- The paper reveals that over 90% of reflections simply confirm the initial candidate answers without significant corrective impact.
- Methodologically, an LLM-based extractor was applied across eight models and five benchmarks to analyze candidate answer positions and token distributions.
- The study introduces an early-stopping method that cuts token usage by 24.5% with only a 2.9% accuracy drop, enhancing inference efficiency.
First Try Matters: Revisiting the Role of Reflection in Reasoning Models
Introduction
The study presents a comprehensive analysis of the role of reflection in reasoning models, particularly focusing on LLMs and their reasoning capabilities. The research evaluates the impact of reflections within the context of refining candidate answers during model reasoning processes. While traditionally reflections are considered crucial for improving model accuracy, the investigation reveals that reflections primarily serve a confirmatory role rather than enhancing the initial correctness of answers.
Reflection Analysis in Reasoning Models
The study employs an LLM-based extractor to discern and analyze reflection patterns within reasoning rollouts across eight models and five mathematical benchmarks. This is achieved by identifying candidate answers during the reasoning process and delineating between confirmatory and corrective reflections.

Figure 1: Illustration of a long CoT and the extraction result of candidate answers.
Analysis uncovers that over 90% of reflections are confirmatory, constantly reiterating the initial answer without improving it. This trend persists across various models and datasets, challenging the assumption that reflections significantly refine model accuracy. Furthermore, the investigation highlights a strong correlation between the length of a reasoning rollout and its accuracy, yet reflections constitute only marginal improvements beyond the initial candidate answer.
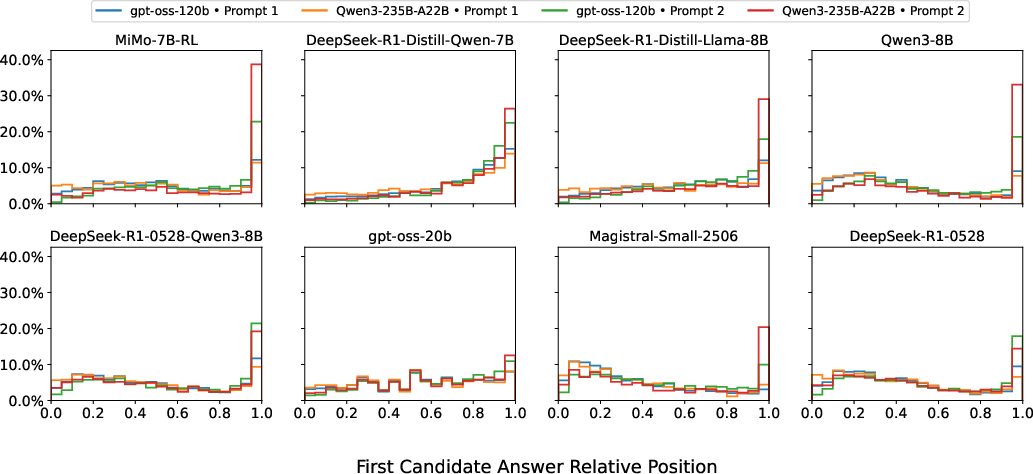
Figure 2: Distribution of first candidate answer positions across different LLMs and prompts. The x-axis denotes the relative position of the first candidate answer (line index divided by total lines), and the y-axis shows the proportion of rollouts in each bin.
Role of Reflection in Training
The paper explores the influence of reflection quantity on training outcomes by curating supervised fine-tuning datasets with varying reflection steps. It is observed that training with reflection-rich data leads to improved initial answer correctness instead of enhancing reflection-derived corrections. This trend suggests that reflection-driven training datasets enrich problem-solving paths, thus bolstering model performance.
