- The paper introduces a novel method where LLMs generate self-reflections upon failure and retry tasks to achieve improved accuracy.
- The Reflect, Retry, Reward framework employs GRPO to reward effective self-reflections, enabling smaller models to outperform larger counterparts.
- Experimental results show significant gains, with up to 16% improvement on complex benchmarks and enhanced robustness against catastrophic forgetting.
Self-Improving LLMs via Reinforcement Learning
The paper "Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning" (2505.24726) introduces a novel method for enhancing LLM performance through self-reflection and RL. The approach incentivizes models to generate improved self-reflections when initial answers are incorrect. This allows the model to improve at complex, verifiable tasks, even when synthetic data generation is infeasible and only binary feedback is available. The framework operates in two stages: first, the model generates a self-reflective commentary upon failing a task; second, it attempts the task again, using the self-reflection. Success on the second attempt rewards the tokens generated during self-reflection via GRPO. Experimental results demonstrate substantial performance gains across various model architectures, notably with smaller fine-tuned models outperforming larger models.
Background and Motivation
LLMs have demonstrated capabilities across NLP tasks, mathematics, coding, and reasoning (Zhao et al., 2023, Jiang et al., 2024, Tafasca et al., 2023). However, models still exhibit limitations, and success on one task does not guarantee success on similar tasks [23.starsem-1.22, 25]. Directly addressing this involves retraining or fine-tuning on specific failure data, which may be unavailable, or generating synthetic training data, which may be unreliable [24]. An alternative is to prompt models to explain their reasoning or self-reflect on failures, akin to the CoT approach [22]. This paper explores how LLMs can learn to generate effective self-reflections to improve performance on downstream tasks, independent of task-specific data.
Methodology: Reflect, Retry, Reward
The Reflect, Retry, Reward methodology involves prompting a model to complete a task (Figure 1). If successful, no further action is taken. If the model fails, it generates a self-reflection on potential errors. A validator is required to automatically evaluate response success or failure. After self-reflection, the model makes a second attempt, using the self-reflection in its context. If this second attempt fails, no action is taken. However, if the second attempt succeeds, GRPO is used to reward the tokens generated during self-reflection, encouraging more effective future reflections.
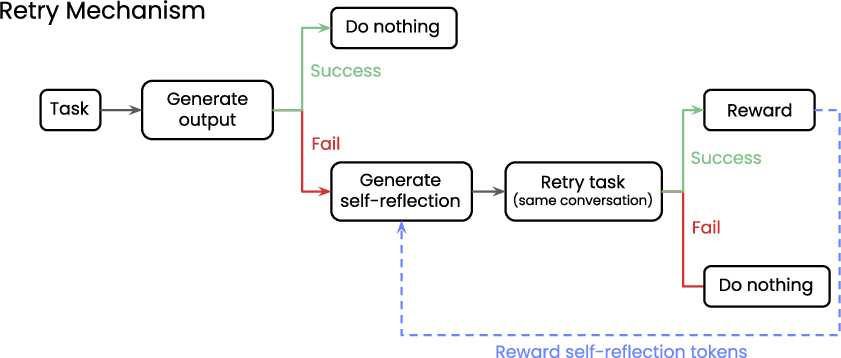
Figure 1: A depiction of the Reflect, Retry, Reward mechanism, highlighting the iterative process of task completion, reflection upon failure, and subsequent retry with improved self-reflection.
Experimental Setup
The authors conducted experiments on function calling, using the APIGen dataset [24], and on solving math equations, using the Countdown dataset [(Pan et al., 21 Apr 2025), tinyzero]. The APIGen dataset consists of 60,000 high-quality function calls with user queries, tool lists, and correctly formatted function calls. The Countdown dataset comprises 450k lists of numbers and target numbers, requiring the application of arithmetic operations to match the target. Models were evaluated based on the accuracy of tool selection, parameter generation, and equation solving. The study evaluated Qwen2 (1.5B/7B Instruct) (Yang et al., 2024), Llama3.1 (8B Instruct) (Grattafiori et al., 2024), Phi3.5-mini Instruct (Abdin et al., 2024), and Writer's Palmyra X4, with larger models serving as baselines. Training was performed on datasets of failures to enhance efficiency and focus on learning from errors. The multi-step GRPO algorithm, implemented using the TRL framework [22], was used to reward self-reflection tokens.
Experimental Results and Analysis
The experimental results demonstrate significant performance improvements on both the APIGen and Countdown datasets.
APIGen Results
Model size correlated with initial performance, and a second attempt with self-reflection increased performance by 4.5%. GRPO training further improved results, with models outperforming two-attempt vanilla models after a single attempt. Self-reflection after training led to an additional 4.7% performance increase. Notably, the Qwen-2-7B model, after GRPO training, outperformed the larger Qwen-2-72B model, even with two attempts for both.
Countdown Results
Initial performance was generally lower, particularly for vanilla Llama models. Self-reflection improved performance, with gains of 5.3% and 8.6% before and after GRPO training, respectively. The increased gains are attributed to the lower baseline performance, allowing greater learning opportunities. These results reinforce the benefits of self-reflection and demonstrate that optimizing self-reflection via GRPO enhances performance further.

Figure 2: A visualization comparing self-reflections generated by vanilla models versus GRPO fine-tuned models, illustrating the improved conciseness and clarity of the latter.
Qualitative Analysis of Self-Reflections
Qualitative analysis revealed that vanilla self-reflections tend to be lengthy and verbose, while GRPO-trained models generate more concise and optimized reflections (Figure 2). This finding contrasts with CoT outputs, which benefit from verbosity, raising questions about optimal output strategies.
Catastrophic Forgetting
The study assessed catastrophic forgetting by evaluating models on benchmarks such as MMLU-Pro (Wang et al., 2024), GSM8K (Cobbe et al., 2021), HellaSwag (Zellers et al., 2019), and MATH [hendrycksmath2021]. Performance remained stable, with minimal degradation, indicating robustness to catastrophic forgetting.
Conclusion
The study demonstrates that training models to improve self-reflection, rather than specific tasks, significantly enhances LLM performance. The approach relies on a validator to detect response correctness, making it suitable for tasks with easily verifiable responses. Experiments on APIGen and Countdown datasets showed average performance improvements of 9.0% and 16.0%, respectively. Smaller, self-reflection trained models outperformed larger, untrained models. The models exhibited better performance, even without needing self-reflection, suggesting improved reasoning skills. Future work will explore the generalization of self-reflection training across different tasks.
Limitations
Defining a binary success/fail validator may not always be straightforward. The model must possess a basic ability to perform the task, self-reflect, and learn for self-correction to work effectively.