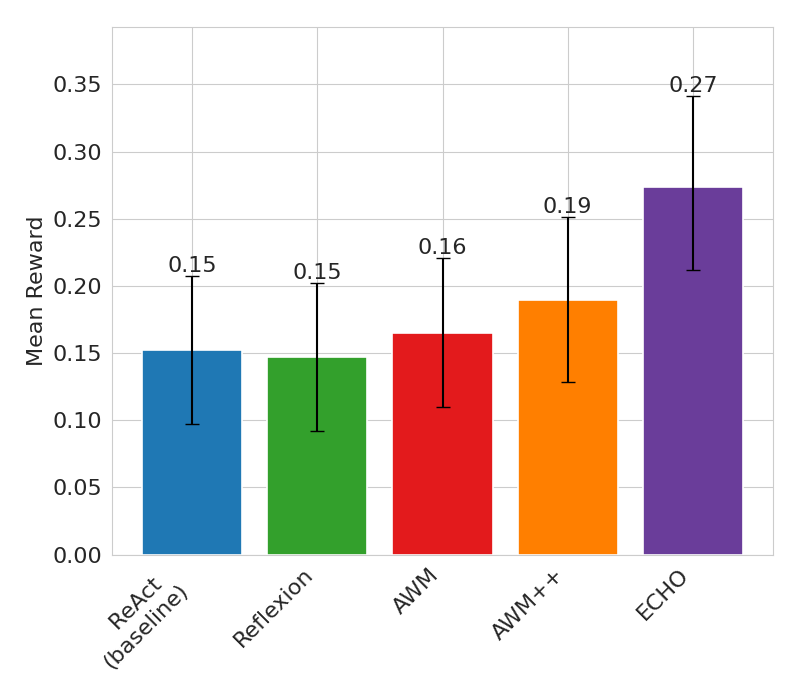
Abstract: LLM (LM) agents deployed in novel environments often exhibit poor sample efficiency when learning from sequential interactions. This significantly hinders the usefulness of such agents in environments where interaction is costly (for example, when they interact with humans or reset physical systems). While a number of existing LM agent architectures incorporate various mechanisms for experience storage and reflection, they make limited use of LMs' abilities to directly generate or reason about full counterfactual trajectories. We introduce ECHO (Experience Consolidation via Hindsight Optimization), a prompting framework that adapts hindsight experience replay from reinforcement learning for LLM agents. ECHO generates optimized trajectories for alternative goals that could have been achieved during failed attempts, effectively creating synthetic positive examples from unsuccessful interactions. Our approach consists of two components: a hindsight rule that uses the LLM itself to identify relevant subgoals and generate optimized trajectories, and an update rule that maintains compressed trajectory representations in memory. We evaluate ECHO on stateful versions of XMiniGrid, a text-based navigation and planning benchmark, and PeopleJoinQA, a collaborative information-gathering enterprise simulation. Across both domains, ECHO outperforms vanilla language agent baselines by up to 80%; in XMiniGrid, it also outperforms a number of sophisticated agent architectures including Reflexion and AWM, demonstrating faster adaptation to novel environments through more effective utilization of past experiences.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Sample-Efficient Online Learning in LM Agents via Hindsight Trajectory Rewriting — Explained Simply
Overview
This paper introduces a simple but powerful idea called ECHO that helps AI assistants learn faster from their mistakes. Instead of just saving what happened, ECHO asks the AI to look back at a failed attempt and rewrite it into a short plan for something it could have successfully done. These rewritten “success plans” are stored and reused later, so the AI gets better with fewer tries.
What the researchers wanted to find out
In plain terms, the paper asks:
- How can AI agents that act step-by-step (like in games or office tasks) learn more from each attempt—especially when trying things is slow or costly?
- Can we turn failures into useful lessons by imagining what could have worked instead?
- Does this make the AI improve faster than other popular methods that just reflect on past attempts or save full past workflows?
How ECHO works (with simple analogies)
First, a few key ideas in everyday language:
- LLM (LM) agent: Think of a smart chatbot that can read, think, and act step-by-step in a world (like a game or a workplace simulation).
- Trajectory: The sequence of steps the agent took (like a play-by-play of what it did).
- Goal: What the agent is trying to achieve (e.g., “pick up the blue key”).
- Counterfactual: What could have happened if the agent had chosen differently.
Most existing methods either:
- Write reflection notes about what went wrong (Reflexion), or
- Save successful step-by-step guides for tasks (AWM: “Agent Workflow Memory”).
ECHO is different: it lets the AI “rewrite the past.” Imagine you played a level in a game trying to get a treasure chest, but you failed. While trying, you saw a silver coin and walked near it. ECHO says: “Even though you failed the chest, you could have gotten the coin. Here’s a short, clean plan to get that coin.” Then it saves the shortest good plan for “get the coin” to use later.
