- The paper introduces JEFHinter, leveraging offline trajectories—including both successes and failures—to distill context-aware hints that improve LLM decision-making.
- It employs a zoom-and-reflect methodology to identify critical decision points, achieving up to 20× speedup in scalable hint generation.
- Empirical benchmarks indicate that JEFHinter outperforms baselines by effectively guiding LLM agents, even in out-of-task generalization scenarios.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Motivation and Context
LLM agents have demonstrated strong performance in sequential decision-making tasks, particularly in web navigation and interactive environments. However, their adaptation to unfamiliar domains is limited by the need for costly online interactions or extensive fine-tuning, which is often infeasible for closed-source models and computationally expensive for open-source ones. Existing approaches such as supervised fine-tuning and reinforcement learning suffer from off-policy bias, poor generalization, and impractical resource requirements. Retrieval-augmented generation (RAG) and demonstration-based methods are constrained by the length, noise, and task-specificity of raw trajectories. The Just-in-time Episodic Feedback Hinter (JEFHinter) framework addresses these limitations by distilling offline trajectories—including both successes and failures—into concise, context-aware hints that can be efficiently retrieved and injected into agent policies at inference time.
System Architecture and Methodology
JEFHinter is an agentic system composed of three main modules: trace collection, zoom-and-reflect hint generation, and hint retrieval for action guidance.
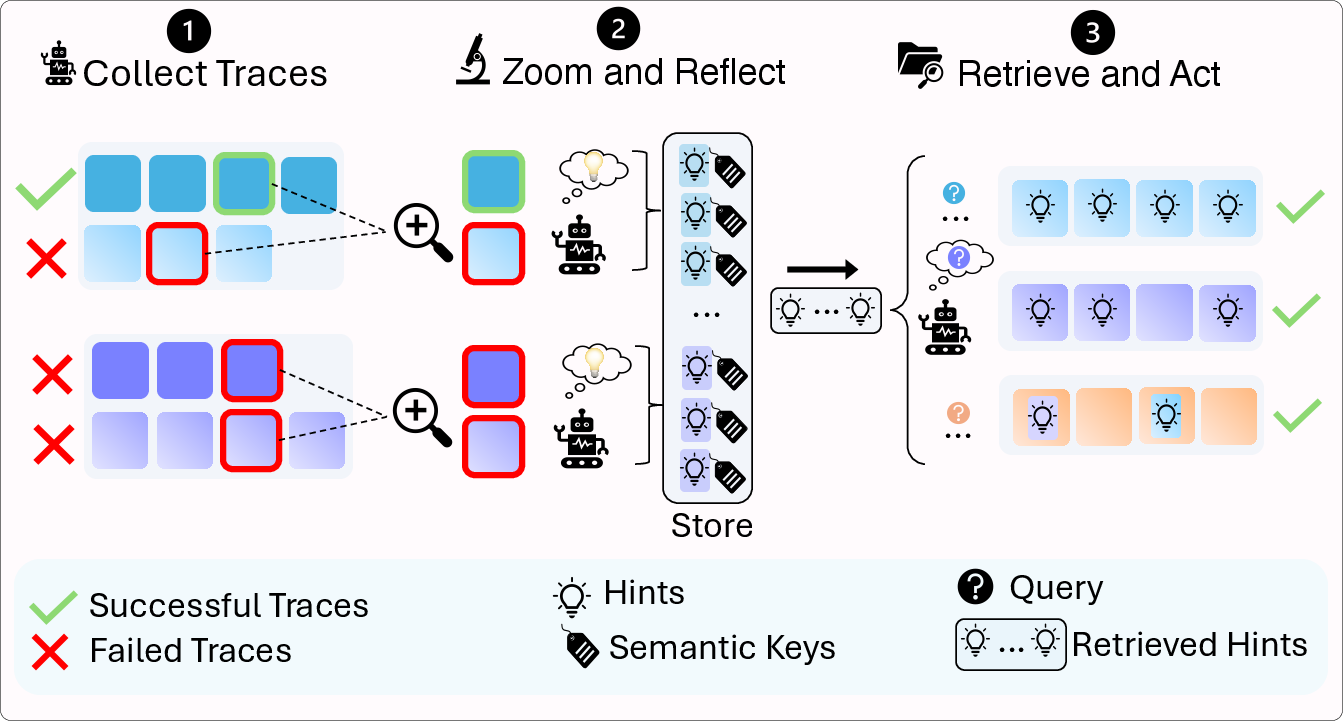
Figure 1: Overview of the JEFHinter system, illustrating trace collection, zoom-and-reflect hint generation, and hint retrieval for agent action guidance.
