- The paper introduces StarPO, a reinforcement learning framework that optimizes multi-turn interactions for self-evolving LLM agents.
- It demonstrates training stability improvements through variance filtering, redundancy reduction, and KL constraint relaxation leading to enhanced agent performance.
- Empirical results across diverse environments illustrate the framework's capability to maintain robust reasoning and dynamic adaptation in LLM agents.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
RAGEN proposes a multi-turn reinforcement learning (RL) framework tailored for LLM agents, focusing on self-evolution through dynamic environmental interactions. This research highlights key elements in training LLMs as autonomous agents, particularly through the StarPO framework which accommodates complex interaction scenarios requiring sequential decision-making, memory retention across dialogue turns, and adaptability to stochastic feedback.
Reinforcement Learning Framework
State-Thinking-Actions-Reward Policy Optimization (StarPO)
StarPO is a general RL framework formulated to optimize the entire interaction trajectory of LLM agents. It leverages a sequence of states, actions, and rewards holistically rather than as independent elements. Key to this approach is maximizing expected trajectory rewards via a Markov Decision Process (MDP) where S,A,P respectively denote state spaces, action spaces, and transition dynamics.
The architecture generates actions based on reasoning (> tags in output), reflecting an agent's deliberative processes before deciding on actions. This thinking process is critical in multi-turn environments where policy updates are informed by normalized accumulated rewards.
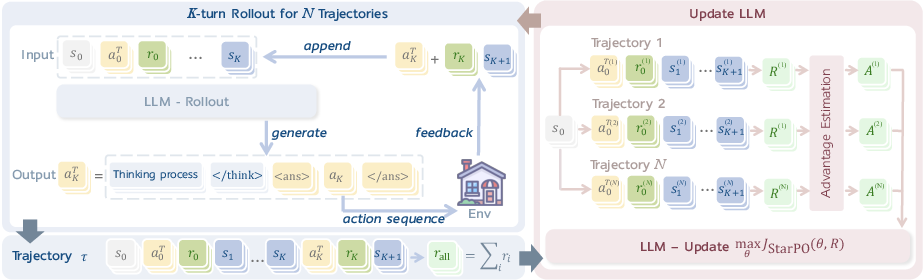
Figure 1: The State-Thinking-Actions-Reward Policy Optimization (StarPO) framework. LLM generates reasoning-guided actions for multi-turn interactions with environments and accumulates trajectory-level rewards, normalized and used to update the LLM policy.
The RAGEN System
RAGEN integrates StarPO into a modular system facilitating the evaluation of agent training dynamics. The three selected minimalistic environments—Bi-Arm Bandits, Sokoban, and Frozen Lake—serve as testbeds to identify multi-turn reasoning emergence and training stability. The system supports structured rollouts and customizable rewards, promoting extensive experimentation in agent RL training.
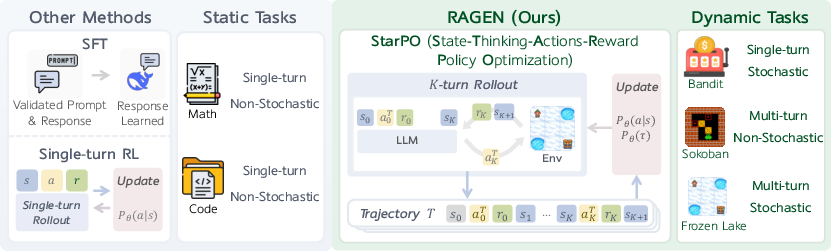
Figure 2: Previous methods focus on non-interactive tasks such as math or code generation. RAGEN implements StarPO, a general agent RL framework that supports multi-turn rollouts, trajectory-level reward assignment, and policy updates, on agent tasks requiring multi-turn stochastic interaction.
Training and Optimization Insights
Collapse Phenomena and Early Warnings
Performance evaluations of StarPO variants reveal typical instabilities such as the "Echo Trap," where models collapse into deterministic output patterns over time, losing their reasoning capacity. Identifying early collapse indicators, such as reward standard deviation and policy entropy changes, is crucial to preempting failure.