Here’s the idea in two parts:
- Hindsight rule: After each attempt, the AI:
- Spots other goals it could have achieved from what it saw or did (like noticing that coin).
- Writes a better, shorter plan for that goal.
- Update rule: If there’s already a saved plan for that goal, keep the shorter, clearer one. Shorter plans are easier to reuse and remember.
Why shorter plans? It’s like keeping the simplest recipe that still works—less fluff, more action.
What the experiments looked like
The team tested ECHO in two “stateful” environments. Stateful means the world restarts in the same setup each time, but the agent can keep its memory:
- XMiniGrid-Stateful: A text-based maze with rooms and objects. The agent is asked to pick up objects and must explore to find them.
- PeopleJoinQA-Stateful: A workplace simulation. The agent must contact the right people and use tools (like a directory search) to answer questions. The needed information is spread across different “teammates.”
They compared ECHO to:
- ReAct: A basic “think then act” agent.
- Reflexion: Writes self-feedback after an attempt.
- AWM: Saves a workflow only if the attempt succeeded.
Main findings and why they matter
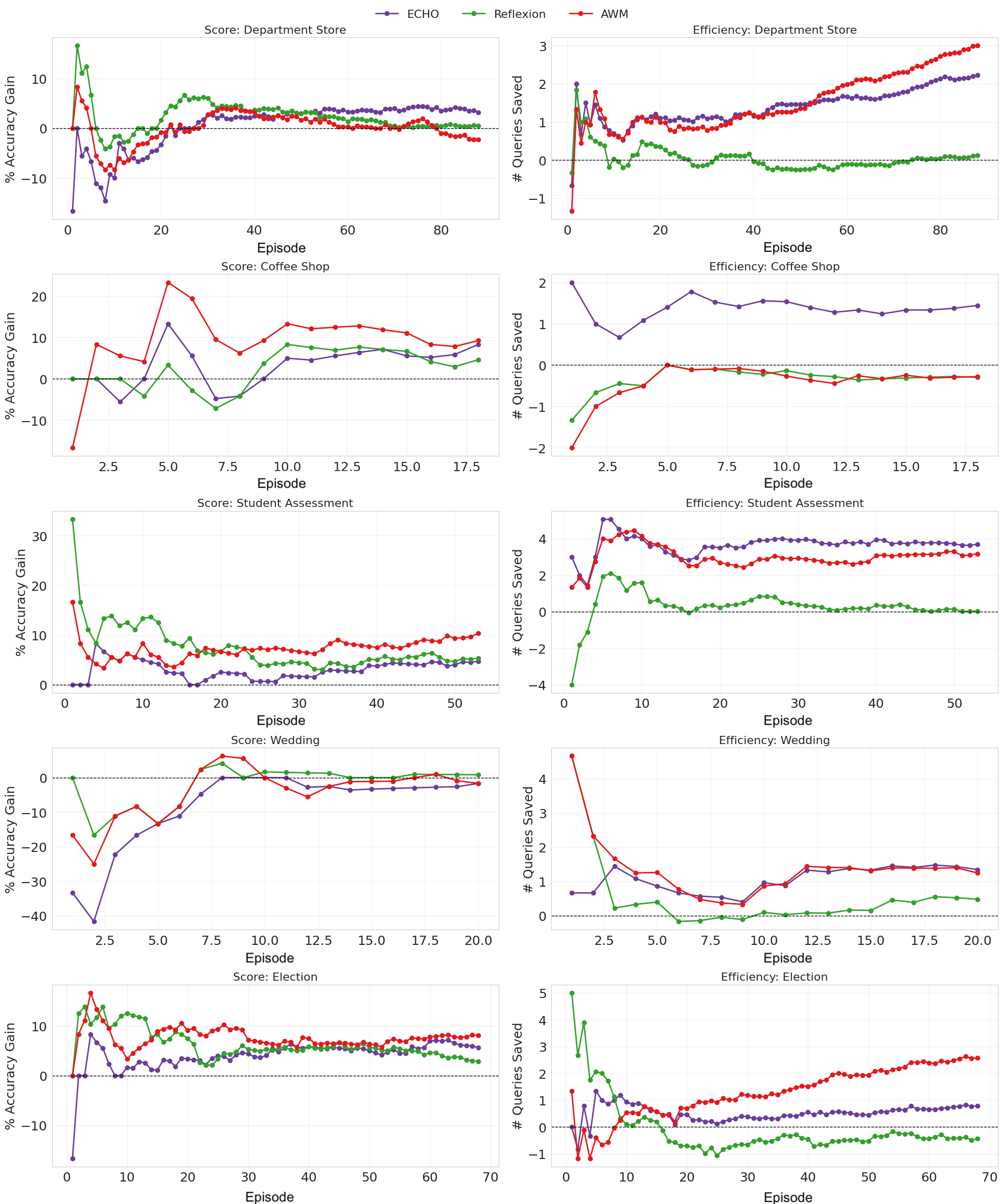
- In the grid world (XMiniGrid-Stateful):
- ECHO did the best. It improved average success by up to 80% over a standard agent and beat more advanced baselines too.