Trace Collection
JEFHinter operates over heterogeneous offline trajectories, encompassing both successful and failed runs. This design enables the system to capture not only effective strategies but also common pitfalls, increasing the robustness and generalizability of the extracted knowledge. The framework supports single-trace, pairwise, and multi-trace analysis, allowing flexible evidence selection for hint generation.
Zoom-and-Reflect Hint Generation
A zooming module identifies critical steps within each trajectory—decision points, repeated mistakes, successful strategies, and timing dependencies. The Hinter model (an LLM, typically larger and more capable than the base agent) reflects on these segments to distill them into concise, reusable natural language hints. Each hint is paired with a semantic key summarizing its context, facilitating efficient retrieval. The hint generation process is parallelized for scalability, achieving up to 20× speedup over sequential approaches.
Hint Retrieval and Action Guidance
At inference, the agent generates a query (goal- or context-conditioned) that is matched against the database of semantic keys. The most relevant hints are retrieved and injected into the agent's context, guiding its actions. Two retrieval strategies are supported:
- Contextual (step-level) retrieval: Fine-grained, context-specific guidance at each time step, with higher computational cost.
- Goal-conditioned (episode-level) retrieval: Efficient, episode-level guidance using the task goal as context, reducing inference cost.
Hints can be sourced from in-task, cross-task, or hybrid retrieval pools, supporting both reliability and transfer.
Empirical Evaluation
JEFHinter is evaluated on three web agent benchmarks: MiniWoB++, WorkArena-L1, and WebArena-Lite, spanning synthetic UI tasks, enterprise knowledge-work, and realistic multi-domain web environments.
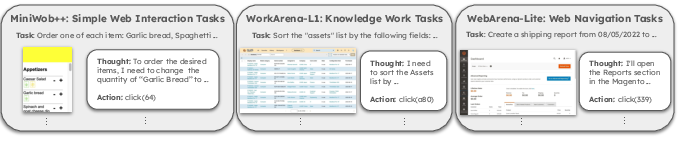
Figure 2: Web browsing benchmarks considered: MiniWoB++, WorkArena-L1, and WebArena-Lite.
JEFHinter consistently outperforms strong baselines, including ReAct and AutoGuide, across all benchmarks and base models. Notably, it achieves substantial gains over baselines while incurring only slightly higher cost than the original ReAct agent and being far more efficient than AutoGuide.
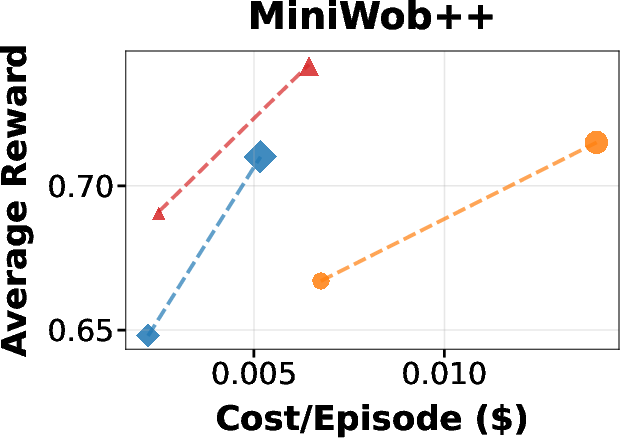
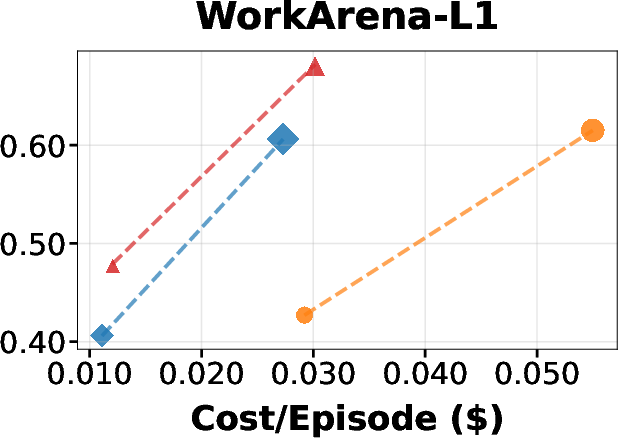
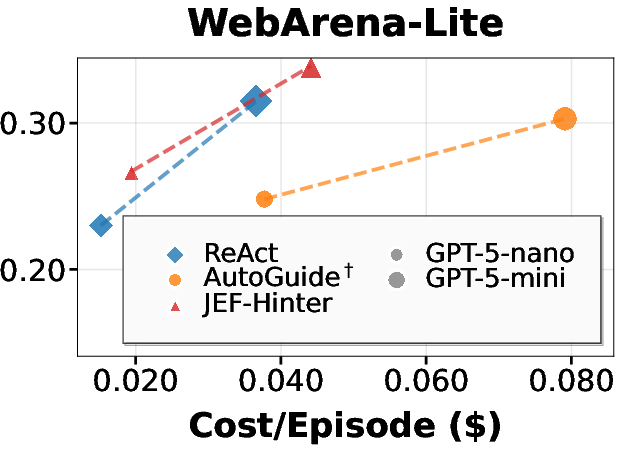
Figure 3: Average episodic reward versus test-time evaluation cost on MiniWoB++, WorkArena-L1, and WebArena-Lite, using GPT-5-mini as the Hinter model. JEFHinter achieves substantial gains over baselines with minimal additional cost.
