- The paper presents BabyBabelLM, a multilingual benchmark that leverages child-directed and educational data across 45 languages using tier-based stratification.
- It employs diverse sources, including child-oriented texts and curated subtitles, and evaluates models on both formal syntactic benchmarks and reasoning tasks.
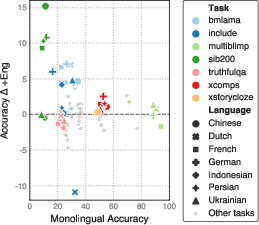
- The findings reveal that bilingual input enhances performance on knowledge tasks while highlighting data scarcity challenges for acquiring full functional competence.
Multilingual Modeling with BabyBabelLM: A Benchmark for Developmentally Plausible Language Data
Motivation and Scope
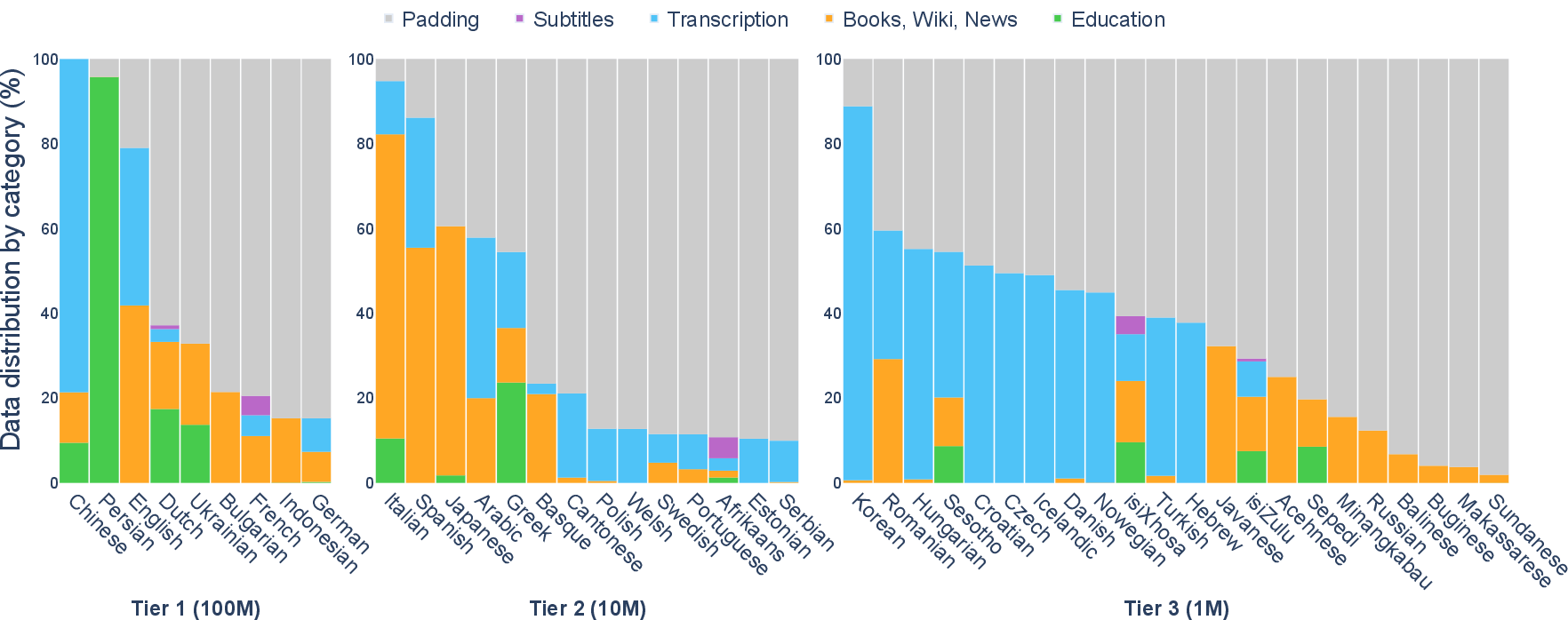
BabyBabelLM addresses a major limitation in contemporary language modeling: the extreme mismatch between the data and learning conditions for human language development and those for large-scale LMs. While humans acquire native language competence with less than 100M words, state-of-the-art LMs rely on trillions of tokens, prioritizing scale over data efficiency or developmental realism. Building on the BabyLM Challenge’s push for cognitively plausible, sample-efficient models in English, this work generalizes the paradigm to a cross-linguistic setting, releasing a suite of developmentally plausible datasets, models, and evaluation protocols for 45 languages spanning multiple families, scripts, and morphological profiles.
Dataset Construction and Design Principles
Central to BabyBabelLM is a commitment to developmental plausibility: the aim is to model the early linguistic environment that human learners experience, constrained by practical and ethical dataset considerations.
The evaluation suite is carefully constructed to test both formal linguistic competence (syntactic, morphological, grammatical generalizations) and functional competence (world knowledge, reasoning, reading comprehension) in a multilingual context. Evaluation resources include:
- Linguistic Minimal Pair Benchmarks: Language- and phenomenon-specific datasets (MonoBLiMP, MultiBLiMP, language-specific BLiMPs for German, Japanese, Turkish, etc.) allow zero-shot evaluation of syntax and agreement phenomena.
- General Knowledge and Reasoning: Tasks such as Belebele, Global-MMLU, INCLUDE, and domain-specific benchmarks (ARC, XNLI, SIB-200, etc.) measure both memorization and reasoning under fine-tuned and zero-shot regimes.