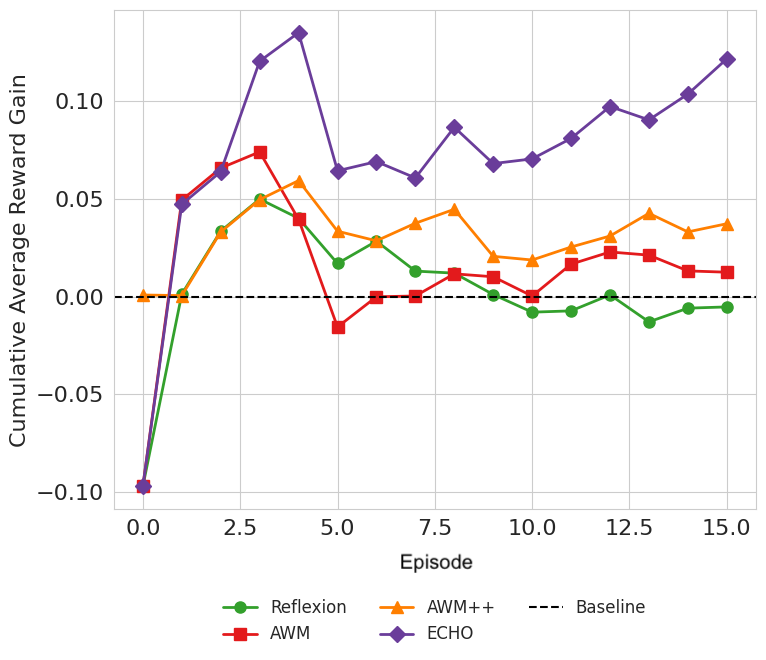
- It learned quickly—its running average reward pulled ahead after just a few tries.
- When they checked if the rewritten plans actually worked, about 85% led to success when followed later. That means the imagined “what could have worked” plans were usually realistic and useful.
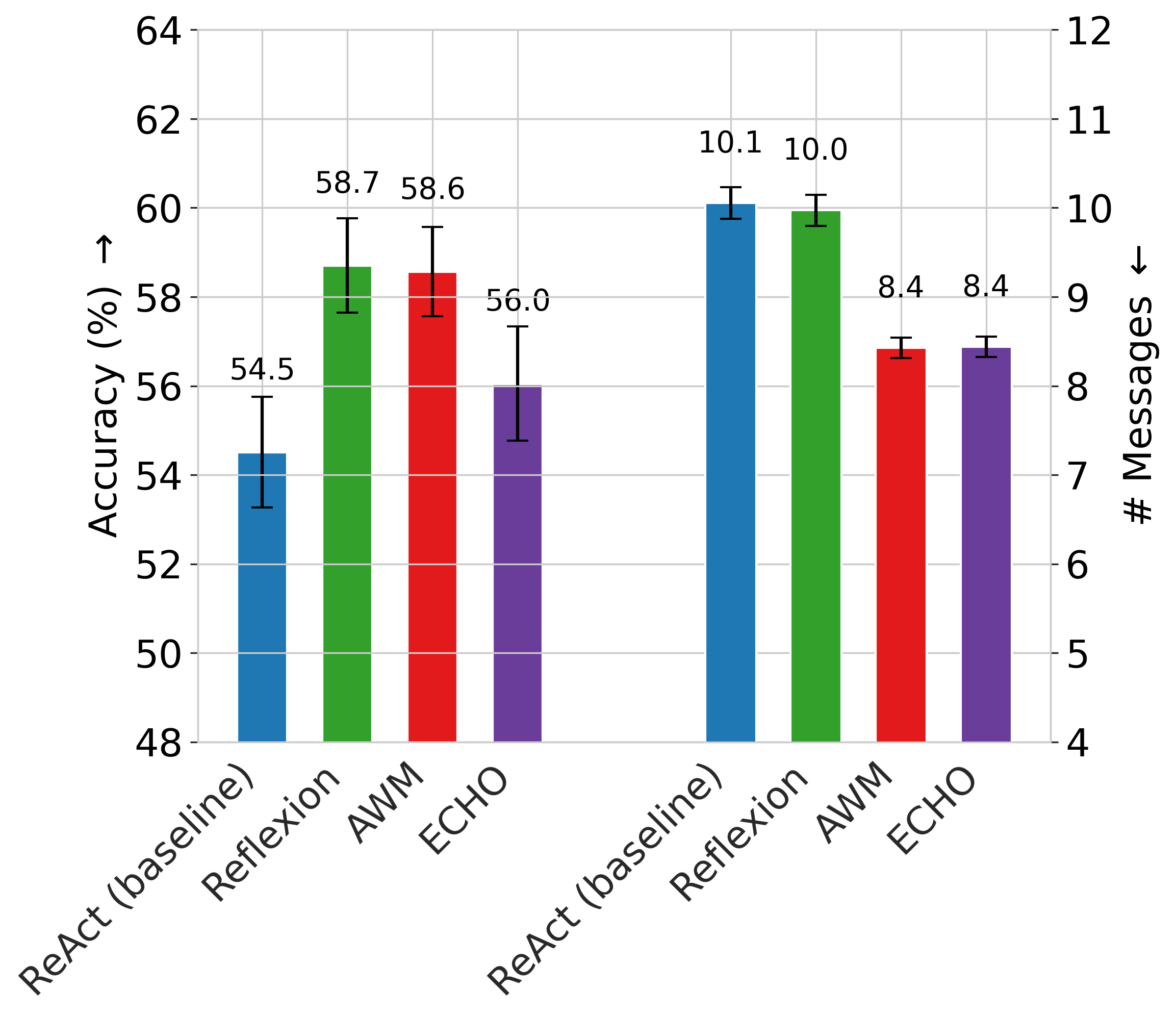
- In the workplace simulation (PeopleJoinQA-Stateful):
- Reflexion got the highest final accuracy, but
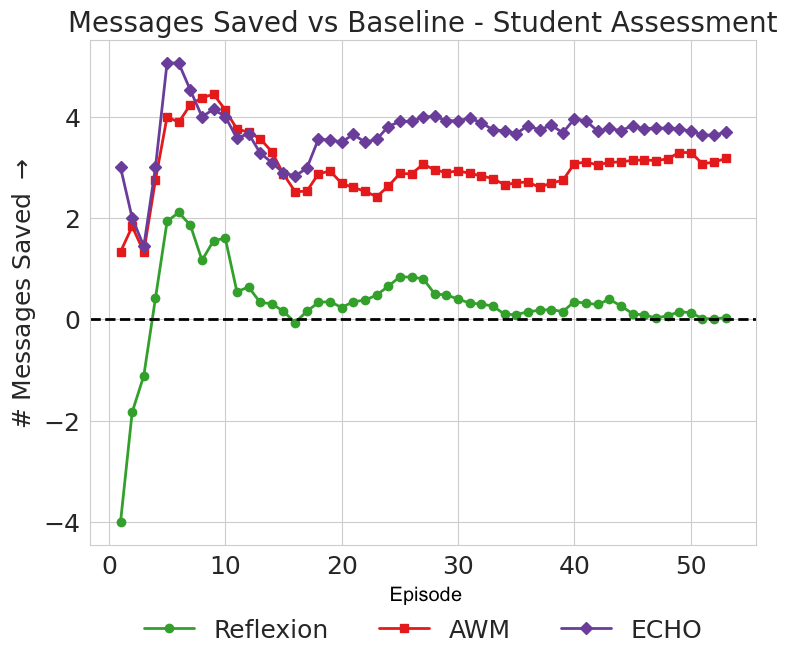
- ECHO and AWM made the agent more efficient—about 1.6 fewer messages per task on average.
- Depending on the organization, different methods won. Still, ECHO often improved faster than the plain baseline and became the most efficient method after some practice.
Why this matters: Many real tasks are expensive to try again and again (talking to humans, resetting machines, exploring websites). Learning more from each attempt—especially from failures—saves time and cost.
What this means going forward
- ECHO shows that LLMs can use their general knowledge to fill in missing details and create useful “what-if” plans, even when the world is only partly visible.
- It connects a classic idea from reinforcement learning (hindsight experience replay) with language-based planning: instead of just relabeling goals, the AI can rewrite entire plans in plain language.
- Limitations:
- Not every rewritten plan will be valid, though most were in tests.
- The “keep the shortest plan” rule is simple and could be improved.
- Future directions:
- Store plans as small programs (code-like instructions) for even more reliability.
- Combine ECHO with smart memory retrieval to pull the most relevant past plans when needed.
Bottom line
ECHO helps AI agents learn faster by turning failures into mini-successes: it looks back, figures out what could have worked, writes a short plan, and saves it for later. This makes learning more efficient in tricky, real-world-like tasks—where you don’t get many chances to try.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored, framed to guide concrete follow-up research:
- Formal underpinnings: Provide a theoretical formulation of ECHO as a hindsight editing/relabeling operator (e.g., in a goal-conditioned RL or off-policy learning framework), with analysis of bias introduced by counterfactual trajectory edits and any convergence or performance guarantees.
- Verification of counterfactuals: Develop automated executability checks (e.g., environment rollouts, constraint validators, or program analyzers) to verify and repair synthesized workflows; quantify executability across domains beyond the small XMiniGrid sample (n=40).
