- The paper introduces Flow Policy Optimization (FPO), a novel RL algorithm that integrates flow-based generative models with policy gradients using a surrogate likelihood ratio from conditional flow matching.
- FPO effectively models multimodal action distributions in high-dimensional tasks, outperforming traditional Gaussian policies in environments like GridWorld, MuJoCo, and humanoid control.
- Grounded in ELBO theory, FPO employs Monte Carlo estimates of the CFM loss to improve policy expressivity, though it requires careful tuning due to increased computational demands.
Flow Matching Policy Gradients: Integrating Flow-Based Generative Models with Policy Optimization
Introduction
The paper "Flow Matching Policy Gradients" (FPO) introduces a novel approach for integrating flow-based generative models, particularly diffusion models, into the policy gradient framework for reinforcement learning (RL). The core contribution is Flow Policy Optimization (FPO), an on-policy RL algorithm that leverages the conditional flow matching (CFM) objective to optimize policies represented as flow models. FPO is designed to sidestep the computational intractability of exact likelihood estimation in flow-based models, instead using a surrogate loss that is compatible with standard policy gradient methods such as PPO. This enables the training of expressive, multimodal policies in high-dimensional continuous control tasks, with empirical results demonstrating superior performance over traditional Gaussian policies, especially in under-conditioned or multimodal environments.
Flow Policy Optimization: Methodology
FPO reframes policy optimization by replacing the standard log-likelihood ratio in PPO with a ratio derived from the CFM loss. The CFM objective, originally developed for generative modeling, is adapted to RL by weighting the flow matching loss with the advantage function, thus steering the probability flow toward high-reward actions. The FPO ratio is computed as:
r^FPO(θ)=exp(L^CFM,θold(at;ot)−L^CFM,θ(at;ot))
where L^CFM,θ(at;ot) is a Monte Carlo estimate of the per-sample CFM loss. This ratio serves as a drop-in replacement for the PPO likelihood ratio, enabling the use of standard advantage estimation and trust region clipping.
The FPO algorithm is agnostic to the choice of flow or diffusion sampler, allowing for flexible integration with deterministic or stochastic sampling, and any number of integration steps during training or inference. This contrasts with prior diffusion-based RL methods that require custom MDP formulations for the denoising process, increasing credit assignment complexity and limiting sampler flexibility.
Theoretical Foundations
FPO's surrogate objective is theoretically grounded in the evidence lower bound (ELBO) framework. The CFM loss is shown to be equivalent to the negative ELBO (up to a constant), and thus minimizing the CFM loss maximizes a variational lower bound on the likelihood of high-reward actions. The FPO ratio can be interpreted as the ratio of ELBOs under the current and previous policies, decomposing into the standard likelihood ratio and an inverse KL gap correction. This ensures that FPO not only increases the modeled likelihood of advantageous actions but also tightens the approximation to the true log-likelihood.
Empirical Evaluation
Multimodal Policy Learning in GridWorld
FPO is first evaluated in a 25×25 GridWorld environment with sparse rewards and multiple optimal goals. The FPO-trained policy, parameterized as a two-layer MLP, demonstrates the ability to capture multimodal action distributions at saddle points, with sampled trajectories from the same state reaching different goals. This is visualized by the deformation of the coordinate grid during denoising steps and the diversity of sampled trajectories.

Figure 1: FPO in GridWorld demonstrates multimodal action distributions and diverse trajectories, in contrast to unimodal Gaussian policies.
Continuous Control in MuJoCo Playground
FPO is benchmarked against Gaussian PPO and DPPO (a diffusion-based PPO variant) on 10 continuous control tasks from MuJoCo Playground. FPO consistently outperforms both baselines in 8 out of 10 tasks, with higher average evaluation rewards and improved learning efficiency. Ablation studies reveal that increasing the number of Monte Carlo samples for the CFM loss improves performance, and that ϵ-MSE is preferable to u-MSE for loss computation in these domains.


Figure 2: FPO achieves higher evaluation rewards than Gaussian PPO across multiple DM Control Suite tasks.



