- The paper demonstrates innovative sample-efficient pretraining methods using developmentally plausible corpora inspired by human language acquisition.
- Methodological innovations include curriculum learning, objective modifications, and multimodal data integration across varied track sizes.
- Empirical results highlight the significant role of training FLOPs and model architecture, while exposing gaps in multimodal performance.
Findings of the Second & BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Introduction
The paper on the second BabyLM Challenge addresses the pressing issue of data efficiency in LLM training. By drawing inspiration from human language acquisition, which achieves fluency with far fewer words compared to artificial neural network-based models, BabyLM seeks to close the efficiency gap. Artificial models require training on orders of magnitude more words than humans do by adolescence. The challenge aims to identify methods to optimize model training on limited datasets, emphasizing developmentally plausible language corpora. This year's challenge introduced improved text corpora and a novel vision-and-language corpus to probe grounded and cognitively inspired language modeling approaches.
Competition Details
The competition divided into three tracks: a 10M-word text-only track, a 100M-word text-only track, and a 100M-word multimodal text-image track. Each submission was evaluated using tasks focusing on various linguistic competencies, including grammaticality, question answering, pragmatic abilities, and grounding. Notably, a hybrid causal-masked LLM emerged superior across the submissions, though the multimodal submissions failed to surpass baseline performance. The analysis highlighted a strong correlation between training FLOPs and performance across tasks, alongside the contribution of training data, objectives, and architecture.
Dataset and Methodological Innovations
Participants were allowed to bring their own datasets, offering flexibility and encouraging innovation in data preprocessing. This departure from the fixed dataset constraint of the previous year resulted in several novel approaches in data structuring, including a multimodal dataset combining text and visual data reflective of child language acquisition contexts. The Block design focused on improving the proportions of child-oriented transcribed speech and written data, eliminating non-child-level inputs to refine the dataset quality.
Participants' methodological approaches involved curriculum learning, training objective modifications, and knowledge distillation, among others. Architecture alongside training objective was pivotal in high-performing models, with submissions particularly exploiting sequence likelihood methods conditioned through multimodal inputs. The challenge catalyzed broader engagement with language modeling beyond industry labs, culminating in diverse geographic participation and collaborative innovation.
Competition Results
The results depicted in Figure 1 reveal the competitive performance landscape across submission tracks, showing the multimodal models lagging in comparison to human scores on visual tasks. Stateless innovations and data preprocessing led to varied outcomes across the text-only tracks, reaffirming the significance of fine-tuning model architectures and training data strategies for improved performance.
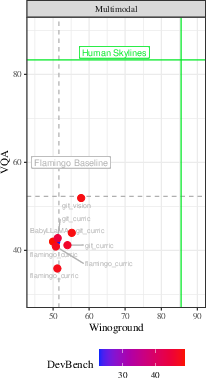
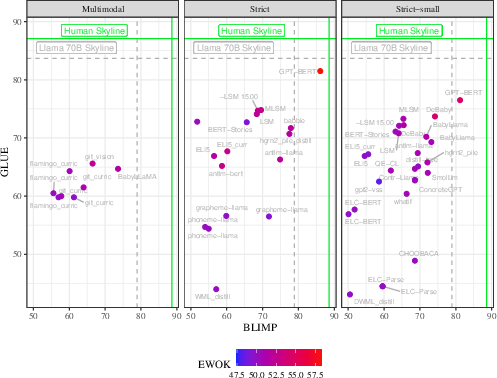
Figure 1: Overall results: At left, multimodal models on multimodal tasks; at right, all models on text tasks. N.B. Human scores for multimodal evals differ somewhat from how we evaluate our models.
In Figure 2, training FLOPs is positively associated with model performance, underscoring computational spending as still pivotal.
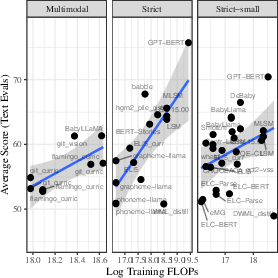
Figure 2: The relationship between training FLOPs and final score.
Scoring aggregates by backbone architecture, presented in Figure 3, reflect mixed outcomes across submissions with certain architectures outperforming others consistently.
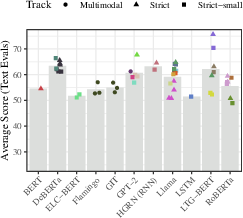
Figure 3: Scores aggregated by backbone architecture. Colors indicate different submissions.
Discussion
The findings from this year's BabyLM Challenge have critical implications for the scientific study of language and practical applications in AI and NLP. Successful submissions exhibited innovative architectures and modifications to training paradigms, heralding strategies for future research directions. Challenges remain in multimodal modeling, spotlighting a discernible gap in harnessing visual data effectively for grounded language learning. This paper illuminates avenues for further exploration in computational models that can better mimic developmental language acquisition.
Novel contributions emerged, including phoneme-aware tokenization's minimal effect on general language tasks, yet enhancing phonological flexibility, and synthetic datasets crafted through GPT-4 prompted variation sets displaying potential for efficient training. Highlighted approaches include RNN applications and multi-objective training strategies, which show promising results compared to established baseline models, offering adaptability and innovation in constrained data scenarios.
Conclusion
The BabyLM Challenge demonstrates considerable scope and innovation potential in data-efficient language modeling, advocating further exploration in expanding modalities while refining current strategies. A continued emphasis on community engagement and diverse methodological innovations can progressively align artificial LLMs more closely with human efficiency and adaptability. By tackling these fundamental objectives, the BabyLM initiative is poised to advance the frontier in cognitive computation and linguistics research.
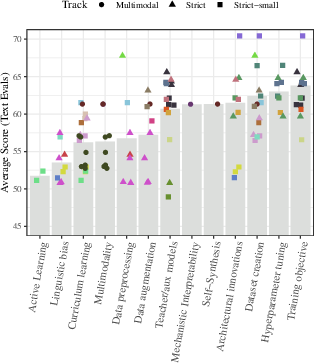
Figure 4: Scores on the BabyLM challenge, aggregated by approach. Colors indicate different submissions, which are plotted twice if they use more than one approach.