- Update rule rigor: Replace the “shortest-description-wins” heuristic with validated criteria (e.g., success-validated length, MDL with correctness penalties, or probabilistic scoring) and study trade-offs between brevity and fidelity; measure failure modes where compression removes necessary preconditions.
- Memory management at scale: Specify and evaluate memory capacity limits, deduplication, retrieval/indexing strategies, relevance scoring, aging/eviction policies, and their impact on performance and context-length constraints.
- Replay prioritization: Explore prioritized re-use (e.g., PER-like scoring based on utility, novelty, confidence) for goals/trajectories in the buffer and compare to FIFO/append-only usage.
- Goal identification precision: Quantify precision/recall of the LM’s goal proposal mechanism, its abstention rate, and controls to suppress spurious or unattainable goals; test affordance- or constraint-aware goal filtering.
- Component ablations: Isolate contributions of (i) goal relabeling vs (ii) trajectory rewriting vs (iii) the update rule; include an ECHO variant that only relabels goals (HER-style) and one that only edits intermediate steps.
- Retrieval at inference: Clearly specify how stored trajectories are retrieved/selected for conditioning at decision time; compare naive append to retrieval-augmented prompting (RAG) and measure context budgeting effects.
- Robustness across LMs and prompts: Replicate with multiple model families (open-source and API models), decoding temperatures, seeds, and prompt variants; report sensitivity and stability envelopes.
- Cost and latency accounting: Report token usage, wall-clock time, and monetary cost of ECHO’s hindsight generation vs baselines to quantify the sample-efficiency vs compute/cost trade-off.
- Broader task coverage: Test beyond “pick up” goals in XMiniGrid (e.g., multi-step manipulation, irreversible actions, navigation with constraints) and more complex real-world-like domains (web navigation, robotics).
- Non-stationarity and stochasticity: Evaluate ECHO when environment dynamics or organizational structures drift across episodes; measure forgetting, robustness, and adaptation speed under concept drift.
- Multi-agent coordination: In PeopleJoinQA, study how multiple agents share, reconcile, or specialize hindsight memories; compare centralized vs decentralized memory and conflict resolution across agents.
- Safety and hallucination mitigation: Add confidence calibration and validation gates to prevent harmful or infeasible counterfactuals from entering memory; quantify hallucination-induced errors and repair strategies.
- When ECHO helps vs hurts: Build a taxonomy of conditions under which ECHO outperforms (e.g., sparse rewards, partial observability) vs underperforms (e.g., PeopleJoin accuracy gap); develop a meta-controller to switch between Reflexion/AWM/ECHO.
- Statistical rigor and scale: Increase the number of environments and organizations; report confidence intervals, effect sizes, and significance tests; conduct power analyses to support claims.
- Transfer learning: Measure whether hindsight trajectories transfer across related environments/tasks (e.g., new maps or organizations) and whether replay generalizes or overfits to specific layouts.
- Programmatic representations: Implement and evaluate code-like or DSL-based workflows with executable semantics and checkers; compare correctness, editability, and performance vs natural language workflows.
- Use of reward signals: Investigate hybrid settings where sparse environment rewards exist; study how explicit rewards interact with ECHO’s reward-free counterfactual edits.
- Ontology and goal grounding: Introduce a goal ontology or schema to normalize, deduplicate, and map goals to environment entities; study effects on retrieval and success rates.
- Calibration of abstention: Quantify and tune the abstain mechanism (when to propose no goals); explore uncertainty-aware thresholds to reduce false-positive updates.
- Diversity vs compression: Encourage multiple diverse successful trajectories per goal (to avoid mode collapse to the shortest workflow); assess diversity’s effect on robustness.
- Practical tool-use constraints: In tool-based domains (e.g., PeopleJoinQA), evaluate ECHO under API failures, rate limits, and transactional constraints; test repair loops for tool errors in counterfactuals.
- Privacy and ethics: Address retention, privacy, and provenance of hindsight memories when interactions involve humans; define policies for redaction, expiration, and auditability.
- Reproducibility completeness: Release full prompts, seeds, environment generators, and evaluation harnesses (appendix prompts are truncated); document all hyperparameters and selection heuristics to enable exact replication.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can be built now using the paper’s prompting-only ECHO framework (hindsight trajectory rewriting + minimal description length update), with existing LLM agent stacks.
- Sector: Enterprise IT / Internal Helpdesk
- Use case: Org-aware assistant that rapidly adapts to internal processes (e.g., onboarding, access requests, ticket triage) by converting failed attempts into reusable workflows and alternative subgoals (who to contact, which system to query).
- Tools/workflows: “ECHO buffer” service keyed by goals; goal-identification + trajectory-rewriting prompts; retrieval hook that surfaces shortest valid workflows during tool-use (directory, ticketing, knowledge base).
- Assumptions/dependencies: Stable enough processes across episodes; guardrails to avoid hallucinated steps; light-weight execution validation (e.g., dry-run API calls).