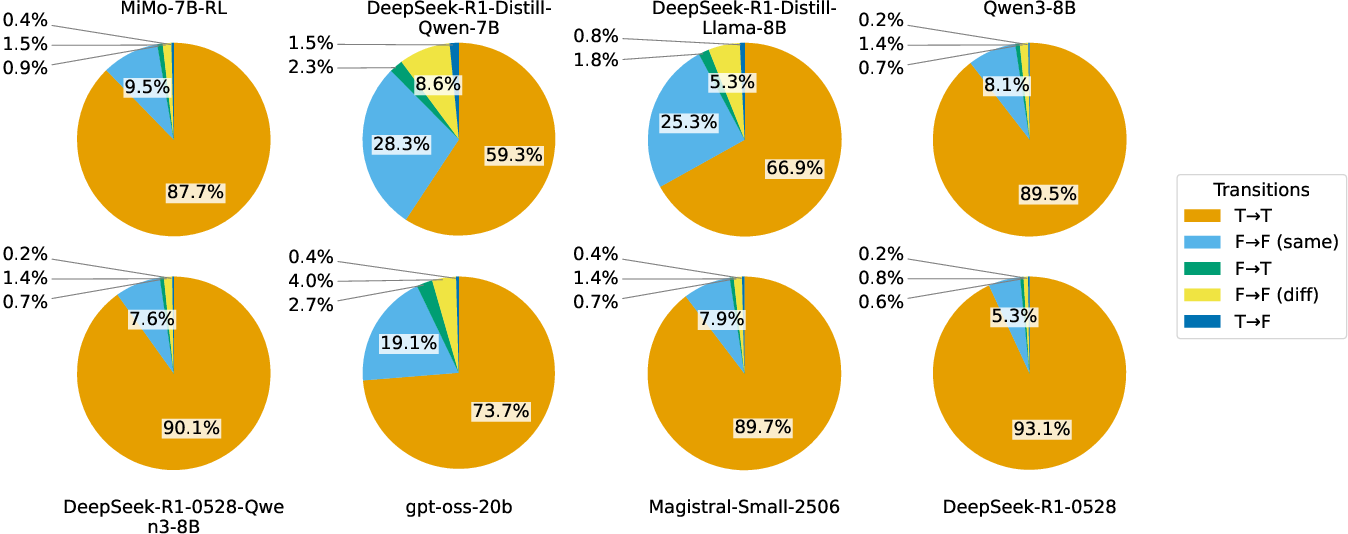
Figure 3: Reflections type statistics of long CoTs of different models. Long CoTs are collected on various datasets.
Efficient Reasoning Through Early Stopping
In an effort to optimize inference efficiency, the paper introduces a novel early-stopping method, which reduces unnecessary reflections when a plausible candidate answer is detected. This approach achieves a 24.5% reduction in reasoning tokens with a negligible 2.9% decline in accuracy, demonstrating a practical trade-off between token usage and performance.
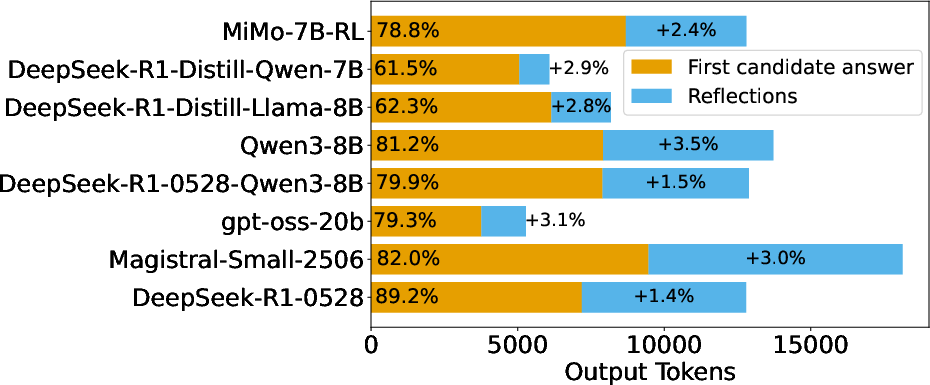
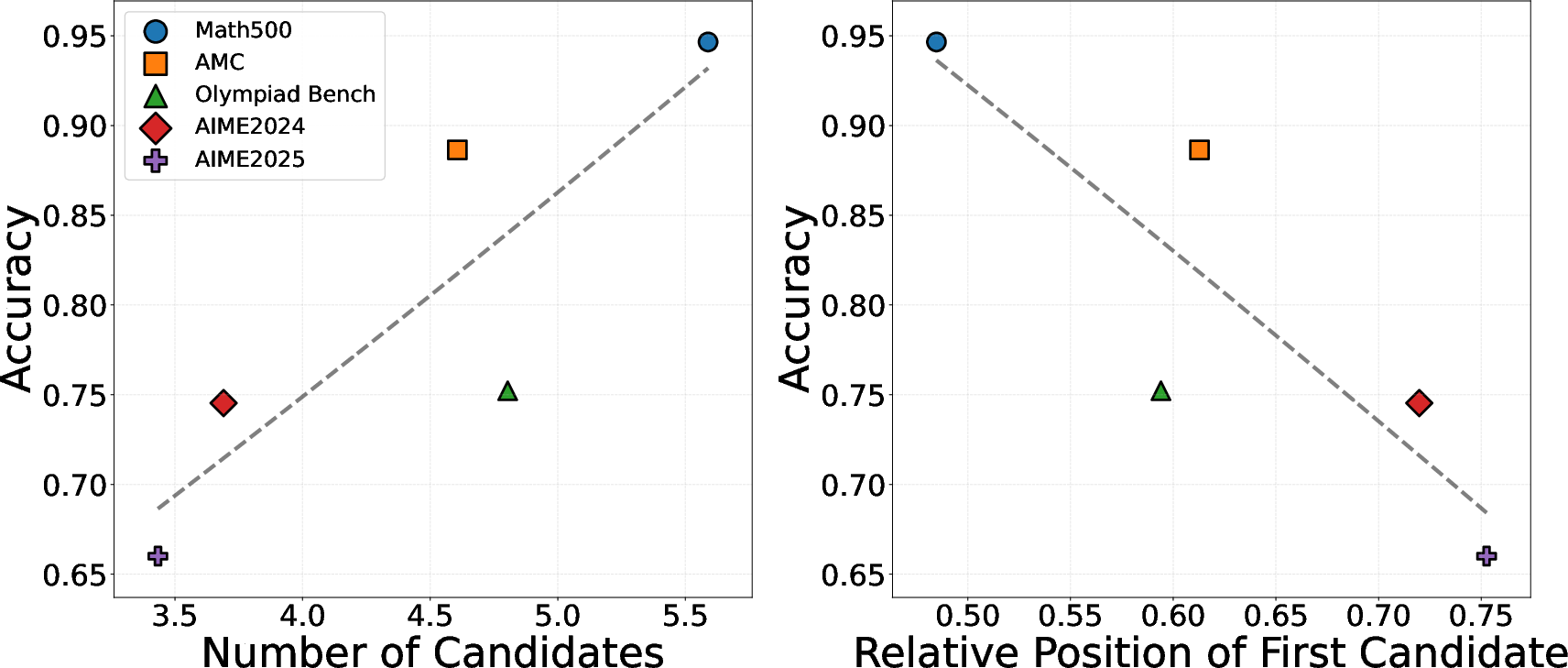
Figure 4: Breakdown of long CoTs showing token count up to the first candidate answer alongside subsequent reflections.
Implementation Considerations
Implementing these insights requires strategic adjustments to both training data design and inference strategies. Incorporating diverse and rich reflection-based training corpora without excessive token usage is key to enhancing model generalization. On the inference side, leveraging early-stopping mechanisms offers computational efficiency while maintaining performance integrity.
Conclusion
The findings underscore the limited corrective impact of reflections in reasoning models and propose efficient strategies for optimizing reasoning processes. Future research could explore dynamic reflection adjustments based on problem complexity to further optimize LLM reasoning capabilities.
In summary, this research offers a novel perspective on the minimal role of reflections in improving model accuracy, suggesting that the initial candidate answer predominantly determines performance. The proposed early-stopping technique provides an effective solution for enhancing inference efficiency without substantial accuracy loss.