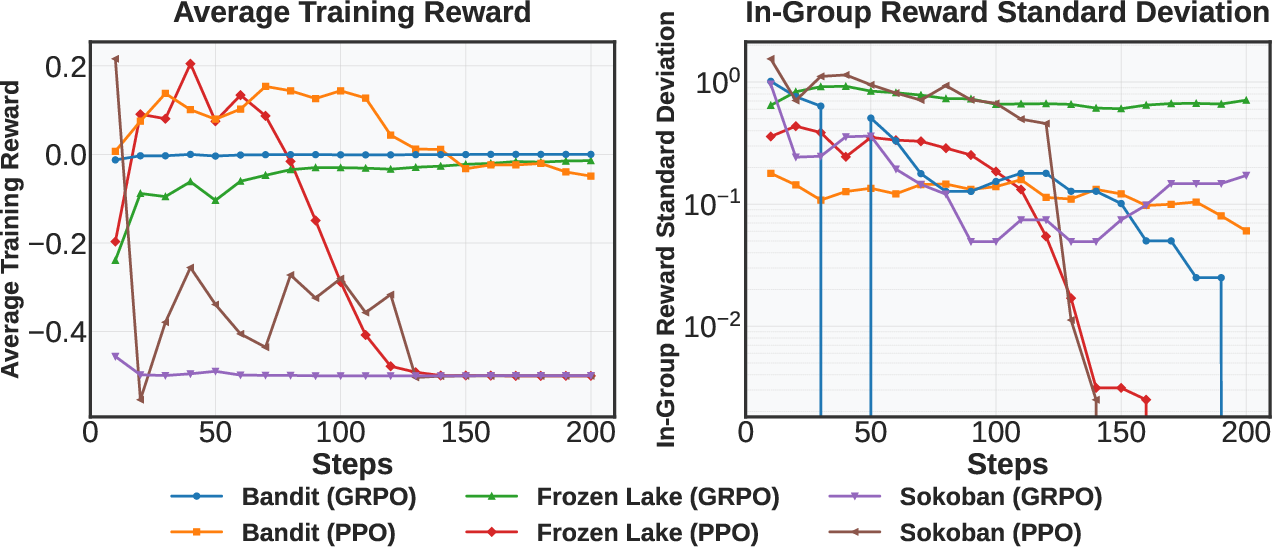

Figure 3: Collapse indicators and early warning signals in multi-turn RL. Reward standard deviation and entropy (right-side plots) drop early, often before reward degrades, serving as early warning signals. Reward mean and gradient norm (left-side plots) reflect collapse directly—plateaus and spikes confirm performance and training instability.
Enhancements in StarPO-S
StarPO-S incorporates variance-based trajectory filtering, redundancy reduction through asymmetric clipping, and KL constraint relaxation to stabilize learning. These adjustments enable the PPO variant within StarPO to maintain training stability longer than GRPO under extended interaction scenarios.

Figure 4: Effect of uncertainty-based filtering on multi-turn RL stability. Filtering out low-variance trajectories reduces collapse risk and improves success rate. On PPO variants, collapse is largely mitigated when more than half of the trajectories are filtered.
Rollout Quality and Agent Generalization
The study underscores the significance of high-quality rollouts formed by diverse, frequent, and well-structured interactions. Factors such as task diversity, maximum action budgeting, and frequent trajectory reevaluation (Online-k) are pivotal to achieving robust generalization across distinct problem domains.
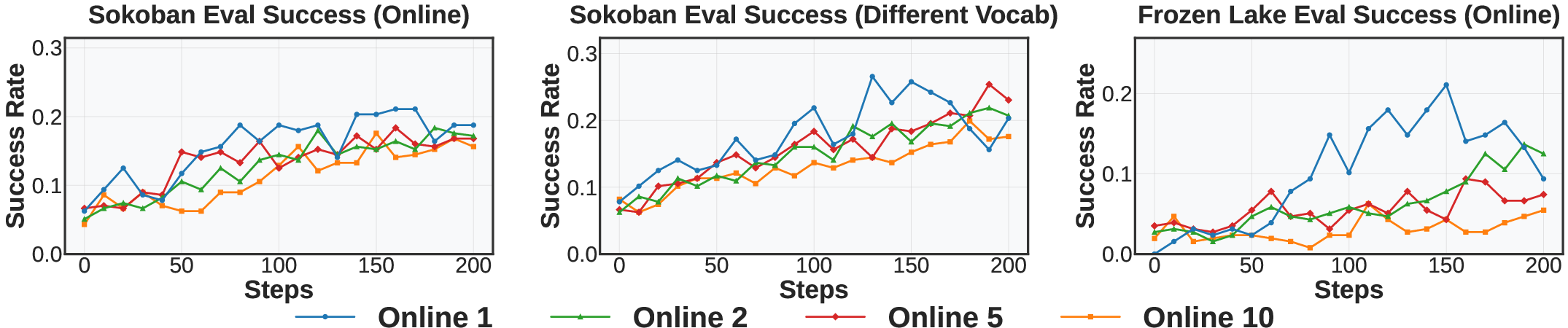
Figure 5: Performance under different rollout frequencies (Online-k). We vary the rollout reuse factor k, where each rollout batch is used for k consecutive policy updates while keeping the update batch size fixed. Lower values (e.g., Online-1) correspond to more frequent rollout collection. Fresher rollouts lead to faster convergence and stronger generalization across tasks by better aligning data with the current policy.
Discussion and Future Directions
The ability of LLMs to autonomously evolve and adapt through multi-turn interactions stands to transform their utility in cognitive tasks necessitating sustained reasoning and dynamic adaptation. However, without meticulous design in reward signaling for reasoning processes, LLM agents may trend towards superficial behavior patterns.
Further enhancements could explore fine-grained reward systems that align intermediate reasoning steps with desired outcomes. These could ensure that models do not simply mimic effective behaviors but develop deeper, reproducible cognitive frameworks adaptable to more complex, real-world applications.
Conclusion
RAGEN and its StarPO framework contribute significantly towards understanding and harnessing reinforcement learning paradigms for training stable, reasoning-capable AI agents. The insights gained alleviate critical limitations in multi-turn RL, emphasizing the design complexities essential for achieving robust, reasoning-fueled agent autonomy. As we advance, integrating broader modality contexts and refining these frameworks will ensure scalable, dynamic, and deeply interactive AI systems.