- Sector: Customer Support / CRM
- Use case: Case resolution copilots that learn from failed playbooks (e.g., wrong entitlement path) and synthesize shorter, verified playbooks for alternative resolutions (refund, escalation, self-serve knowledge).
- Tools/workflows: Playbook store populated via hindsight rewrites; Slack/Email tool adapters; “abstain” gating when no valid subgoals exist.
- Assumptions/dependencies: Access to historical tickets; data privacy constraints; human-in-the-loop approval for new playbooks.
- Sector: Software (DevOps/SRE)
- Use case: Incident response copilots that rewrite failed remediation sequences into minimal, executable runbooks for subgoals (restore partial service, isolate component, rollback).
- Tools/workflows: Terminal/API tool adapters; runbook memory using ECHO’s shortest-workflow update; structured JSON workflows with automatic parameterization.
- Assumptions/dependencies: Sandbox/dry-run validation; role-based access controls; logging/auditing of self-improvements.
- Sector: RPA / Desktop and Web Automation
- Use case: UI automation agents that convert failed automations into reliable alternative workflows (e.g., different navigation path, cached element selectors).
- Tools/workflows: Trajectory-as-exemplar memory (à la Synapse) augmented with ECHO rewriting; selector/version cache.
- Assumptions/dependencies: Pages evolve; requires selector-health checks; needs rollback if environment changed.
- Sector: Knowledge Work / Cross-functional Q&A
- Use case: Multi-party information-gathering copilots (PeopleJoin-like) that reduce messages by consolidating who-knows-what and optimized outreach sequences.
- Tools/workflows: Organization directory + document search tools; “who to ask/where to look” workflows distilled by ECHO; message-budget constraints.
- Assumptions/dependencies: Persistent org graph; permissioning; potential variance by team/org necessitates per-context memory.
- Sector: Education
- Use case: Course/LMS assistants that learn optimal sequences for finding resources, explaining subskills, or troubleshooting common pitfalls (alternative paths to intermediate learning goals).
- Tools/workflows: ECHO buffer of “how to learn X from this LMS” micro-workflows; retrieval-augmented tutoring prompts.
- Assumptions/dependencies: LMS/tool access; student privacy; execution checks to avoid promoting ineffective paths.
- Sector: Finance Operations (Back-office, Reconciliation, Compliance Evidence)
- Use case: Data-collection agents that, after failed document retrieval or control checks, synthesize successful subgoal workflows (alternative data sources, revised filters, revised request order).
- Tools/workflows: Document retrieval tools; compliance checklist memory with compressed workflows; audit-friendly logs of replayed trajectories.
- Assumptions/dependencies: Strict PII/records retention policies; verification of each step; human review for regulatory artifacts.
- Sector: Research & Academia (Agent Evaluation and Benchmarking)
- Use case: Low-cost evaluation harnesses for agent sample efficiency using XMiniGrid-Stateful/PeopleJoinQA-Stateful plus ECHO; rapid ablation of memory/update rules.
- Tools/workflows: Open-source benchmarks; ECHO prompt templates; plug-ins for LangGraph/LangChain/CrewAI/Assistants APIs.
- Assumptions/dependencies: API access (e.g., GPT-4o or local LLMs); reproducible seeds; cost tracking.
- Sector: Personal Productivity
- Use case: Personal assistants that learn household/administrative workflows (renew a license, file reimbursements) and rewrite missteps into minimal checklists for alternative goals (partial completions, prerequisite tasks).
- Tools/workflows: Calendar/email/tool integrations; short, verifiable checklists with links; “retry with workflow” button.
- Assumptions/dependencies: Frequent policy/site changes; needs time-stamped workflow validity and refresh heuristics.
- Sector: Safety & Trust Engineering
- Use case: Auditability of self-improving agents via natural language episodic memory (before/after trajectories and rationale), enabling lightweight compliance reviews.
- Tools/workflows: Versioned ECHO memory store; diff views of rewritten workflows; risk flags for unverifiable steps.
- Assumptions/dependencies: Storage costs; access controls; redaction pipelines for sensitive data.
Long-Term Applications
These applications are feasible with additional research, scaling, verification, or productization beyond prompting-only ECHO.
- Sector: Robotics (Manufacturing, Logistics, Home)
- Use case: Robots that convert failed task attempts into executable plans for subgoals (e.g., grasp/place partial success) and reuse them across tasks to improve sample efficiency.
- Tools/workflows: Programmatic action graphs; simulation-in-the-loop validators; HER + ECHO hybrid with sensor-grounded checks.
- Assumptions/dependencies: Robust perception/action models; safety constraints; high-fidelity simulators; real-world validation.
- Sector: Healthcare Administration and Clinical Support
- Use case: Prior authorization and referral copilots that learn optimized multi-system workflows; clinical summarization workflows that adapt to local EHR quirks.
- Tools/workflows: EHR APIs; programmatic workflow specs; confidence/verification channels; human oversight UIs.