Figure 3: Episode return curves show FPO's superior learning dynamics compared to baselines.
High-Dimensional Humanoid Control
In physics-based humanoid control tasks, FPO is evaluated under varying levels of goal conditioning (full joint, root+hands, root only). While FPO matches Gaussian PPO under full conditioning, it significantly outperforms Gaussian PPO in under-conditioned settings, achieving higher success rates, longer alive durations, and lower mean per-joint position error (MPJPE). This demonstrates FPO's robustness and expressivity in modeling complex, under-specified behaviors.
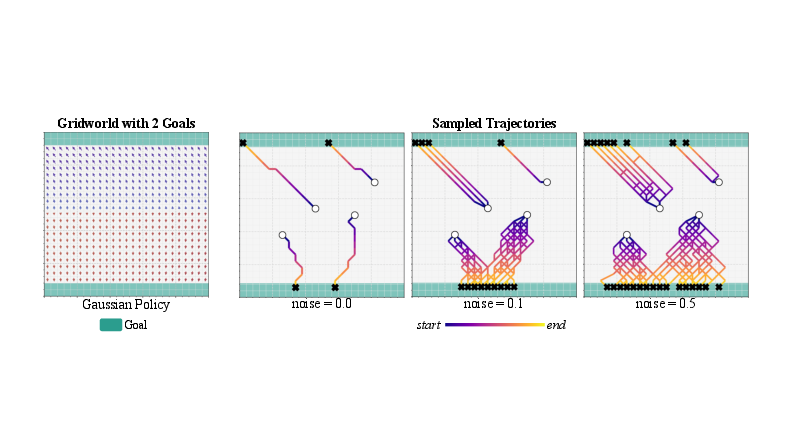
Figure 4: Gaussian policy in GridWorld lacks trajectory diversity, consistently reaching the same goal under noise perturbations.
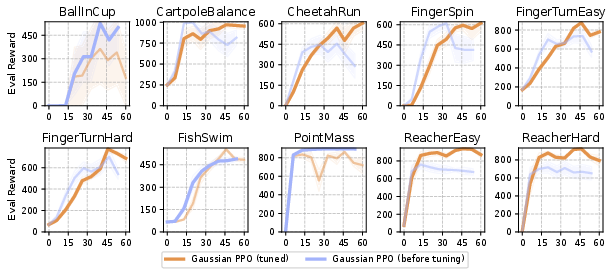
Figure 5: Hyperparameter tuning of Gaussian PPO shows limited gains compared to FPO's improvements.

Figure 6: Fine-tuning Stable Diffusion with FPO on self-generated data leads to instability, with image quality degrading under different classifier-free guidance scales.
Implementation Considerations
- Computational Requirements: Training flow-based policies is more computationally intensive than Gaussian policies due to the need for multiple denoising steps and Monte Carlo sampling. However, FPO's compatibility with standard RL infrastructure and its avoidance of explicit likelihood computation mitigate some of this overhead.
- Hyperparameter Sensitivity: Performance is sensitive to the number of Monte Carlo samples, the choice of loss function (ϵ-MSE vs. u-MSE), and the clipping parameter. Careful tuning is required for optimal results.
- Deployment Flexibility: FPO-trained policies retain the generative capabilities of flow models, allowing for flexible sampling, distillation, and fine-tuning. The method is agnostic to the choice of sampler and can be integrated with pretrained diffusion policies for downstream RL fine-tuning.
- Limitations: FPO lacks established mechanisms for adaptive learning rates and entropy regularization based on KL divergence, which are standard in Gaussian policy optimization. Fine-tuning diffusion models on their own outputs, especially in image generation, remains unstable due to compounding artifacts from classifier-free guidance and self-generated data.
Practical and Theoretical Implications
FPO bridges the gap between expressive flow-based generative models and policy gradient RL, enabling the direct optimization of multimodal, high-dimensional policies from reward signals. This has significant implications for robotics, continuous control, and any domain where modeling complex, multimodal action distributions is critical. The method's flexibility and compatibility with standard RL algorithms make it a practical choice for integrating advanced generative modeling techniques into RL pipelines.
Theoretically, FPO extends the applicability of flow matching and ELBO-based training to the RL setting, providing a principled surrogate for likelihood-based policy optimization. The approach highlights the potential for further unification of generative modeling and RL, particularly in leveraging the expressivity of modern diffusion models for decision-making tasks.
Future Directions
Potential avenues for future research include:
- Developing adaptive regularization and learning rate schedules for flow-based policies.
- Exploring off-policy variants and sample efficiency improvements.
- Stabilizing fine-tuning of diffusion models in generative tasks, particularly in image and video domains.
- Applying FPO to large-scale, pretrained diffusion policies in robotics and foundation model alignment.
Conclusion
Flow Policy Optimization provides a principled and practical framework for training flow-based generative policies via policy gradients, enabling expressive, multimodal action modeling in RL. Empirical results demonstrate its advantages over Gaussian and prior diffusion-based policies, particularly in under-conditioned and high-dimensional tasks. While computationally more demanding, FPO's flexibility and theoretical grounding position it as a valuable tool for advancing the integration of generative modeling and reinforcement learning.