Evaluations are performed with standard harnesses (e.g., EleutherAI’s LM Evaluation Harness), reporting both direct (zero-shot) and finetuned (few-shot, when necessary) accuracy, and taking care to avoid contamination or in-context learning effects outside the scope of the data scale.
Experimental Results and Model Comparisons
Baselines and Training
Monolingual, bilingual (language + English), and multilingual (all languages) models are trained using the GoldFish configuration—a lightweight GPT-2 architecture (4–12 layers, BPE, 8k–32k vocab), yielding monolingual models of 17M parameters, and a multilingual model of 111M parameters. GPT-BERT models are also evaluated but consistently underperform the GPT-2 baselines in this paradigm (see Figure 2).
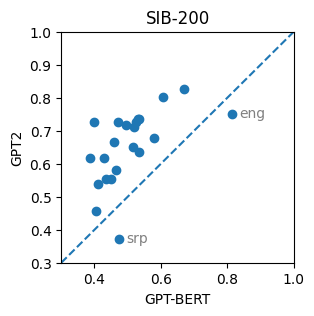
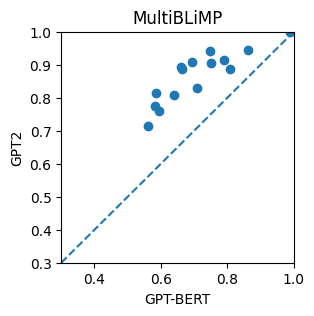
Figure 2: GPT-2 and GPT-BERT accuracy scores on SIB-200 and MultiBLiMP.
Core Findings
1. Syntactic Generalization:
- Tier 1 (100M token) models obtain high accuracy on formal linguistic benchmarks (MultiBLiMP mean >80%, with best cases approaching or exceeding human-like disambiguation performance); performance drops off with lower tiers, especially for languages without sufficient CDS or educational data.
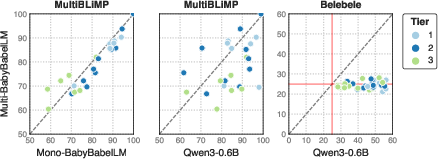
- The monolingual models generally outperform the multilingual one on linguistic minimal pair benchmarks—except for the most data-scarce languages, where cross-lingual transfer may compensate for limited monolingual data.
2. Functional Tasks:
3. Bilingual Training Advantage:
Theoretical and Practical Implications
- Modeling Human Acquisition: The resource enables controlled, cross-linguistic evaluation of the relationship between the linguistic environment (both its size and type) and learnability, allowing researchers to probe the validity of typologically- and input-based theories of language acquisition at scale and across languages [stoll2020, frank2021variability, bunceck2025construction].
- Typological Coverage and Generalization: The observed performance differences across tiers and linguistic families reinforce the utility of byte-premium scaling and resource stratification, while highlighting the critical impact of CDS and educational data on syntactic learnability [arnett2024bit, padovani2025childdirectedlanguagedoesconsistently].
- Limits of Small-Data Pretraining: The persistent gap between BabyBabelLM-scale models and open large models (e.g., Qwen) on real-world functional benchmarks demonstrates that current architectures—even when sample-efficient—remain severely limited in acquiring certain world knowledge and reasoning capabilities without massive data exposure or explicit multimodal grounding.
- Resource and Benchmark Development: By providing an extendable data pipeline and evaluation suite, BabyBabelLM lowers the barrier to principled cross-linguistic modeling and should enable systematic study of tokenization, script differences, and bi/multilingualism effects [hwang2025dynamic, rust2023language, goriely-buttery-2025-ipa].
- Multimodal and Interactive Extensions: The release sets the stage for more developmentally plausible multimodal pretraining and interactive RL/flavor interventions, where learning signals resemble those available to children (e.g., communicative success, social feedback) rather than only n-gram statistical regularities [zhuang2024lexiconlevel, long2024babyview, stopler2025developmentally].
Future Directions and Open Questions
BabyBabelLM motivates and enables a set of fundamental research directions:
- Comparative Language Acquisition Trajectories: Do LMs trained on diverse languages recapitulate cross-linguistic variation in acquisition trajectories and emergent representational differences?
- Bilingualism/Critical Period Replication: Can bilingual or curricula models replicate classical critical period and transfer effects? Can cross-script and typological boundaries be bridged with tokenization-agnostic or character/phoneme-level modeling [bunzeck2025small, goriely2025babylms]?
- Evaluation Resource Scarcity: A clear bottleneck is the breadth and balance of cross-linguistic evaluations. Expanding typologically diverse benchmarks is necessary to systematically test claims about universality or specificity of LM learning patterns.
- Tokenization and Preprocessing: Tokenization mismatches remain a confound for many languages and for equitable evaluation; further work is warranted both on tokenizer design and on explicitly tokenization-free models (e.g., ByT5 [xue2022byt5], CANINE [clark2022canine]).
Conclusion
By releasing developmentally plausible datasets, models, and a multilingual evaluation suite, BabyBabelLM advances the computational study of language learning as it occurs in humans, but at scale and under explicit experimental control. The resource enables rigorous, reproducible, and typologically inclusive investigation into the mechanisms and limits of data-driven language learning. It underscores persisting gaps in functional competence under sample-efficient learning and motivates a research agenda on data, resource, and modality balancing grounded in both cognitive science and NLP.
BabyBabelLM is a living resource that, by design, invites community expansion and collaboration to push towards more inclusive and cognitively realistic models and benchmarks.
Reference: "BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data" (2510.10159)