- Assumptions/dependencies: HIPAA compliance; strict verification; evolving payer rules; high accuracy requirements.
- Sector: Program Synthesis / Software Engineering
- Use case: Agents that rewrite failed build/deploy/testing sequences into minimal reproducible pipelines; generalize to “programmatic ECHO” where outputs are code-like workflow specs.
- Tools/workflows: Typed DSLs for workflows; property-based tests; CI/CD validators that auto-learn “shortest fix” patterns.
- Assumptions/dependencies: Need precise, executable representations; formal checks to avoid regressions.
- Sector: Policy/Government Services
- Use case: Self-improving public service assistants that learn locality-specific procedures and convert failures into verified playbooks (permits, benefits, registrations).
- Tools/workflows: Policy-aligned workflow repositories; audit trails; citizen-facing explanations with provenance.
- Assumptions/dependencies: Fairness, transparency mandates; drift detection as rules change; rigorous human review.
- Sector: Energy and Utilities Operations
- Use case: Grid/asset monitoring copilots that refine diagnostic subgoal workflows from failed fault-localization attempts (alternative sensors, time windows, topology queries).
- Tools/workflows: SCADA/digital twin integrations; simulation-backed validation of rewritten trajectories.
- Assumptions/dependencies: Safety-critical verification; access to historical telemetry; latency constraints.
- Sector: Financial Trading and Risk
- Use case: Post-mortem learning agents that convert failed strategies into validated subgoal workflows (risk caps, alternative hedges) for scenario analysis, not direct trading.
- Tools/workflows: Backtesting sandboxes; policy constraints baked into ECHO update; governance gates for production use.
- Assumptions/dependencies: Strict compliance; separation of research vs execution; robust evaluation metrics.
- Sector: Multi-Agent Systems and Collaboration Platforms
- Use case: Teams of agents that share compressed episodic memories of “how to accomplish subgoals” and dynamically compose workflows across roles.
- Tools/workflows: Shared ECHO memory with access controls; role-conditioned retrieval; conflict resolution of workflows.
- Assumptions/dependencies: Memory governance; versioning and staleness management; emergent behavior monitoring.
- Sector: Scientific Discovery (Lab Automation)
- Use case: Experiment planning agents that reframe failed experiments as pathways to intermediate products or measurements; reuse optimized sub-protocols across studies.
- Tools/workflows: Protocol DSLs, robotic lab integrations; simulation or literature-grounded verification; provenance tracking.
- Assumptions/dependencies: Safety/ethics for wet lab automation; replicability checks; expert oversight.
- Sector: Agent Safety, Evaluation, and Standards
- Use case: Benchmarks and standards for sample-efficient agents using counterfactual rewriting, including executability rates, abstention quality, memory governance, and auditability.
- Tools/workflows: Expanded stateful benchmarks (beyond XMiniGrid/PeopleJoin); standardized metrics (cumulative reward gain, validity %); certification processes.
- Assumptions/dependencies: Community adoption; shared datasets; evaluation sandboxes.
- Sector: Platform/Tooling Vendors
- Use case: First-class “ECHO Memory” modules in agent frameworks that support goal-keyed memories, shortest-workflow updates, abstention, validation hooks, and time-aware decay.
- Tools/workflows: SDKs for memory stores; validators (execution, simulation, formal); policy engines for write/overwrite rules.
- Assumptions/dependencies: Interop standards; cost optimization; privacy and tenancy models.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Validity of counterfactual trajectories: Requires execution validators (sandbox, simulation, typed DSLs, or unit tests); abstention when uncertain.
- Environment stability and statefulness: ECHO assumes repeated or similar contexts across episodes; needs time/version tagging and decay to handle drift.
- Data governance and safety: Storing episodic memories may capture sensitive data; requires redaction, RBAC, audit logs.
- Cost and latency: Rewriting and retrieval need budgets; prioritize when sparse rewards or high interaction costs make sample efficiency valuable.
- Domain knowledge fit: LMs must have enough prior knowledge to propose plausible edits; specialized domains may need tool-verified or programmatic representations.
- Update rule robustness: “Shortest description wins” is a heuristic; production systems should blend length with validity, recency, and success rates.
Glossary
- Agent Workflow Memory (AWM): An LM agent mechanism that summarizes successful trajectories into reusable workflows to improve future decisions. "In this work, we consider two baselines, Reflexion and Agent Workflow Memory (AWM), as exemplars of manipulating semantic and episodic memory"
- Counterfactual trajectories: Hypothetical sequences of actions and states describing what could have happened under alternative decisions or goals. "they make limited use of LMs' abilities to directly generate or reason about full counterfactual trajectories."
- Counterfactual workflows: Hindsight-synthesized procedural descriptions that specify how an agent could achieve alternative goals based on past failures. "This indicates that the counterfactual workflows generated by ECHO in XMiniGrid are largely correct and lead the agent to successful solutions."