Hints derived from failed trajectories provide constructive guidance, enabling performance improvements even in tasks where the baseline agent fails entirely. Zooming on critical steps further enhances hint quality without increasing inference cost.
Comparison with Documentation and Human Hints
JEFHinter is compared against documentation retrieval and human-authored hints. While external resources offer modest gains, they are limited by manual quality and scalability. JEFHinter's automated hint generation from offline traces is more practical and broadly effective.
Out-of-Task Generalization
JEFHinter sustains competitive performance in out-of-task generalization settings, where hints are retrieved from tasks other than the source. This demonstrates the transferability of trajectory-derived hints beyond their original domains.
Hinter Model Capacity
Scaling the Hinter model (e.g., from GPT-5-mini to GPT-5) improves hint quality and downstream performance, especially on complex, long-horizon tasks. However, this introduces a trade-off between quality and computational cost.
Qualitative Analysis
Case studies illustrate JEFHinter's ability to correct agent failure modes by providing explicit, actionable guidance at critical decision points.

Figure 4: miniwob.click-scroll-list. With gpt-5-mini as the hinter model and gpt-5-nano as the base model. Performance is improved from 0.6 to 1 after applying hint.

Figure 5: workarena.servicenow.all-menu. With gpt-5-mini as the hinter model and gpt-5-nano as the base model. Performance is improved from 0 to 1 after applying hint.

Figure 6: webarenalite.288. With gpt-5 as the hinter model and gpt-5-mini as the base model. Performance is improved from 0 to 1 after applying hint.
Hints intervene precisely at decision points, correcting reasoning and enabling successful task completion. For example, in multi-select list tasks, hints instruct the agent to hold Ctrl/Cmd for multi-selection, overcoming repeated failures. In enterprise navigation tasks, hints guide the agent to use the correct filter and menu, avoiding wasted actions. In complex shopping admin tasks, hints provide detailed step sequences for filtering, sorting, and aggregating data, enabling accurate task completion.
Implementation Considerations
- Parallelized hint generation enables large-scale construction of hint databases.
- Zooming module reduces context length for the Hinter, improving hint quality and efficiency.
- Semantic key-based retrieval supports both fine-grained and episode-level guidance.
- No fine-tuning required for the base agent, making the approach applicable to closed-source models.
- Transparent and traceable guidance allows systematic analysis of how offline data influences agent behavior.
Limitations and Future Directions
- Quality of offline data: The effectiveness of hints depends on the diversity and quality of collected trajectories.
- Documentation coverage: External documentation is often incomplete or misaligned with low-level agent actions.
- Scalability of human hints: Manual annotation is expensive and not scalable.
- Transferability: Out-of-task generalization remains challenging in highly diverse environments.
Future work may explore more sophisticated retrieval mechanisms, integration with multimodal observations, and automated augmentation of offline datasets to further enhance agent adaptation and generalization.
Conclusion
JEFHinter provides a data-centric framework for improving LLM agent adaptation by distilling offline trajectories into actionable, context-aware hints. The system demonstrates robust performance gains, efficient inference, and strong generalization across tasks and domains. Its modular design, parallelized hint generation, and transparent guidance offer practical advantages for deploying resilient LLM agents in real-world applications. The approach represents a significant step toward systematic mining of reusable knowledge from past experiences, documents, and human instructions to support robust sequential decision-making in LLM agents.