- Cumulative average reward: The average of rewards obtained up to a given episode, used to measure sample efficiency over time. "Our evaluation metrics are final average reward (or accuracy) and cumulative average reward."
- ECHO (Experience Consolidation via Hindsight Optimization): A prompting framework that rewrites failed trajectories into optimized, goal-achieving narratives for sample-efficient learning. "We introduce ECHO (Experience Consolidation via Hindsight Optimization), a prompting framework that adapts hindsight experience replay from reinforcement learning for LLM agents."
- Egocentric text description: A viewpoint-centered textual rendering of an agent’s local observations to enable language-based navigation. "we convert its 2D observation space to an egocentric text description, which reads something like"
- Episodic memory: Memory that stores an agent’s past actions and experiences for later reflection and reuse. "episodic memory stores past actions."
- Experience replay: An RL technique that reuses stored trajectories to improve learning efficiency, especially under sparse rewards. "Such experience replay techniques have proven especially valuable in situations with sparse rewards or limited data"
- Goal-conditioned policy: A policy that selects actions conditioned on a specified goal state rather than just the current state. "HER learns a goal-conditioned policy; during training, each attempt to reach a goal state s that fails in an end state s' is interpreted as a successful trajectory for reaching s'."
- GridWorld: A discrete, grid-based environment used for navigation and planning tasks. "stateful variants of a 2D GridWorld task (XMiniGrid,"
- Hindsight Experience Replay (HER): An RL method that relabels failed trajectories with alternative goals they incidentally achieved, treating them as successes. "HER learns a goal-conditioned policy; during training, each attempt to reach a goal state s that fails in an end state s' is interpreted as a successful trajectory for reaching s'."
- Hindsight rule: The ECHO step where the LM proposes alternative goals and synthesizes optimized trajectories from a past rollout. "During application of the hindsight rule, the LM first proposes goals that it can infer how to accomplish from a given trajectory."
- Kolmogorov complexity: The length of the shortest description of an object; used as a motivation for storing compressed trajectory representations. "Our motivation here is related to Kolmogorov complexity, or minimum description length"
- LLM (LM) agents: Systems that use LMs to reason, act, and interact with environments over time. "LLM (LM) agents deployed in novel environments often exhibit poor sample efficiency"
- Minimum description length: A principle favoring the shortest plausible explanation/encoding of data; guides ECHO’s compressed memory updates. "Our motivation here is related to Kolmogorov complexity, or minimum description length"
- Off-policy RL algorithms: Methods that learn from trajectories generated by a different policy than the one currently being optimized. "One reason why off-policy RL algorithms can be more efficient than on-policy ones"
- On-policy: RL methods that learn exclusively from trajectories generated by the current policy. "on-policy ones"
- Partial observability: A condition where the agent’s perception does not reveal the full environment state, increasing planning difficulty. "Partial observability makes the task challenging"
- Perception--action loop: The iterative process where an agent observes, reasons, and acts within an environment. "These agents typically operate through a perception--action loop, where they observe their environment, reason about the current state, and generate actions"
- PeopleJoinQA: A benchmark simulating multi-user information-gathering tasks requiring tool use and collaboration. "PeopleJoinQA, a collaborative information-gathering enterprise simulation."
- ReAct: A language agent pattern that interleaves reasoning (“think”) and acting (“act”) steps to solve tasks. "reason-then-act (ReAct) LM agent"
- Reflexion: A method where the LM reflects on its past trajectory to produce improvement notes for future episodes. "Reflexion instructs the LLM to reflect on the previous trajectory and propose areas of improvement;"
- Replay buffer: A memory structure containing stored (and possibly compressed) trajectories/workflows for reuse. "we want the replay buffer to contain the shortest possible description for achieving the goal."
- Sample efficiency: The effectiveness of learning from limited interactions or data. "often exhibit poor sample efficiency when learning from sequential interactions."
- Scratchpad memory: A persistent, free-form memory where the agent records insights to carry across episodes. "allowing agents to persist insights via a scratchpad memory."
- Semantic memory: Memory storing factual, generalizable knowledge about the environment. "Semantic memory contains facts about the environment"
- Stateful: An environment/agent setting where information persists across episodes, enabling cumulative learning. "We make these environments stateful by allowing agents to persist insights via a scratchpad memory."
- State-action-reward tuple: The atomic RL timestep consisting of the observed state, chosen action, and received reward. "a timestep as a single state-action-reward tuple within an episode."
- World model: An internal representation of environment dynamics that supports prediction and planning. "infer a full internal world model of its environment."
- XMiniGrid: A procedurally-generated, partially observable 2D GridWorld environment used for benchmarking LM agents. "XMiniGrid is a procedurally-generated GridWorld, where an agent navigates and perform tasks in a partially-observable 2D grid environment."
Collections
Sign up for free to add this paper to one or more collections.

